
We are hearing more about sustainable AI compute, and FuriosaAI has its solution with RNGD. This is almost the opposite of many AI compute platforms we have learned about today. Instead of going for maximum power, this is a lower power compute solution.
This is the last talk of the day after over a dozen, and this is being done live, so please excuse typos.
FuriosaAI RNGD Processor for Sustainable AI Compute
Here are the specs on the card. This is specifically not designed to be the fastest AI chip on the market.

Here is a look at the card with its cooler.

The target TDP is only 150W for air cooled data centers.

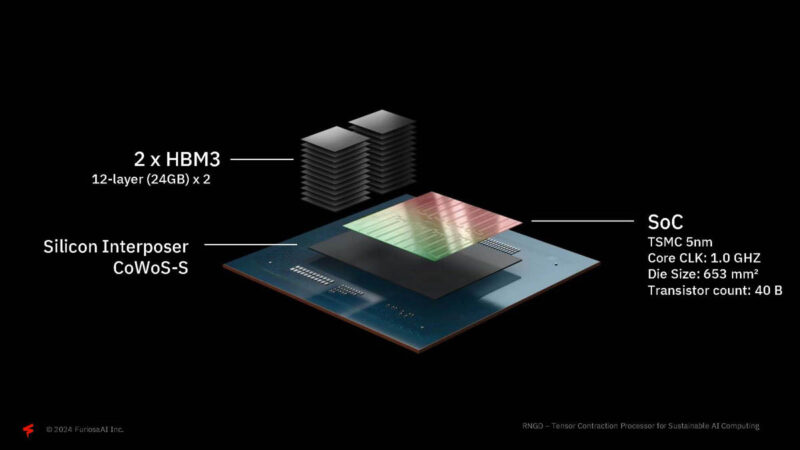
The construction is done using 12-layer HBM3 and TSMC CoWoS-S and a 5nm process.
Instead of focusing on the H100 or B100, FuriosaAI is targeting the NVIDIA L40S. We did a big piece on the L40S some time ago. The goal is to not just provide similar performance, but also to provide that performance at lower power.

The efficiency comes from hardware, software, and algorithm.

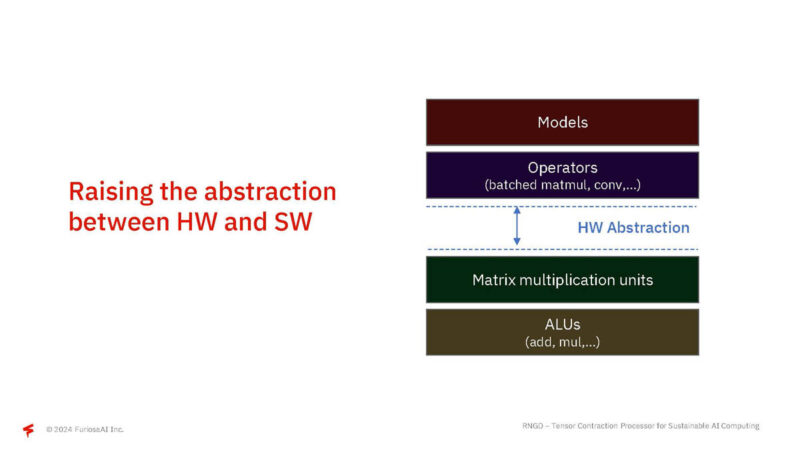
One of the challenges FuriosaAI has been trying to work on the abstraction layer between hardware and software.
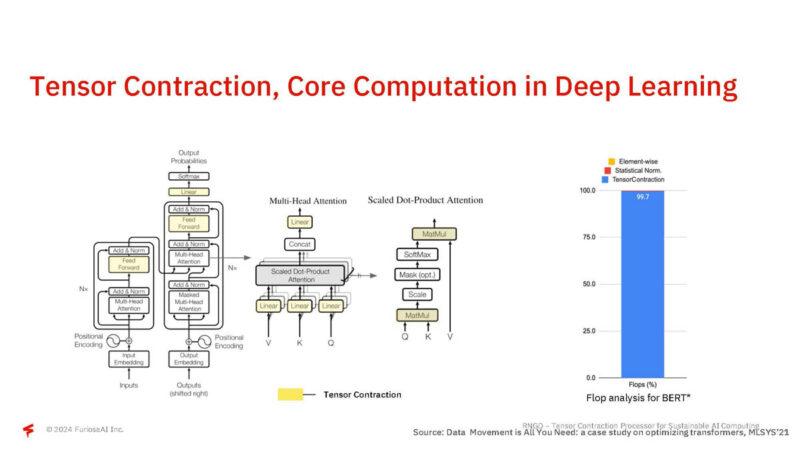
Tensor Contraction is one of the big operations that FuriosaAI. In BERT, this was over 99% of the FLOPS.
Usually, we have matrix multiplication as a primitive. Instead of the Tensor Contraction.

