
Intel is doing the disclosure they absolutely need to at SC19. Intel is showing off its exascale compute platform and you have every reason to be excited. There are three primary components: the Intel Xeon Sapphire Rapids CPU, Intel Xe “Ponte Vecchio” GPUs, and its oneAPI software. These are the components that will be in the Aurora exascale supercomputer delivered in 2021 to the US Department of Energy (DoE.) Let us be clear, 2021 will be exciting for Intel and the server market.
As a quick note, the Wi-Fi here at the Intel HPC Developer Conference is not great. We will update this article when we can get photos uploaded.
Intel Xeon Sapphire Rapids
We double-checked how much is public about this platform. It turns out not much. The big disclosures are a new architecture along with CXL. CXL, if you recall, runs atop PCIe Gen5 so this is a 2021 platform that will replace the 2020 Ice Lake/ Cooper Lake platform.
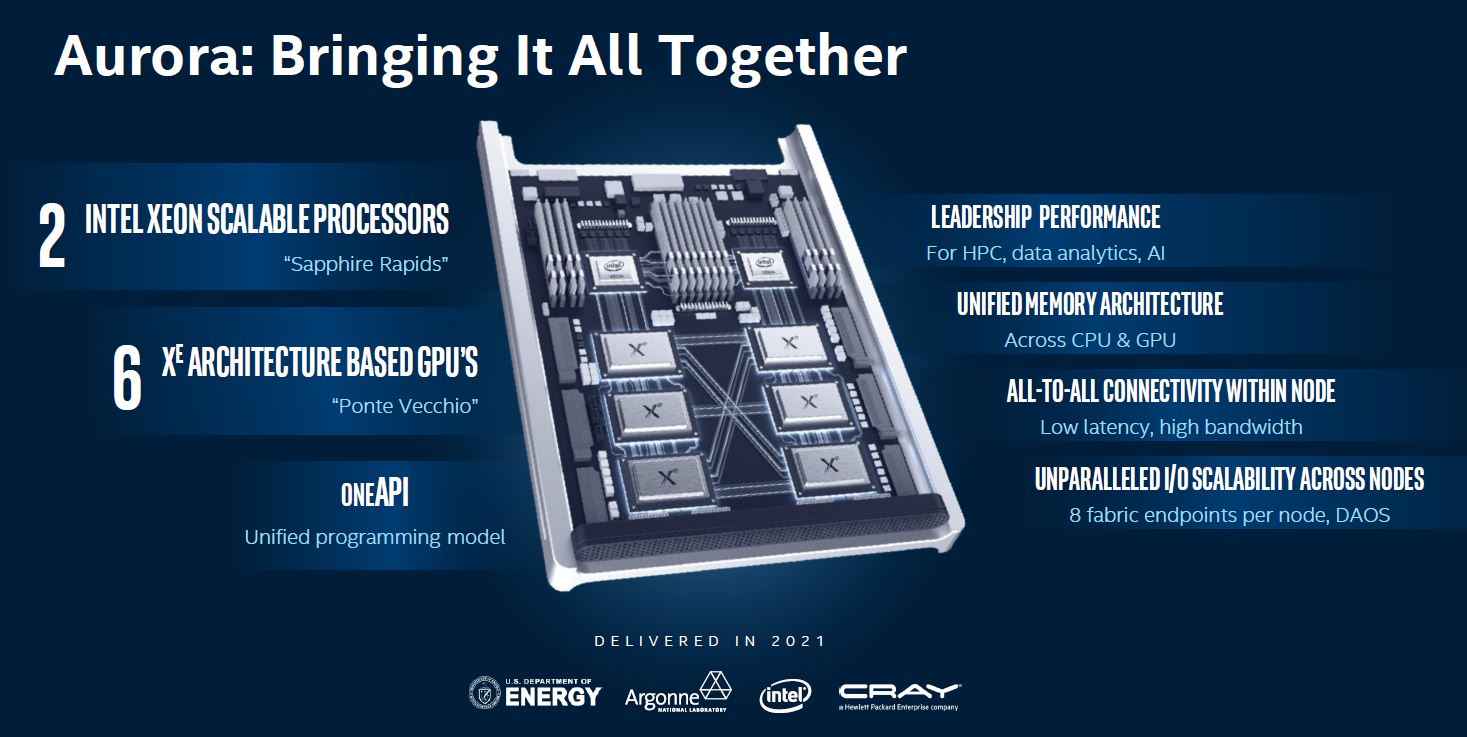
Intel is doing a lot more than just adding cores and PCIe Gen5. We will leave that to future disclosures, but Sapphire Rapids has a lot of folks in the industry buzzing.

