Intel AMX (Advanced Matrix Extensions) with Sapphire Rapids
While we cannot share the full lscpu output, we will simply say that there are three primary Intel AMX flags in the test system: amx_bf16, amx_tile, and amx_int8. The idea of having additional matrix math instructions beyond 3rd Gen Xeon Scalable in the CPU we expect to be a differentiator compared to what AMD will offer with Genoa. Still, we are in a bit of a hard spot since we can also not show off AMD EPYC Genoa numbers. Instead, we had to use an AMD EPYC 7763 machine for ResNet-50.
As a quick refresher, Intel’s strategy with on-chip acceleration is not new. Over the past few years, Intel has been working on getting AI acceleration into frameworks like Tensorflow so that instead of spending a lot of time on software enablement, using VNNI just works.
To show some impact of AI inference acceleration using VNNI and why it matters for CPUs, we can look back to our Stop Leaving Performance on the Table with AWS EC2 M6i Instances piece from 10 months ago. The first chart is looking at the impact of transitioning from a base case using FP32 and without Intel’s AIkit integration, then using the software enablement, then switching to INT8. This is the impact of just using VNNI in low batch size inference.
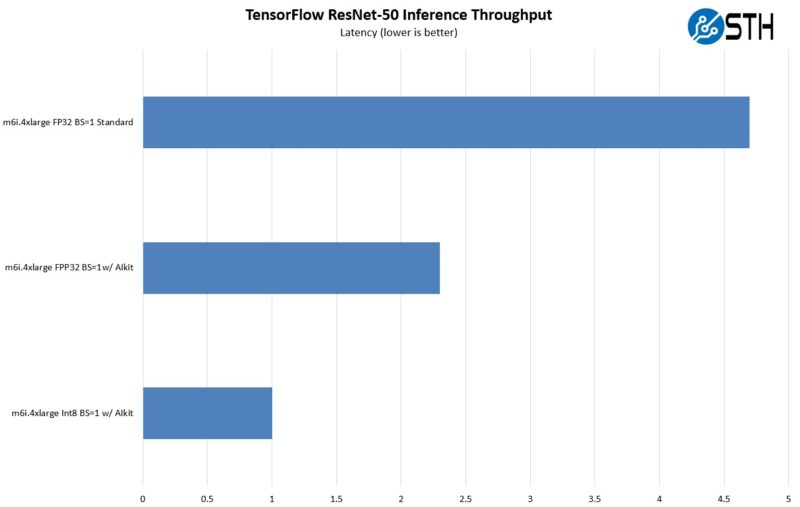
Imagine there is an application where you are doing various other work but then need to do one or a handful of AI inference tasks. This is not to take away the need for AI inference accelerators completely, but it is for lower-end inference loads.
Aside from the latency, that benefits from not having to go out over the PCIe bus, and we can also get more throughput with VNNI. Here is an example using BS=16.
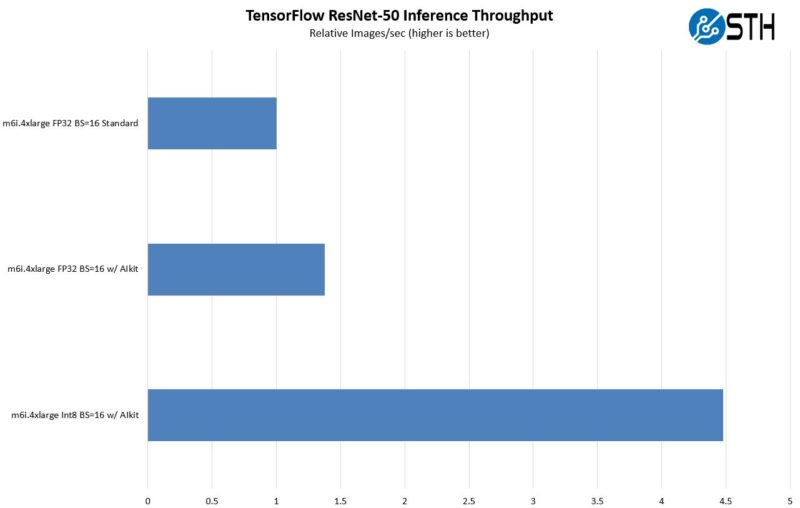
Of course, AMD’s Zen 4 has VNNI, but we cannot share Genoa numbers yet. What we will simply say is that one can expect VNNI to be the baseline. AMX is the next step.
We have numbers for AMD EPYC Milan on this one, but it felt strange since FP32 to INT8 gives a bit over 2x the performance in terms of throughput and latency, but VNNI’s INT8 is more like 3-4x. Genoa is coming out soon after all. Instead, we are just going to show what we got with Sapphire so you can compare it to what we got with Ice Lake above.
