Facebook Yosemite and Xeon D Platform
At STH, we have covered the Yosemite platform for around half a decade. With Yosemite V1, Facebook and Intel made a breakthrough innovation utilizing low-power Broadwell-DE chips that proved useful as high-density front-end web serving nodes. Facebook used a special version of what the broader market knows as the Xeon D-1500 series for that platform. The company also became a driving force behind multi-host adapters as it used one NIC to connect multiple nodes.

With the Skylake-D generation, we got the Xeon D-2100 and Yosemite V2 that used the “Twin Lakes” platform.

One may notice, we did not get a Cascade Lake-D generation. Effectively, Intel had a Xeon D for Broadwell (Xeon E5-2600 V4) and Skylake (1st Gen Xeon Scalable) but not Cascade Lake (2nd Gen Xeon Scalable.) When we look at the new Yosemite V3, we can make an educated guess as to why.
Facebook Delta Lake and Yosemite V3
We are going to start with the Delta Lake platform, and then show how it is used in Yosemite V3. As a quick note here, this is Delta Lake, not “Delta” the codename for the NVIDIA HGX A100 8x GPU board launched this week.
Facebook Delta Lake
The server uses the 3rd generation Intel Xeon Scalable processor (“Cooper Lake”) Like its predecessor such as Twin Lakes, it is designed to be a single NUMA node and single-socket platform that is highly configurable.

Here is the block diagram. It is interesting that in 2020 we have a platform that is being released using the PCH SATA still for M.2 boot. This adds flexibility, but for most applications, we are going to tell our readers to just get NVMe these days rather than something such as a Micron 5100 Pro M.2 SATA Boot SSD like we saw used in the Inspur NF5488M5 8x NVIDIA Tesla V100 Server review.
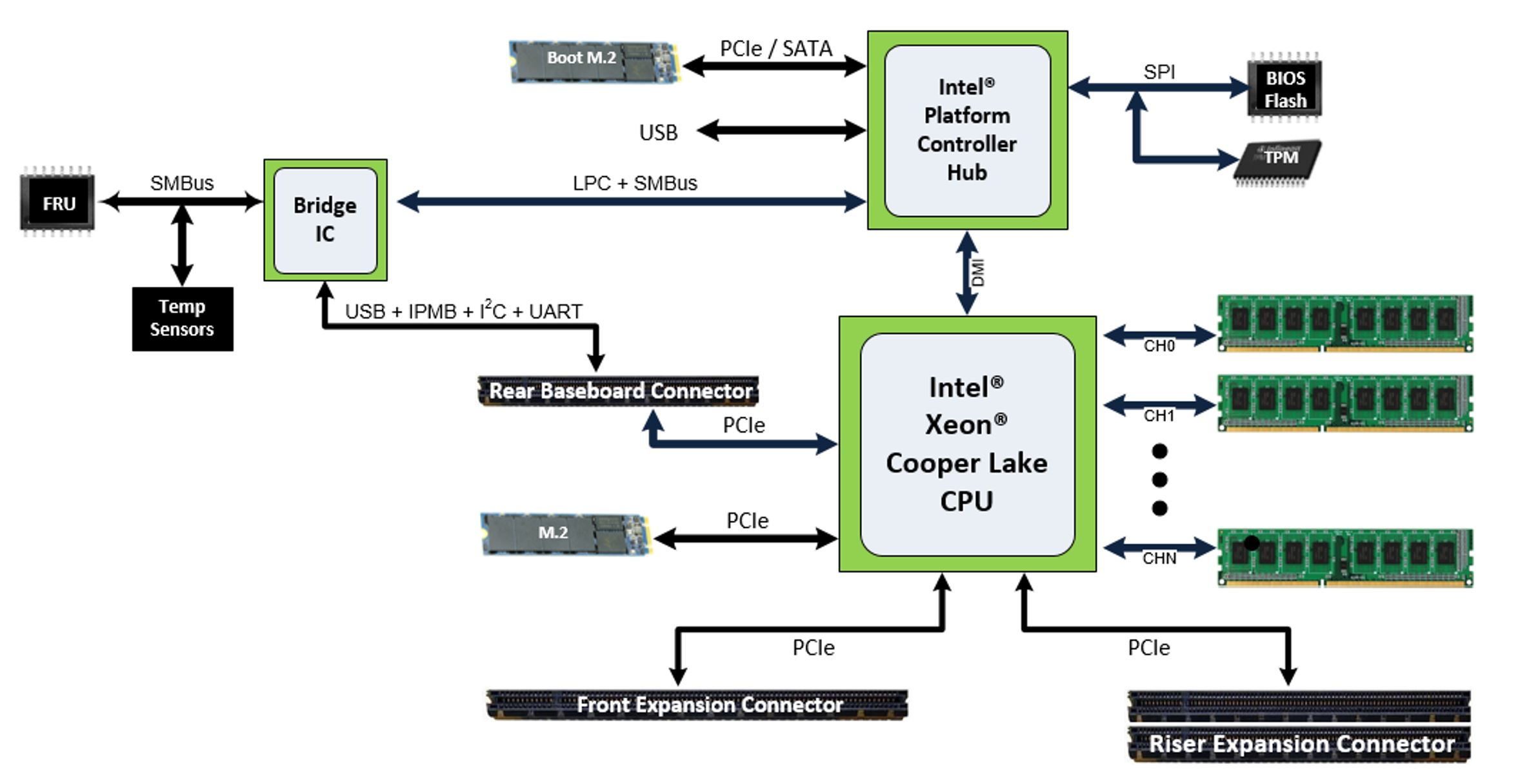
We again see PCIe Gen3 and if we count lanes it looks again like 48x PCIe Gen3 lanes per socket which align with what we are seeing from the Sonora Pass motherboard on the 2-socket side.
PCIe is important. The base web server configuration is focused on delivering a low cost CPU and memory in a single NUMA node. Yosemite V3 can use a multi-host adapter to further minimize costs. From what we understand, this is the most common configuration.

