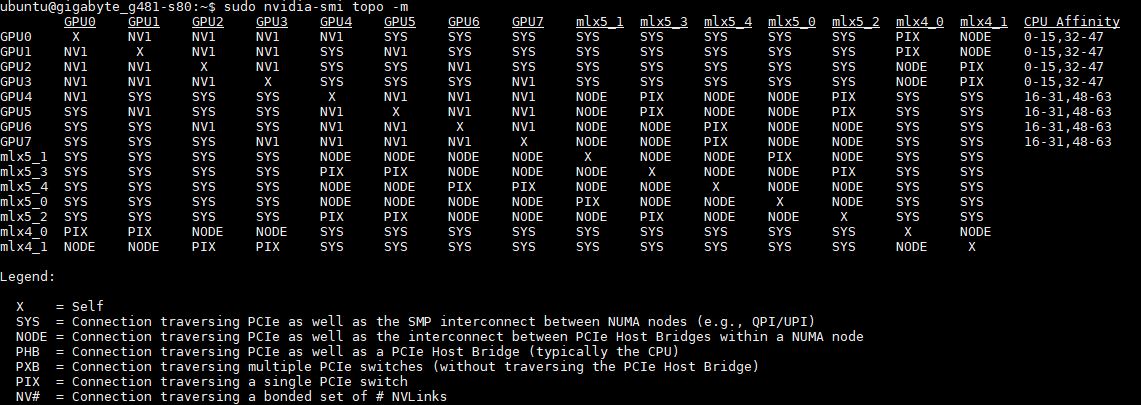
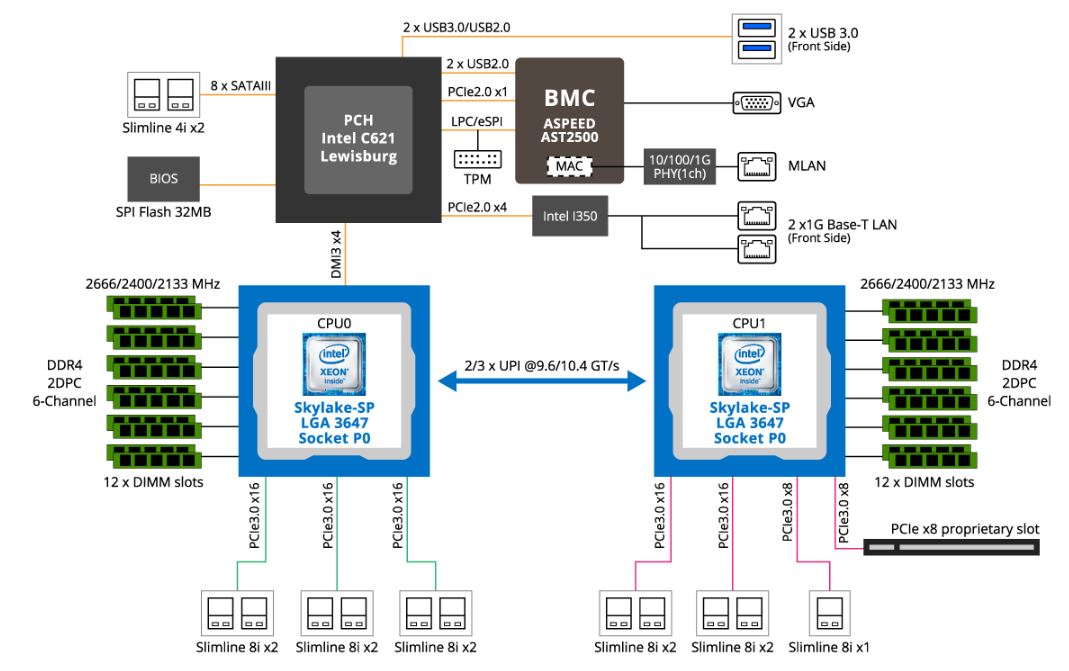
Gigabyte G481-S80 DeepLearning12 Topology
We first wanted to start with a bit about a DGX-1/ DGX-1.5 class server topology. There is a difference between Pascal (Tesla P100) and Volta (Tesla V100) generations. The newer NVIDIA Tesla Volta V100 generations have 6x 50GB/s NVlinks while the older Tesla P100 generation that we are using has 4x 40GB/s links. That means that the speed/ latency of the Tesla V100 links will be better, but it also means that each GPU in the V100 configuration has more bandwidth to other GPUs due to the additional links.