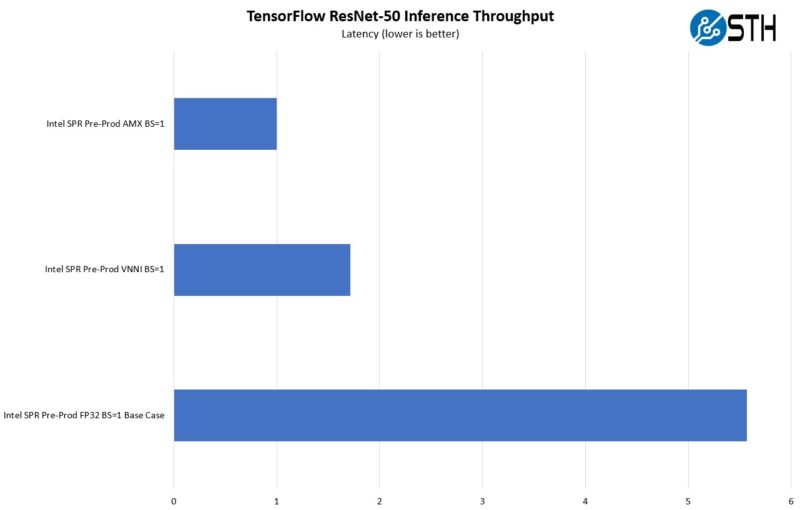
With latency, AMX actually did better than we expected, but our base case to VNNI looked a lot closer than what we saw on the AWS M6i instances.
In terms of throughput, we get a lot better performance.
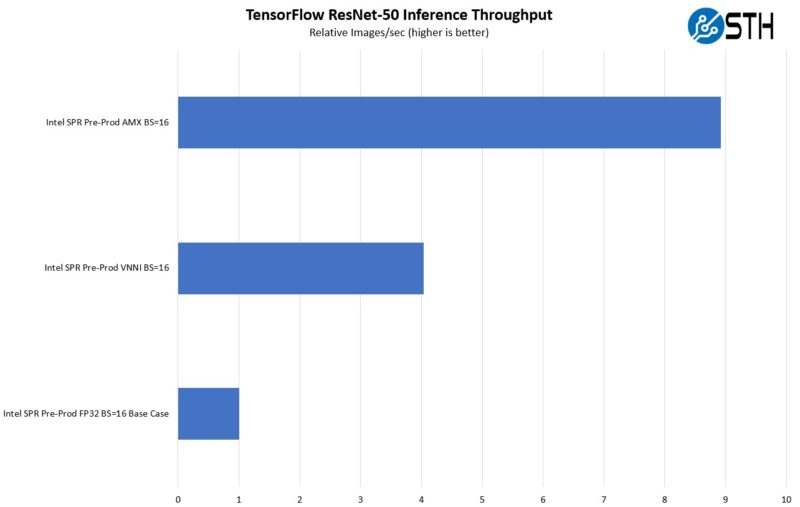
On the flip side, the max throughput of AMX is probably not what everyone is after since AMX is done on the cores, like with AVX-512. That means one is using the CPU just for AI inference, and it is probably cheaper to do it on accelerators if bulk AI acceleration is what you are after. Still, Intel would argue that at least one does not need an accelerator, but Intel sells AI inference hardware as well.
To be clear, in my discussions with AMD, this is intentional. AMD’s strategy is to allow Intel to be the first with features like VNNI and AMX. Intel does the heavy lift on the software side, then AMD brings those features into its chips and takes advantage of the more mature software ecosystem. Frankly, it feels strange showing off the AMX feature when AMD will be shipping Genoa with VNNI before AMX is out.
Next, let us get to the big one, Intel QuickAssist technology.



{kind=link}
Genoa is gonna rock Intel. Thanks for not pretending like they’re not getting AVX512 and AVXVNNI.
Incredibly insightful article STH.
Read Hot Hardware’s version: “We don’t know what any of this means really, but here’s the scripts Intel gave us, and here’s what Intel told us to run. We also don’t have AMD EPYC so who cares about competition.”
Read STH: “Here’s an in-depth look at a few storylines we have been showing you since last year, and here’s what and why you can expect the market to change.”
It’s a world of difference out there.
One thing left unmentioned is the physical impacts of acceleration. For instance, what is the die space budget for something like QAT and AVX? How are thermals impacted running QAT or (especially AVX) in mixed or mostly-accelerator workloads? And on the software side, (which was briefly touched on in the earlier QAT piece), what software enablement/dev work is needed to get these accelerators to work?
In a future piece with production silicon I’d be eager to get some thoughts on the above.
I don’t think QAT uses AVX. It’s like its own accelerator. Can you show the PCIE or other connection to the QAT accelerator?
Thanks for the balanced view. It’s good you talked AMD and history.
Now can you do that MikroTik switch review you mentioned in this article???
Woot! Woot! Awesome article Patrick/STH!
Why acceleration? It seems like Intel is either not able to or do not want to take the direction on multiple chips on package direction. That leads to packaging specialized chips (accelerators) into the same package with the CPU.
Intel was the company that brought the generic purpose CPU that can be tuned for multiple usages. It seems like AMD is heavily betting on that while Intel is taking the sideway with custom chips for individual workloads, like mainframes did.
