
Years ago, we had a big decision to make. In 2013, STH had grown to a size that would seem immeasurably small by the traffic we do today. Still, at that point, we made the decision that it made fiscal sense to leave Amazon AWS for colocation. We chronicled the reasoning in Falling From the Sky Why STH is Leaving the Cloud and then the cost breakdown in Falling From the Sky Part 3 – Evaluating Amazon EC2, VPS, Dedicated and Colocation Options. Since 2013, we have been doing some irregular updates that largely correspond to planned upgrades of our infrastructure. Since we are taking a look at a few upgrades again, it is time to go through the exercise again.
Video Version
If you want to hear this instead of just reading, we have a YouTube video with some commentary here:
Of course, we can go into a bit more detail below, but some prefer to listen rather than read so we have that option.
Grading Estimates from our 2018 5-year Checkpoint
In 2018, we looked again at whether it was time to move back to the cloud. In our cost analysis, this is what we found using 1-year estimates:
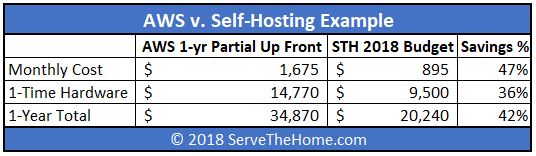
Just to give some sense of how that March 2018 estimate has gone in the 32 months since we looked at this, we ended up using:
- Way more bandwidth. STH has grown a ton since 2018. We also focus more on reviews which tend to use more photos. Even with lazy loading images, our bandwidth usage is significantly higher. This did not incur an incremental cost based on how we buy bandwidth. See: Buyer’s Guide to Hosting: Bandwidth, Data Transfer and Billing
- Several of our VMs doubled memory requirements and we added slightly more storage. We overprovisioned so this was absorbed with still enough leftover.
- We replaced a SSD, upgraded a firewall, and added another ATS PDU. We have not done long-term infrastructure upgrades.
- We ended up using an upgraded node that we had available, as a “hot spare”. We tend to “self-warranty” hardware, and so we had an extra system/ chassis there.
- We are going to say we used four hours of labor. This includes drive time to the primary data center. Since it is far away (18-20 minute drive), we actually did not go there for several quarters. So over 32 months, we had budgeted $640 for remote hands. We effectively either paid $160/ hr or paid less than that even rounding up to four hours.
Overall, it looks like we probably over-estimated self-hosting costs again, and underestimated AWS costs with respect to how much we would spend there, even after service discounts.
The Late 2020 AWS v. Colocation Update
We wanted to answer the question of what the picture would look like for hosting STH now. A few quick words before we get there on assumptions.
First off, we completely could change the way we run the site. That is a given. Frankly, running in VMs whether on the cloud or in self-hosting is convenient. Indeed, we run containers in VMs as well. We could also overhaul the entire software stack again, but frankly, we want to spend more time creating content then doing that work. Something that we learned was that we had less reliability by increasing complexity than by keeping things as simple as possible.
Second, we are modeling current data transfer, and a minimal set of VMs. We actually have a lot more running, including some services that we run for some of the labs. One could argue that since they are lab services they are part of bringing you STH, but they are not focused on the web hosting aspect so we are going to remove them. Also, we have other VMs that are likely only online because we wanted to try something and had capacity. We may or may not elect to run the VMs if there was the AWS incremental cost. We could model these as on-demand or spot instances, but instead, we are just removing them entirely.
Third, we completely understand spot pricing. We are modeling a basic set instead of adding extras. At some point, we need databases, nginx servers, and so forth.
Fourth, we are going to add a mix of AMD EPYC and Intel Xeon instances roughly about what we use for our hosting. We are heavily weighting the larger instances toward the EPYC instances since that helps bring down the costs and for our workloads, there is no appreciable difference. We could go Arm, but that requires some small lift and shift work.
Finally, we do use some AWS services. Those services we would use regardless so we are excluding them from the analysis. We are also not modeling services such as Mailchimp which handles our weekly newsletter, Teespring that handles our online merch shop, YouTube which hosts our videos, and so forth.
AWS Cost 1-Year Reserved No Upfront
Here is the calculator for the absolute base setup for our hosting using 1-year reserved upfront instances:

As you can see, our hosting costs are just under $4,300 per month.
AWS Cost 1-Year Reserved Partial Upfront
Swapping to 1-year reserved partial up-front on the instances helps bring pricing down a bit albeit with a $19,512 up-front cost.