Instead, the abstraction is at the Tensor Contraction level.

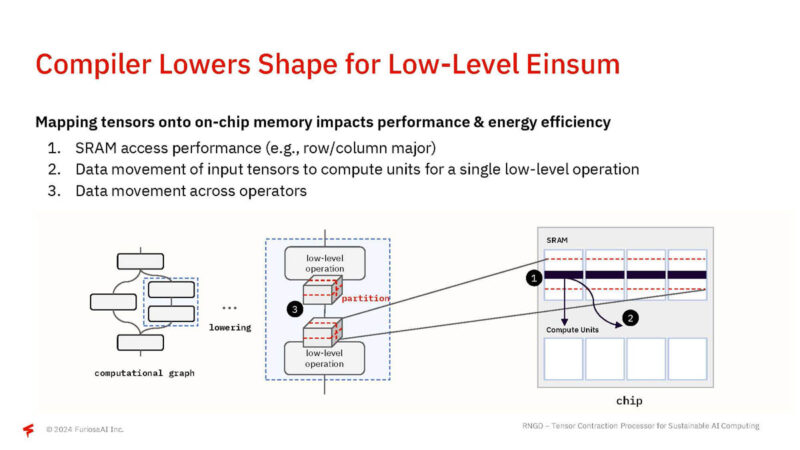
Furiosa adds a low-level einsum for its primitive.

Here, matrices A and B are multiplied to produce C.

Furiosa then takes this, and schedules it on the actual architecture with memory and compute units.

From here, a whole tensor contraction can be a primitive.
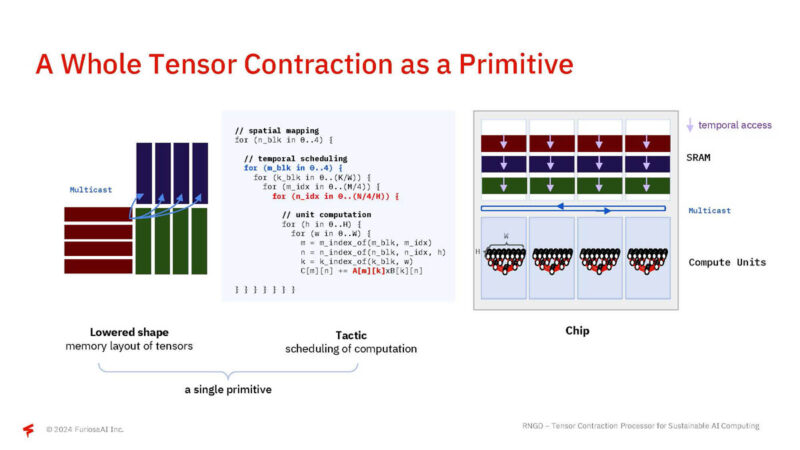
By taking into account spatial and temporal orchestration, they can boost efficiency and utilization.
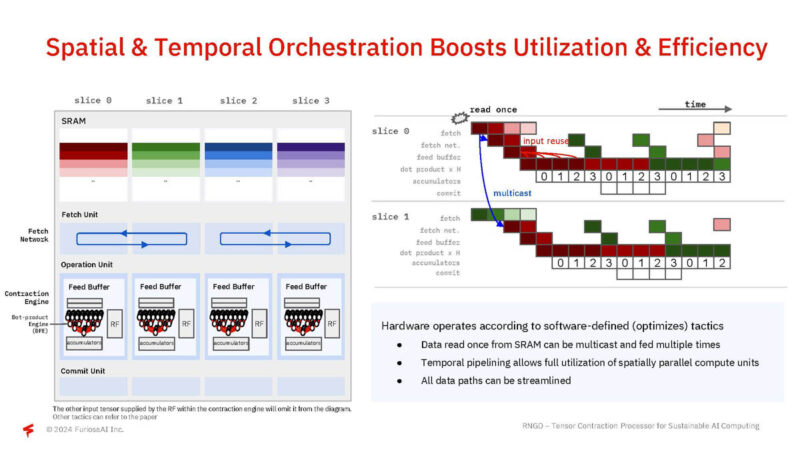
Furiosa says that it has flexible reconfigurability which is important to keep performance high as batch sizes vary.