It almost seems like Intel is playing into his strength of being able to deliver custom chips leveraging its army of engineers. Would this work? Really hard to say.
Server workloads are getting pushed into more and more to Cloud. So hyperscalers will make the decision but AMD’s strategy sounds better to me. Software is always more malleable over hardware and making the cores/cpus cheaper and abundant was the winning strategy of Intel. I expect it would work again for AMD.
What would be the picture with a QAT card + AMD processor?
There are enough PCIe lines for that.
Looks like it would be the best of both worlds: highest general purpose compute, QAT accelerator if useful.
I remember reading AMX is even worse regarding CPU clock down than (early) AVX512, when they added it to Linux they made it very difficult for workloads to run with AMX (the admin has to explicitly allow it for an application).
All of this needs software support, which only seems to be widely available for QAT. A repo on github probably isn’t enough for most people who don’t want to spend their operations budget on recompiling large parts of their software stack. The only way this accelerator strategy is going to work is if you can replace an AMD machine with an Intel machine, install a few packages through your distribution and it magically runs a lot faster/more efficient.
Also the big question what part of this is available in a virtualized environment. If AMX slows down adjacent workloads that might be cause enough to disable it for VMs in shared environments. I don’t know if you can pass down QAT to a VM.
> I don’t know if you can pass down QAT to a VM.
THIS is really the point in todays cloud world.
Can QAT and other accelerating technologies be easily used in VMs and in Containers (kubernetes/docker).
If they can be used:
– what do one have to do to make it work (effort)?
– whats the loss of efficiency, and with it
– how does a bare metal deployment compare to a deployment in Kubernetes/docker e.g. on AWS EC2 ?
I can’t say I’m on board with the STH opinion that these accelerators are a have changer in there market. From the trend I see is that every buyer but especially hyperscalers don’t want these vendor specific accelerators but they want general purpose accelerators.
Even Intel QAT support is pretty scarce and harder than needed to use and for network functions seemingly overtaken by DPU/TPU hardware. I don’t really see a space for the other Intel specific extensions, and am not sure why STH is such a subscriber to this idea of encouraging vendor specific extensions.
David, sorry but that’s crazy. NVIDIA has a huge vendor specific accelerator market. If hyperscalers didn’t want QAT Intel wouldn’t be putting it into its chips. I don’t think any features go into chips without big customers supporting it. TPU’s are Google only. DPUs outside of hyperscale how many orgs are going to deploy them before Sapphire servers? Even if you’ve got a DPU, you then have a vendor’s accelerator on it.
How much of a die area hit does the QAT on the new Xeon take?
“Imagine there is an application where you are doing various other work but then need to do one or a handful of AI inference tasks.”
1. Servers are not Desktop PCs where you do a lil bit of this, then a lil bit of that.
2. If it’s really just a handful of tasks you can do it on CPU fast enough without VNNI/AMX
CPU extensions like VNNI and AMX have been designed many years before the CPUs came to market. Today it is clear that they are useless as they can’t compete with GPUs/real accelerators.
Both Intel and AMD are stepping away from VNNI and moving to dedicated AI accelerators on CPU, just like smartphones SOCs. These are much faster and much more efficient than these silly VNNI/AMX gimmicks:
Intel will start Meteor Lake embedding their “VPU”.
AMD will integrate their “AIE” first in their Phoenix Point APU next year. They have also shown AIE is on their Epyc roadmap. I seriously doubt that we will ever see AMX on AMD chips.
These accelerators will usually not be programmed directly.They will be called through an abstraction layer (WinML for windows), just like on smartphones.
VNNI and AMX are both basically dead.
“AMD’s strategy is to allow Intel to be the first with features like VNNI and AMX. Intel does the heavy lift on the software side, then AMD brings those features into its chips and takes advantage of the more mature software ecosystem.”
Please stop making things up here: Intel is doing stupid things like VNNI and AMD has to follow for compatibility. Next to no one is using VNNI and there is almost no software ecosystem. They only did make VNNI accessible for standard libraries like Tensorflow you are using and also to WinML.
I am really surprised that you are still pushing Intel’s narrative from few years ago, as even Intel has stepped away from VNNI/AMX and is embedding dedicated inference accelerator units (VPU) in their CPUs.
Even the Arm makers are embedding AI inference extensions in their next DC procs so I’m not sure why there’s an idea that they’re dead. FP16 matrix multiply is useful itself.
@Viktor
“FP16 matrix multiply is useful itself.”
Yes, but why do it in your CPU core with all inefficiencies that come along. Instead these small datatype matrix multiplication will be executed on dedicated units that have better power efficiency, better performance and they don’t stop your CPU from doing anything else while executing.
Effective matrix multiplication is exactly what these VPU, AIE, NPU (Quallcomm), APU (AI processing unit / Mediatek) are doing.
AMX and VNNI are zombies.
Which qat acceleration pcie card was paired with Xeon Gold 6338N? Was it 8950,8960, or 8970?