When we factor in the up-front we get a $4,137.63 monthly cost along with a $49,651.56 total annual cost for the year. We are not discounting here using future values/ present values. There is a big issue with this. Typically, we tend to see our servers run for years. To model that, we tend to use 3-year reserved partial upfront.
AWS Cost 3-Year Reserved Partial Upfront
Using the 3-year reserved partial upfront on the instances gives us a much lower operating cost with a larger up-front payment.

First off, the $39,020 is more than we have spent in the last three years on hosting hardware. We do not purchase machines with long warranties or high markups, so if you are buying the average Dell/ HPE/ Lenovo server and think that sounds like a single server, you are trading higher upfront costs for service contracts. Given what we have seen on hardware/ remote hands, it is not a model we are pursuing. On the operating side, we get down to $1,968.51 per month which is great.
STH 2020 Hosting Budget
Next year, we will likely do two small changes. First, we will upgrade database nodes and instead of using Optane SSDs, we will move to Cascade Lake and Optane PMem DIMMs into the database servers and upgrade a few older nodes to AMD EPYC 7002 “Rome” systems. We are testing the Ampere Altra 80-core server right now, and we are at the point where we might consider using Arm in the hosting cluster this year. We are going to increase our hardware budget to $10,000 this year. Although we did not use most of our hardware budget in 2019 nor 2020, we expect to in 2021.
Making up our monthly cost, we increased a bit for inflation. We used a $895/ mo budget in 2018. Our costs are effectively flat, but we are going to assume a bit more labor to install servers/ upgrade the hardware.
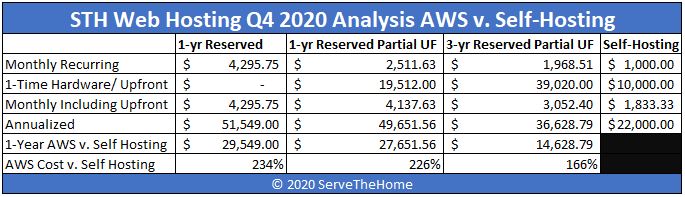
We are budgeting $22,000 per year or around $1833.33 per month. This is about the same as we would need for EC2’s 3-year partial upfront reserved instance, albeit without the up-front costs.
The one item that skews this substantially, is that we are not replacing every node every year. We are now in a very different place than we were when we started this journey. We have existing infrastructure that is frankly fine from a performance and node count standpoint even though we have relatively under-invested over the past 32 months. We had budgeted around $1687/ month for the last two months and spent under $1000. Still, at some point, we like to replace equipment before it fails.
Final Words
There is clearly a lot going into this. We now have just under 8 years since this 10U colocation spot in Las Vegas was our first setup:

What is not reflected in our discussion is all of the lessons learned along the way. Also, as hardware has gotten faster, and memory prices have decreased, the cost of self-hosting has gone down significantly for our applications. We are also taking advantage of falling bandwidth prices. While AWS is absolutely the right choice for many applications, and indeed we use them, for our web hosting it is not what we want for a simple and inexpensive setup. This may not be the perfect analysis, but it is a little bit of how we now look at hosting at STH.