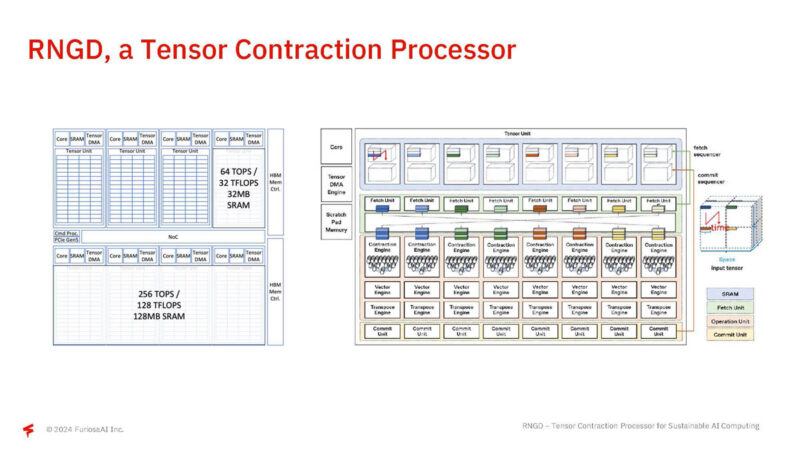
Here is a look at the RNGD implementation.
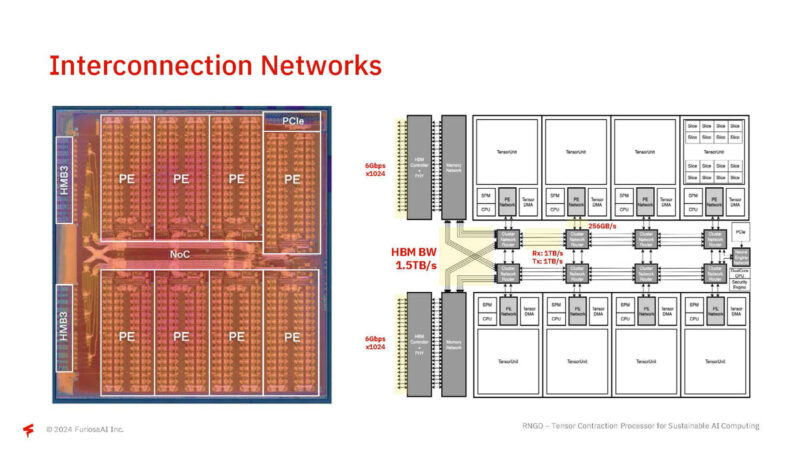
Here are the interconnect networks, including to get to the scratchpad memory.
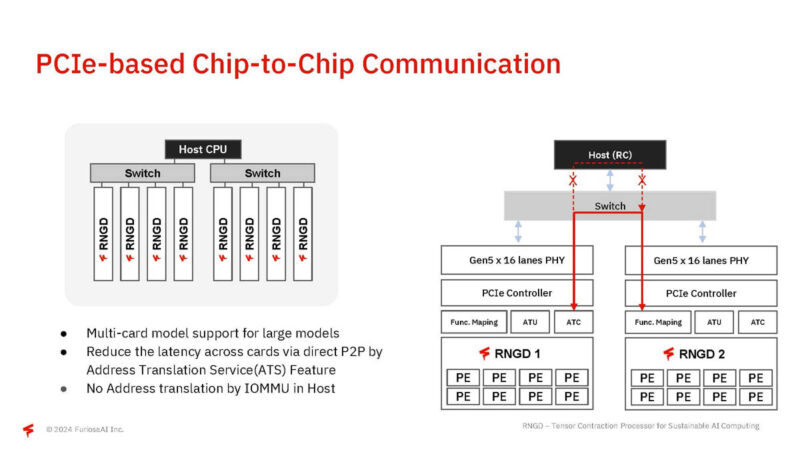
Furiosa is using PCIe Gen5 xq6 for chip-to-chip communication. It is also using P2P over a PCIe switch for direct GPU to GPU communication. That is why if XConn can get it right, they have an awesome product.
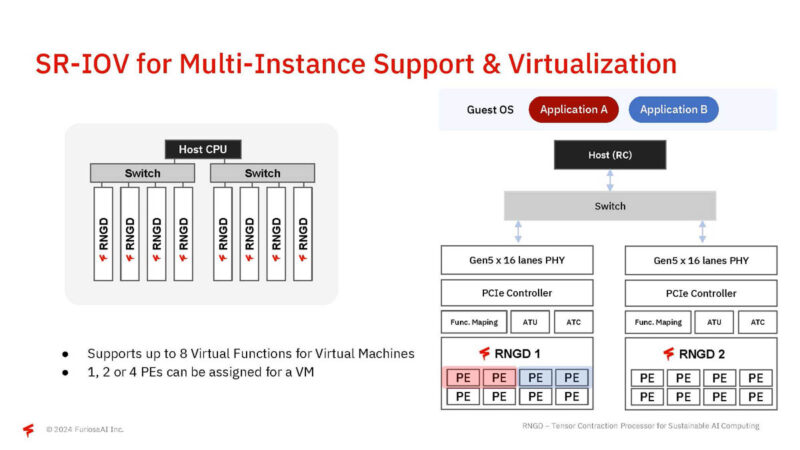