We wanted to point out a theme that Intel is going to have to address next year that it is reiterating in its disclosure. 2020 will see Cooper Lake and Ice Lake Xeon generations. Intel is saying “Volume Ramp” in 2H’2020. There are many in the ecosystem wondering when chips launch for the non-hyper-scale and HPC customers. The later it is in 2020, the more of an Osborne effect will be in play for the Ice Lake Xeon launch. When Sapphire Rapids comes out, with CXL, we are going to start to see the big shift to not just a new PCIe generation, but also coherency levels that we do not have today. Probably the reason there is not too much out there on Sapphire Rapids is that Intel does not want customers to delay purchases and skip Ice Lake/ Cooper Lake in 2020.
Intel Xe Ponte Vecchio GPU
Behind the scenes, Intel is readying to bring competition to the GPU space unlike what we have seen before with the Intel Xe line of GPUs. This is Intel’s first GPU designed for the exascale level. When the company killed off the Xeon Phi x205 Series Knights Mill and Xeon Phi x200 Series Knights Landing designs, it turned to GPUs hiring an entire team in the re-tooling effort. The goal is to go directly after the market owned by NVIDIA and to some extent AMD.

About four years after the Xeon Phi was last launched, we are getting the Intel Xe Ponte Vecchio GPU. This is a 7nm Foveros packaged GPU that incorporates PCIe Gen5 and CXL.

The system has Raja Koduri’s fingerprints all over it with lots of vector compute and fast memory. You can read more about that in our Intel Cooper Lake Xeon For Training Details from Architecture Day 2018.

Of course, we fully expect NVIDIA and AMD to respond. Each can have a PCIe Gen4 generation to launch before we see a PCIe Gen5 generation so the Ponte Vecchio will not compete with today’s Tesla V100, even the Volta-Next SXM3 version when it arrives.
Intel has the Xe LP architecture for sub 20W and potentially up to 40-50W for low power and efficient processing. Xe HP was set to go to the higher power range. Xe HPC is much more compute versus graphics optimized with higher power and voltage.
Xe HPC has a new RAMBO Cache. The Rambo cache will sit on the XEMF. XEMF connects the compute, HBM, as well as other GPUs and CPUs. It is using EMIB for HBM as well as Foveros for Rambo Cache to get more bandwidth int other GPUs.