{kind=link}
Thanks for reaffirming the self-hosting believes. :)
If I may request, more pictures /posts of correct setup please. The way StackExchange publishes once in a while.
Secondly, that “self-warranty” seems really interesting. Not for the faint hearted, but still cool. It works be awesome if could post some guidelines posts for this.
This is a great article, It hits home the point that cost of cloud is not a strength of cloud infrastructure. Cloud is great for companies and orgs that don’t want to worry about hardware/infrastructure and paying people to do it.
Excellent article, thanks for the detailed numbers. I’ve done my own cost/benefit analysis for a department that I’m consulting with and came up with similar conclusions. For highly variable workloads it may make sense to burst to the cloud but for the workloads I’m looking at, colo/self hosting makes much more sense in the long run.
It’s been a while since I was a WordPress architect/engineer, but I have some reservations how you’ve proposed your architecture here. You addressed it a bit, on how you don’t want to modify your operating model, but I think avoiding that exploration is a disservice to you and your audience. If you’re running containers, I’d be curious how that looks cost wise on ECS/EKS backed by EFS, versus on managing a fleet of EC2 instances backed by EBS. On storage, you’re relying on expensive EBS volumes instead of serving files via S3/CloudFront (which has been supported by WP for a long long time). I’m also not seeing a mention of REDIS/Memcached in your setup, further requiring bigger instances since the vast majority of your site could be served as “flat files” from a cache.
I certainly appreciate the amount of thought you’ve put into _this_ architecture. But I really think you should take a deeper look at how you’ve architected the site on AWS as it’s not an optimal re-platform. If you’d like to speak a bit further on this, happy to advise, e-mail is attached to the comment.
For an improved apples-to- apples comparison, it would be interesting to incorporate (into your costs of self-hosting) the cost of electricity (energy + power demand) for both computing and cooling.
The AWS pricing certainly includes those costs.
My experience is that self-hosting can save you a TON of money if you do it right and have the skills in house… especially if you aren’t paying full retail prices for your hardware and aren’t buying horsepower that you don’t need.
That said, to get a true apple-to-apples comparison, you would want to add AWS Savings Plans to the mix. They can save you 30-50% on your AWS bill and are dramatically more flexible than Reserved Instances.
Dave – those are included in our estimates of course. That is how colocation is usually sold.
As it is always said, a “lift and shift” rarely works, cost-wise.
With just a little work you can drastically reduce your costs (theoretically, you should probably run the AWS calculator at it). Instead of having heavy duty servers serving everything, just use static files hosted on S3 and cached with Cloudfront. WordPress can output them via Simply Static ( and probably other plugins), you just need a small script to upload them. It can take like an hour or two to setup that, and then you can make do with a basic t3 instance for the WP, since it’s only an admin interface. The only problem to solve is comments, and that’s not that hard to do ( either via disqus, or any of the self-hosted alternatives).
TL;DR you’re looking at it wrong, and comparing apples to apples, when you should be comparing apples to nutrition bars – same end result, but vastly different at everything else.
There’s no doubt that without the labor, it’s going to be less expensive. I would be very interested if you also took into account at least the labor (still ignoring the opportunity cost of delaying working on solving customers’ problems) all infrastructure work. If you are able to include the labor spent managing cloud and on-prem as a second cost factor, that would tell a more-complete story.
Hi Jim – labor is included which is discussed in both the article and the video. It is a pretty common myth that labor has to be a lot and therefore expensive at the colo/ data center level.
Interesting how the most expensive part of the whole equation was not factored in: employee time. For example, if a developer wants a load balancer in a co-lo, they have to ask the ops team to create one which takes time away from the developer (context switching) as well as the ops who have to context shift as well approve who will at the very least need to execute a script on their end to create the load balancer. At worst, the whole creation step is done manually and highly error-prone.
Now think about the same thing for a server box, a redis server, a database, ElasticSearch, authentication systems, etc. that has to be created by the developer that has been abstracted away by cloud infrastructure. All that developer time costs money but possibly more importantly speed to market.
That’s what cloud provides: the ability to turn the faucet and get water instead of having to build a well and pump your own water.
Adrian – again, this is for a mature application and is our actual operating expenses, including time spent, not necessarily generalized to every application and adding new ones.
In a broad sense, you are thinking correctly of cloud benefits to developers building something new, but this is about our operating existing infrastructure.
I am guessing STH is way more popular that what I expected for those Server Setup. Could those number be published just like StackOverflow [1][2] ( They have grown a lot since then as well ).
And did any point STH thought about actually publishing using something 3rd part apps like WordPress.com instead of good old fashion self hosting? Since STH “seems” to be simple enough for most modern hosted CMS to handle.
[1] https://nickcraver.com/blog/2016/02/17/stack-overflow-the-architecture-2016-edition/
[2] https://nickcraver.com/blog/2016/03/29/stack-overflow-the-hardware-2016-edition/
A bit of a necro, I know, but…
The thing that I always see missing from these kinds of estimates are the man-hours put into researching, sourcing, assembling, and deploying the hardware in a colo scenario.
I know most of us enjoy that stuff anyway, but the reality is, in a professional situation, we all tend to go with big name brands for the service and support, and the same thing applies here: with AWS, if an instance fails, you spin up another and YOLO.
One single disaster recovery occurrence in a colo and you’re spending multiples of what you saved by choosing colo in the first place…