Furiosa supports SR-IOV for virtualization.
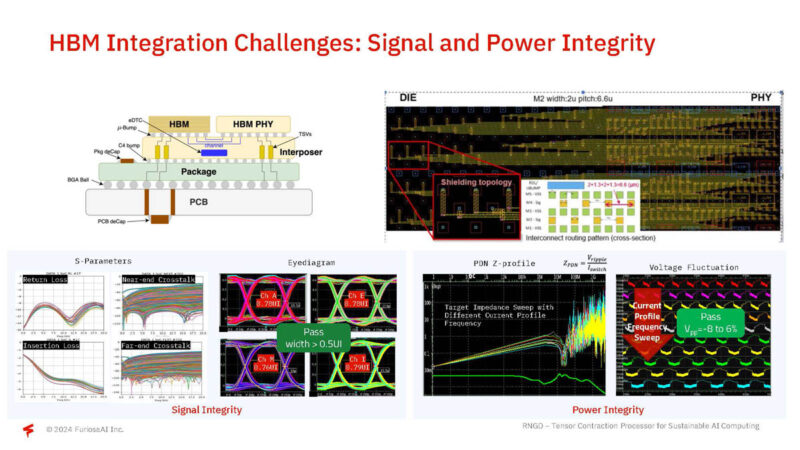
The company has done work on signal and power integrity for reiliability.
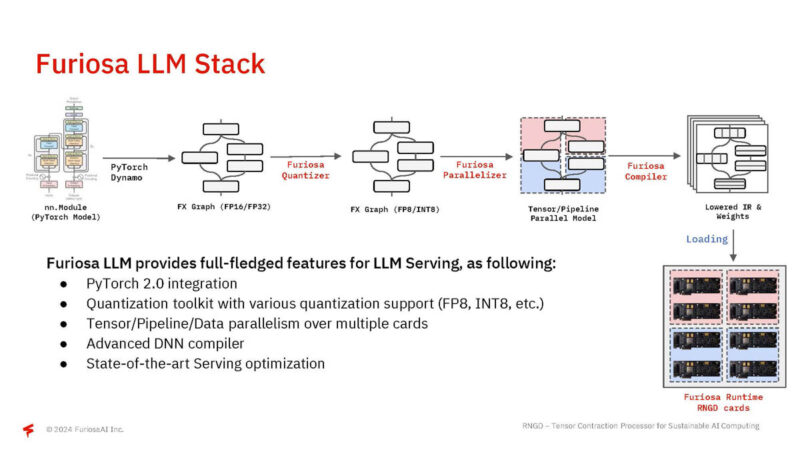
Here is how Furiosa LLM works in flow chart form.
The compiler compiles each partition mapped to multiple devices.
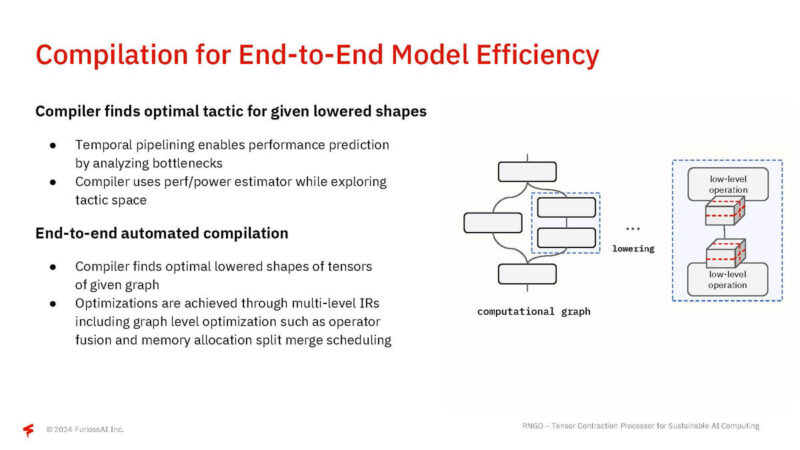
The compiler optimizes the model for performance gains and energy efficiency.
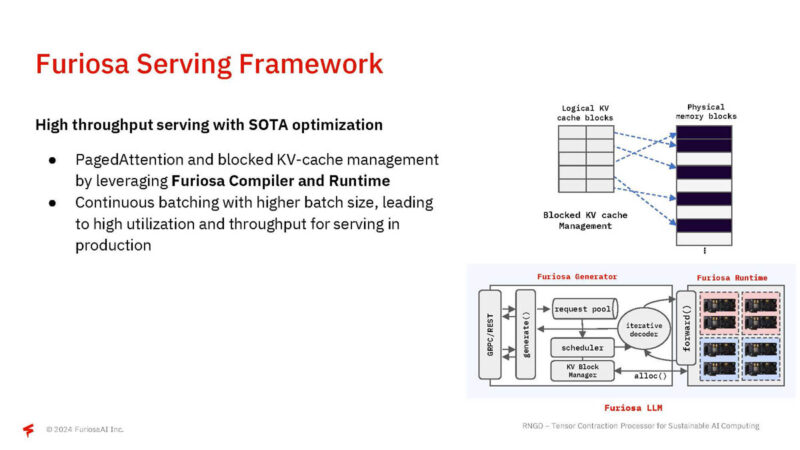