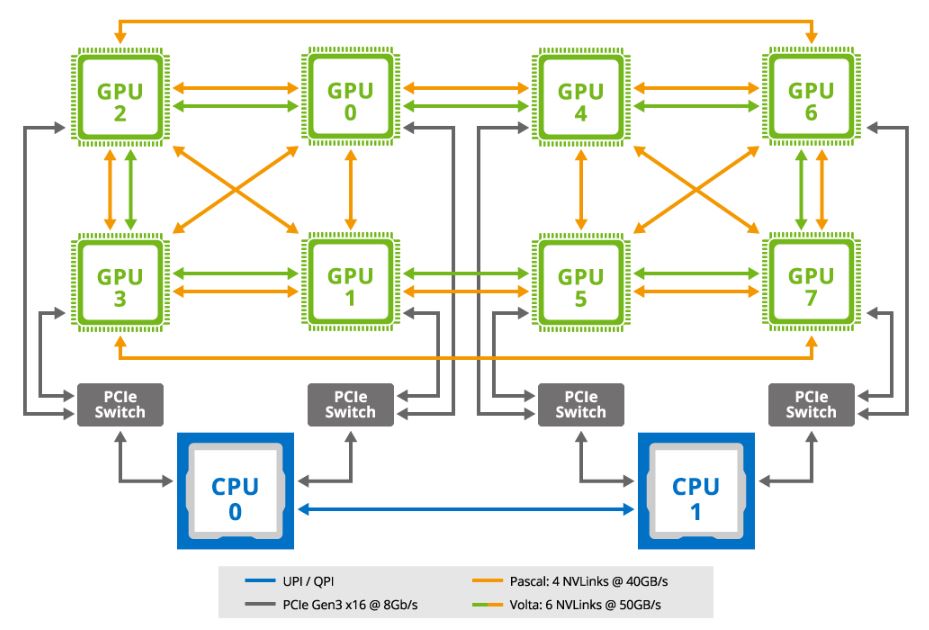
In these architectures, there are two PCIe 3.0 x16 links from each CPU to PCIe switches. In this case, Broadcom (PLX) PCIe switches. Each switch is connected to two GPUs and one PCIe 3.0 x16 networking slot. The GPUs are connected to each other via NVLink but are also connected to PCIe through this switch complex. More importantly, for GPUDirect RDMA, each pair of GPUs that shares a PCIe switch is also connected in the same PCIe root complex to a Mellanox Infiniband card.
We had a ton of NICs installed in the system, but we wanted to show what the topology looks like:
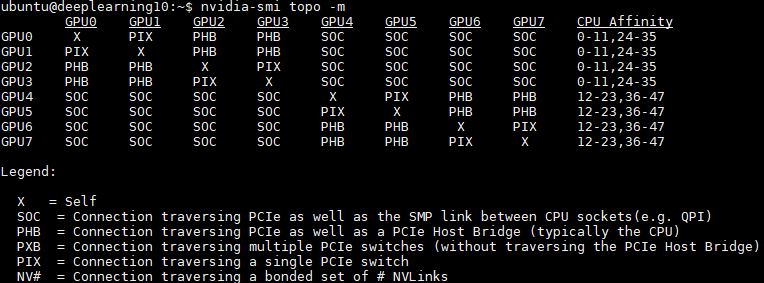
For comparison, here is our DeepLearning10 8x PCIe GPU (NVIDIA GTX 1080 TI) topology. You will notice that this topology traverses the PCIe and sometimes the QPI/ UPI links more often. You will also notice the absence of the Mellanox cards in that solution as they were not showing up at the time with GTX 1080 Ti’s.
