
The IBM Z Telum processor is the new processor designed for mainframes. These chips are not really competitive with traditional x86 processors just because they are designed for very specific markets such as transaction processing and financial services. This is being done live, so please excuse typos.
IBM Z Telum Mainframe Processor at Hot Chips 33
The IBM Z Telum processor is designed to accelerate many of the ultra-high value workloads that are run at places like financial institutions processing credit card and banking transactions. As a result, customers are willing to pay quite a bit for not just performance, but also low latency, reliability, and security.

Like we are seeing on the x86 side, we have encrypted memory and trusted execution. This trend is reaching all of the server markets and IBM has been focused on these capabilities for some time.
New error correction and sparing where even an entire L2 cache array has an issue to drive beyond 99.99999% availability (seven 9s.) This is a 7nm Samsung chip with 22.5 billion transistors and over a 5GHz base clock. To get some sense of the achievement, IBM has a huge chip that is running at the speeds that enthusiast overclockers would be happy with, and running it reliably.
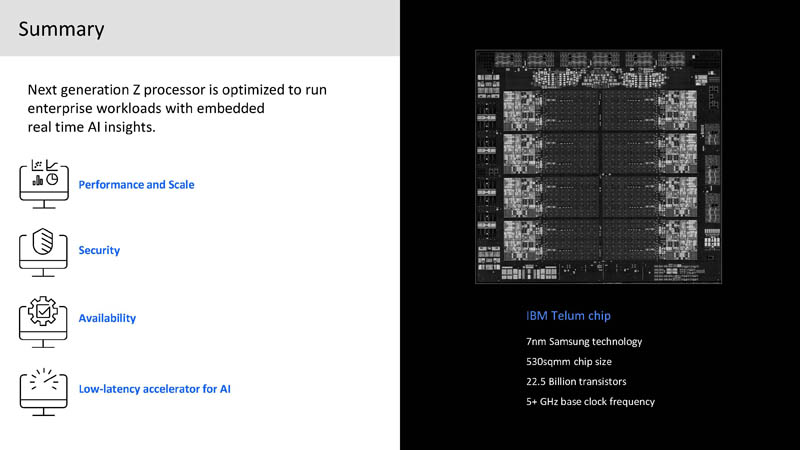
A lot of the effort is around per-core performance improvements. This core uses SMT2 and can run after. Integrated L1 and L2 branch prediction. Dynamic BTB entry reconfiguration is designed to dynamically get large amounts of branch entries. L2 cache is quadrupled versus Z15 to 32MB. Four pipelines go to the L2 to allow overlapping traffic.

Virtual L3 and L4 caches from the L2 cache. All of the L2 caches are interconnected with ring infrastructure. When a cache line is evicted, a L2 cache can evict to another L2 cache on the chip for a virtual L3 cache. It can then scale across up to 8 chips for a virtual L4 cache.

IBM Telum can scale up to 32 chips that are interconnected. The basic building blocks are modules with 1 or 2 chips. These can then be placed into a 4-socket drawer. Then four drawers can be combined.

Here is a look at a 2-chip package that has two of these 256MB cache chips for a total of 512MB. IBM is heading to the GB Onboard Era in the future.

By removing the cache chip in the drawer, and using the virtual L4 cache, fewer hops are required but that fabric and interface had to move on-chip.

The net result of the improvements is a 40% per socket performance increase.

Each IBM Z generation tends to be a big jump in capability and performance just because of the speed of the market.
IBM Z Telum AI Inference Accelerator
IBM now has an AI inference accelerator directly on the chip. This is for high performance and low latency inference. The CPU cores do not have AI accelerators in the cores. As a result, each core can access the full accelerator directly instead of only having access to the performance of the AI inference in each core. For example, on an Intel Xeon, each core only has access to the performance of the VNNI. To get more VNNI performance, more cores need to execute.

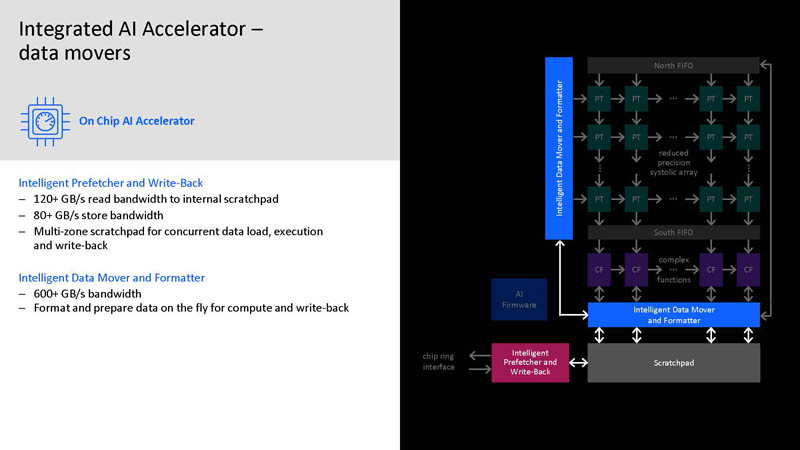
One of the important aspects here is that IBM having an AI accelerator on-chip means it does not have to go off-chip. In the mainframe industry, security is important so having all of the firmware and encryption around the processor apply to the AI accelerator is important as well.