Xe Link is designed to be CXL based and with a unified memory structure across multiple GPUs. Intel also says that Xe for HPC will have Xeon class RAS, in-field repair, and ECC across all memory and caches.
Beyond the hardware, Intel is also focusing intently on software.
Enter oneAPI to Rule them All
Hardware is important, but what Intel is at least preaching today is the completely correct message. Software is what uses the hardware to do useful tasks. When the company first announced the new platform, we covered it in Intel One API to Rule Them All Is Much Needed.
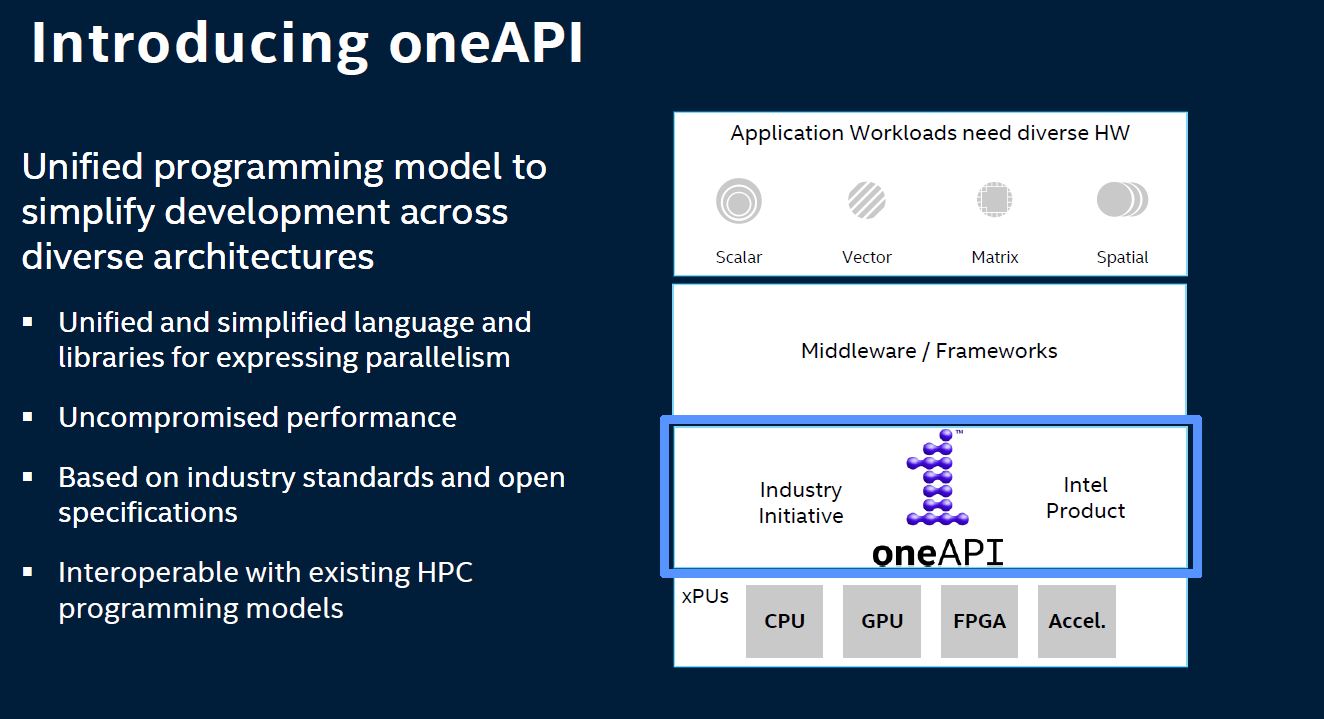
The succinct summary is that Intel oneAPI means that a programmer can define the problem they are trying to solve in a more hardware-agnostic manner. oneAPI abstracts the low-level hardware interface and makes it so that the best accelerator can be used.
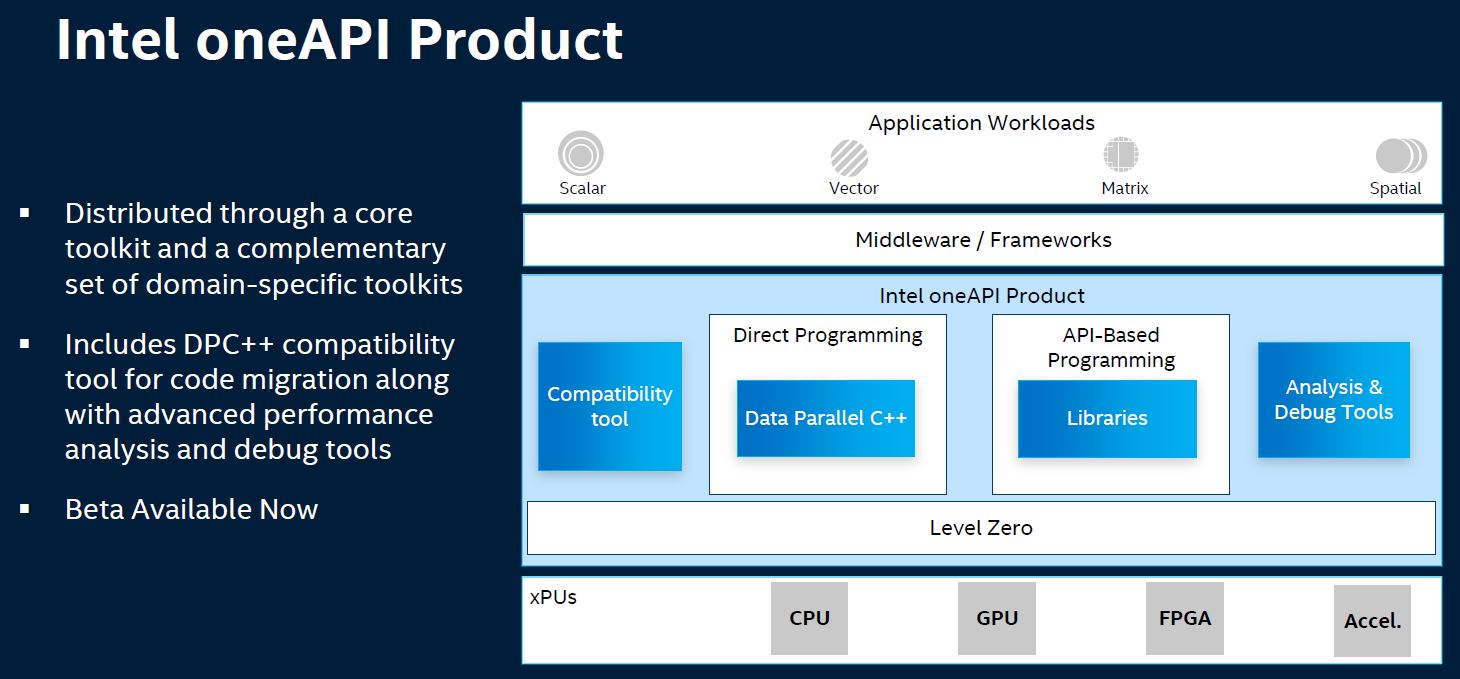
Intel is expanding its silicon portfolio significantly. With CPUs, GPUs, FPGAs, various AI accelerators all being in-play for the 2021 cycle, Intel needs to bridge the gap and make all of those tools accessible for software developers.
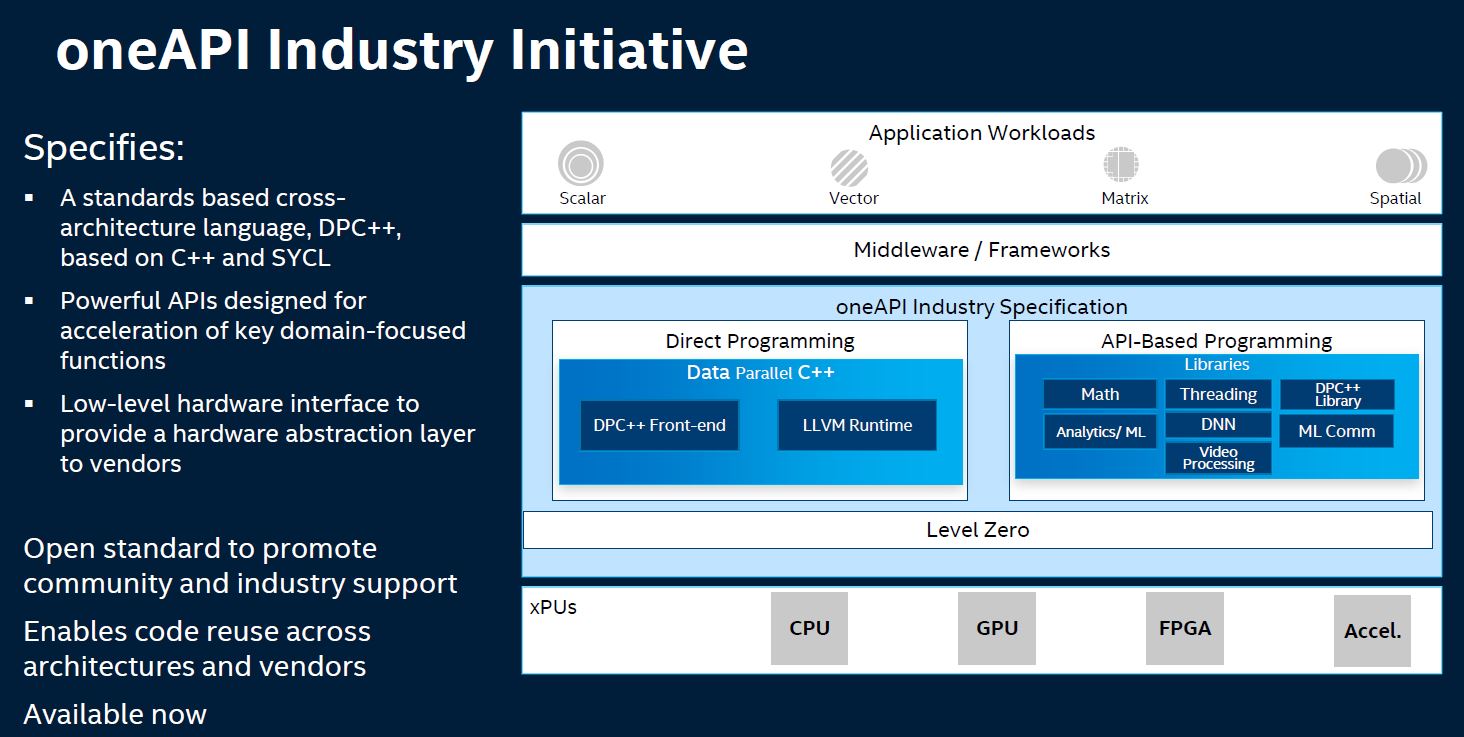
Again, to be clear, this is exactly what we want to see. In a perfect world, other vendors participate and the software developers can be removed from what hardware they are running.

Final Words
Again, 2021 is going to be a great year for Intel. All three of the major platform disclosures here are the right direction for the company and will increase competition in the industry. Of course, Intel also dedicates a slide to say that what it is showing as 2021 plans are forward-looking statements that may be impacted by future events. That was a big deal for 10nm but the company says its 7nm is on track for 2021. If that is the case, it is going to have great hardware and software shown off at SC21.




{kind=link}
Remember the XKCD about competing standards? Why not just make an OpenCL compiler for their xPUs? Maybe embrace SyCL?
“In a perfect world…”
Yeah, we’ve already seen how well Intel works with other vendors with “open” APIs. Let’s just say it all technically works, but that’s the best one can say.
“Intel also dedicates a slide to say that what it is showing as 2021 plans are forward-looking statements that may be impacted by future events”
You mean like reality?
At SC21 Intel will talk about how great SC23 will be.
OneAPI dpc++ looks like standard C++ llvm compiler. It extends SyCL, supports SPIRV, OpenCL.
https://github.com/intel/llvm/tree/sycl/sycl/doc/extensions