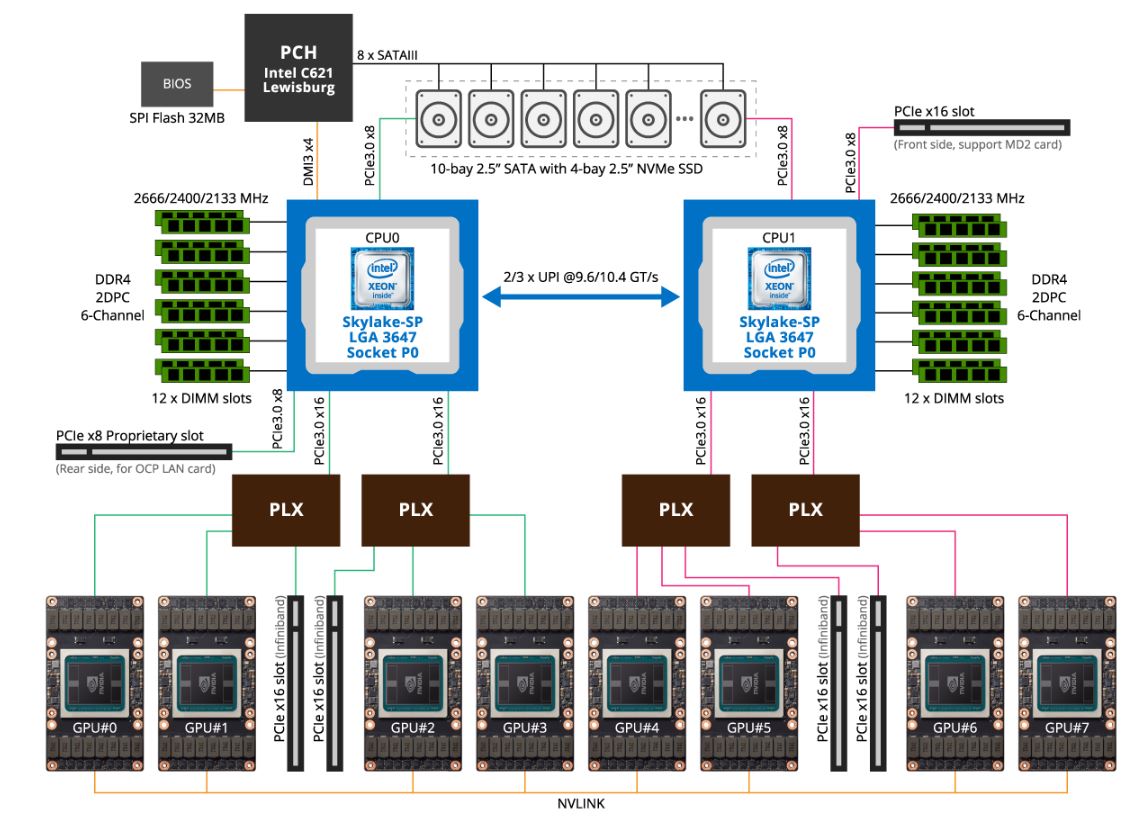
Taking a step up the stack to the system itself, you can see the motherboard topology here. The front panel connectivity is handled mostly through the PCH and CPU0.
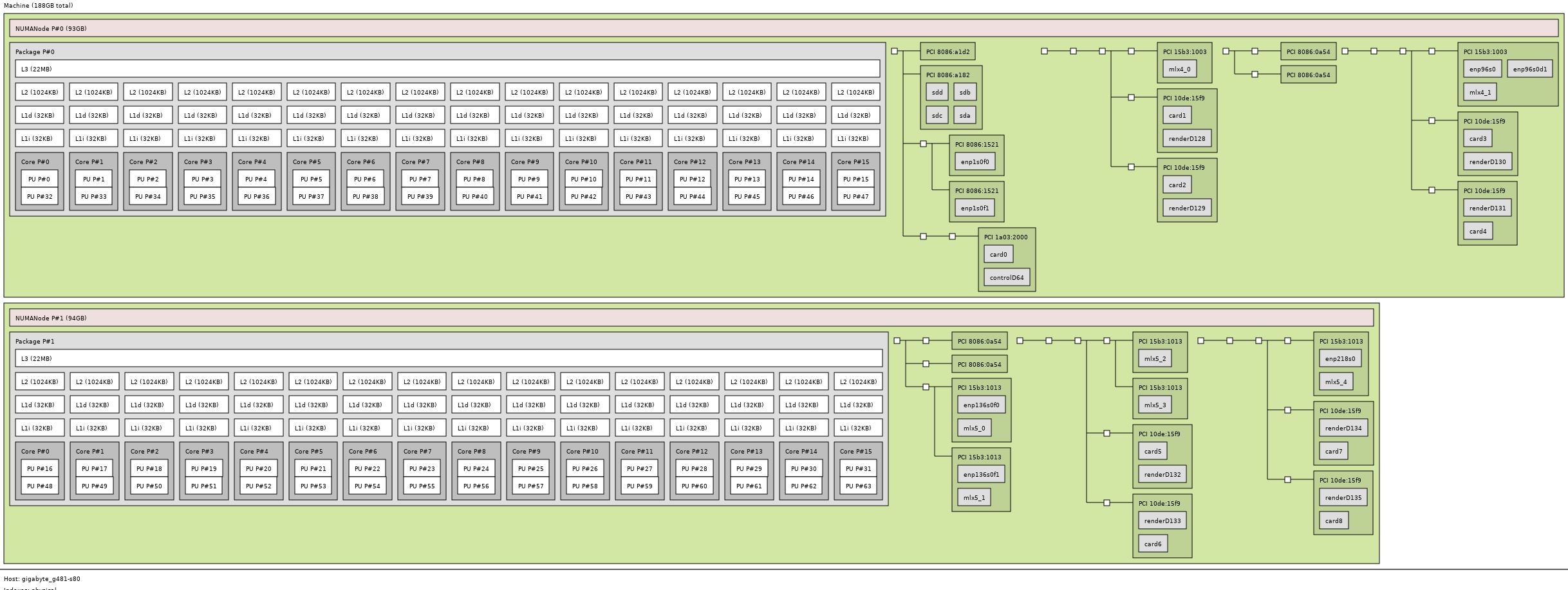
Here is the lstopo view of the system topology that we took during testing.
These days, if you want faster GPU to GPU communication this type of solution is what you want if you cannot get into a DGX-2 / HGX-2 class 16x GPU 10kW system. We covered How Intel Xeon Changes Impacted Single Root Deep Learning Servers which make them less desirable in the Intel Xeon Scalable generation.
Next, we are going to start looking at performance before getting into power consumption, cost of ownership, and then our final words.



{kind=link}
Gromacs would be a nice benchmark to see.
Thanks for doing more than AI benches. I’ve sent you an e-mail through the contact form on a training set we use a Supermicro 8 GPU 1080 Ti system for. I’d like to see comparison data from this Gigabyte system.
Another thorough review
It’s too bad that NVIDIA doesn’t have a $2-3K GPU for these systems. Those P100’s you use start in the $5-6K each GPU range and the V100’s are $9-10K each.
At $6K per GPU that’s $48K per GPU, or two single root PCIe systems. Add another $6K for Xeon Gold, $6K for the Mellanox cards, $5K for RAM, $5K for storage and you’re at $70K as a realistic starting price.
Regarding the power supplies, when you said 4x 2200W redundant, it means that you can have two out of the four power supplies to fail right?