The performance of the AI accelerator is over 6 TFLOPS or up to 200 TFLOPS in a 32-chip system.
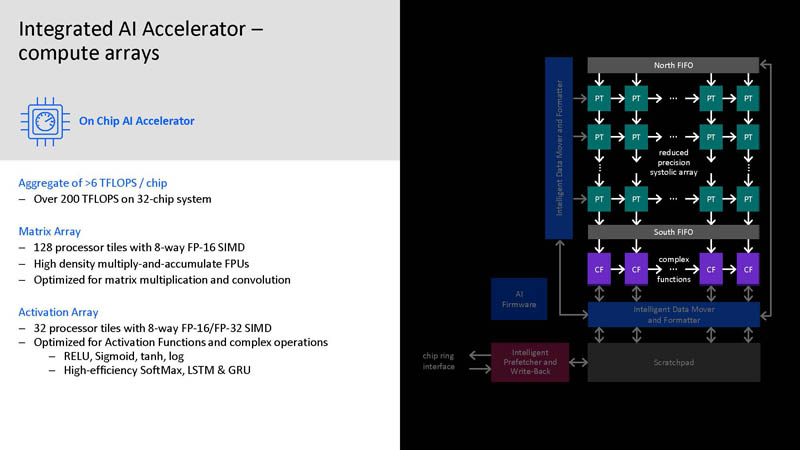
Part of this is also ensuring IBM can get enough bandwidth to the AI inference array.
IBM says one can train on NVIDIA GPUs or elsewhere. Export to ONNX as more of an open model. Then the IBM Deep Learning accelerator can be used to embed into applications on the IBM Z processor.
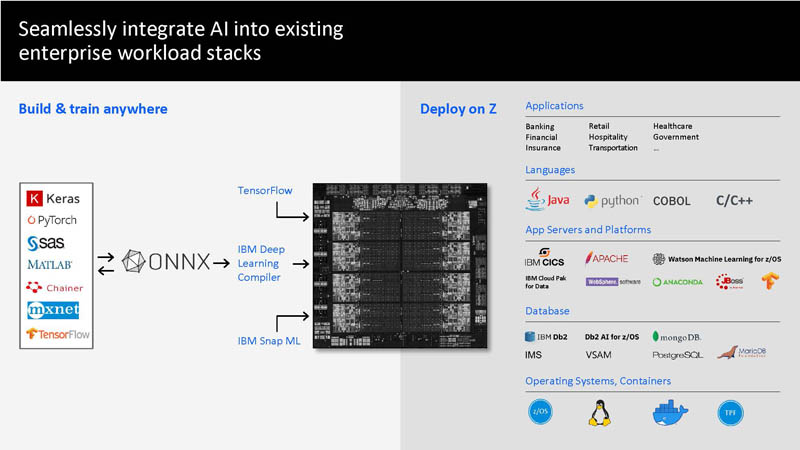
The basic idea is that AI can be embedded at scale. For example, one can do credit card fraud scoring directly on the chip at very low latency. This means real-time inference at scale so it can be embedded into transactions.
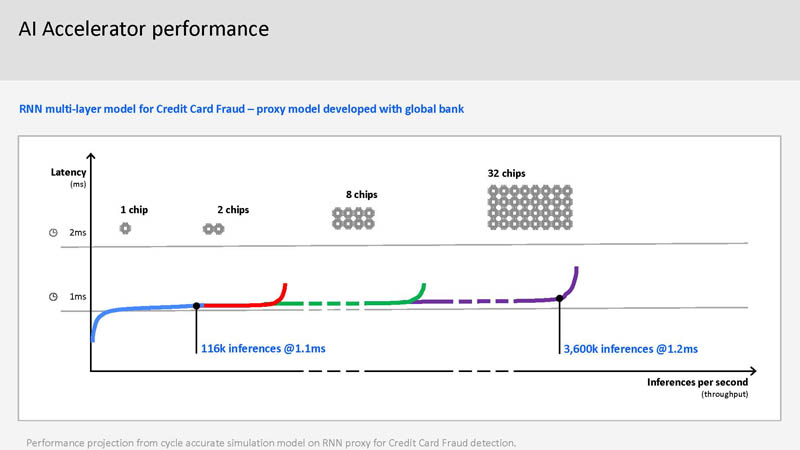
This is a key use-case for IBM Z so we can see why IBM is showcasing this as it has a huge dollar value to its customers.
Final Words
IBM also has a huge number of reliability-related capabilities so that if parts of the chips and systems fail, they continue to run. We discussed issues in cache, and basic ECC memory is a given, but IBM is able to recover from additional types of failures well beyond x86. High performance and high reliability (along with legacy code compatibility) is exactly what those keeping the financial industry running want.



{kind=link}
IBM has a Telum video available: https://www.youtube.com/watch?v=TRBgBbvYiQw
BTW: Telum means javelin in Latin.
Sure wish they made a motherboard that accepted one CPU.