The serving framework does things like continuous batching to get more utilization.
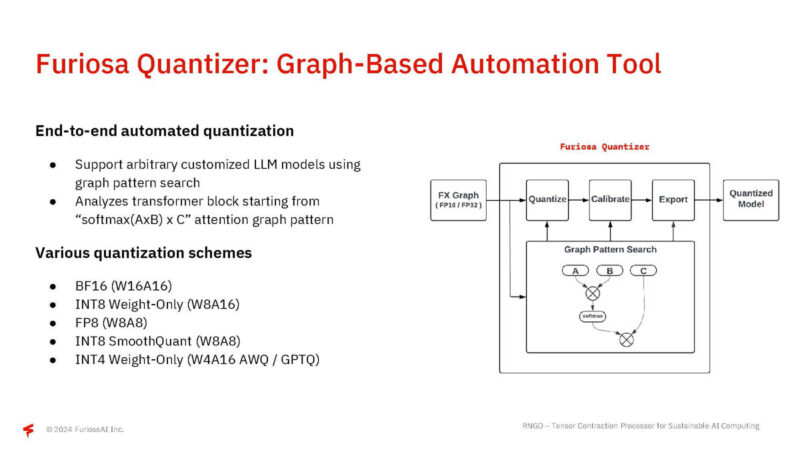
The company has a graph-based automation tool to help with quantization. Furiosa can support a number of different formats including FP8 and INT4.
Here is the company’s development methodology.

Final Words
There was a lot here. The quick summary is that the company is using its compilers and software to help map AI inference into its lower-power SoC in order to provide lower power AI inference.



{kind=link}