I’m asking this because I’m might be running out of C20 power socket in my rack and I want to know if I can plug only two power supplies.
Sorry, my question’s reply is in the marketing video.
They are 2+N power supplies.
Interested if anyone has attempted a build using 2080Tis? Or if anyone at STH would be interested. The 2080 Ti appears to show much greater promise in deep-learning than it’s predecessor (1080Ti), and some sources seem to state the Turing architecture is able to perform better with FP16 without using a single many tensorcores as former Volta architecture. Training tests on tensorflow done by server company lambda also show great promise for the 2080Ti.
Since 2080Ti support 2-way 100Gb/sec bidirectional NVlink, I’m curious if there are any 4x, 8x (or more?) 2080ti builds that could be done by linking each pair of cards with nvlink, and using some sort of mellanox gpu direct connectX device to link the pairs. Mellanox’s new connectX-5 and -6 are incredibly fast as well. If a system like that is possible, I feel it’d be a real challenger in terms of both compute-speed and bandwidth to the enterprise-class V100 systems currently available.
Cooling is a problem on the 2080 Ti’s. We have some in the lab but the old 1080 Ti Founder’s edition cards were excellent in dense designs.
The other big one out there is that you can get 1080 Ti FE cards for half the price of 2080 Ti’s which in the larger 8x and 10x GPU systems means you are getting 3 systems for the price of two.
It is something we are working on, but not 100% ready to recommend that setup yet. NVIDIA is biasing features for the Tesla cards versus GTX/ RTX.