Delta lake can also utilize 4x 22110 M.2 form factor devices (SSDs or accelerators) with a multi-host NIC. The PCIe connectors can be used to increase the height of the solution to 2OU which adds room for more expansion of up to 6x M.2 22110 (110mm) devices.
Facebook Yosemite V3
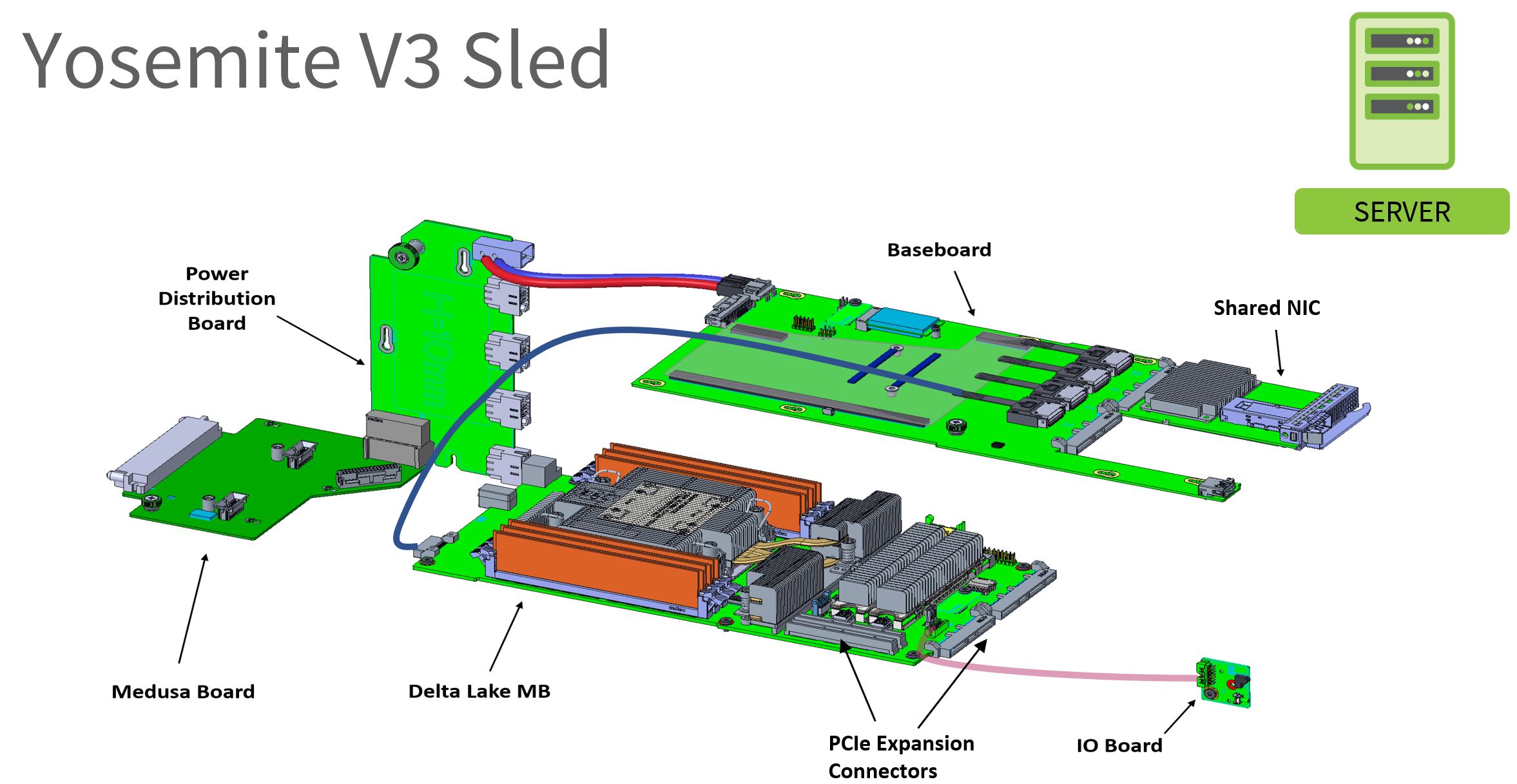
Here is what the assembly looks like with the Yosemite V3 chassis. You can see the Delta Lake motherboard at the bottom of the 4OU 1/3 width chassis. Each chassis can hold up to four Delta Lake nodes which gives up to 96 nodes per rack.

We can see there that the Delta Lake sled is in the webserver configuration. It does not have a dedicated NIC and instead, it is connected to the top baseboard which has a multi-host adapter. This has been a hallmark of Yosemite designs even as they have evolved.
Putting the above into some context removing the sheet metal and fans, one can see the Delta Lake motherboard with the baseboard and MHA above.
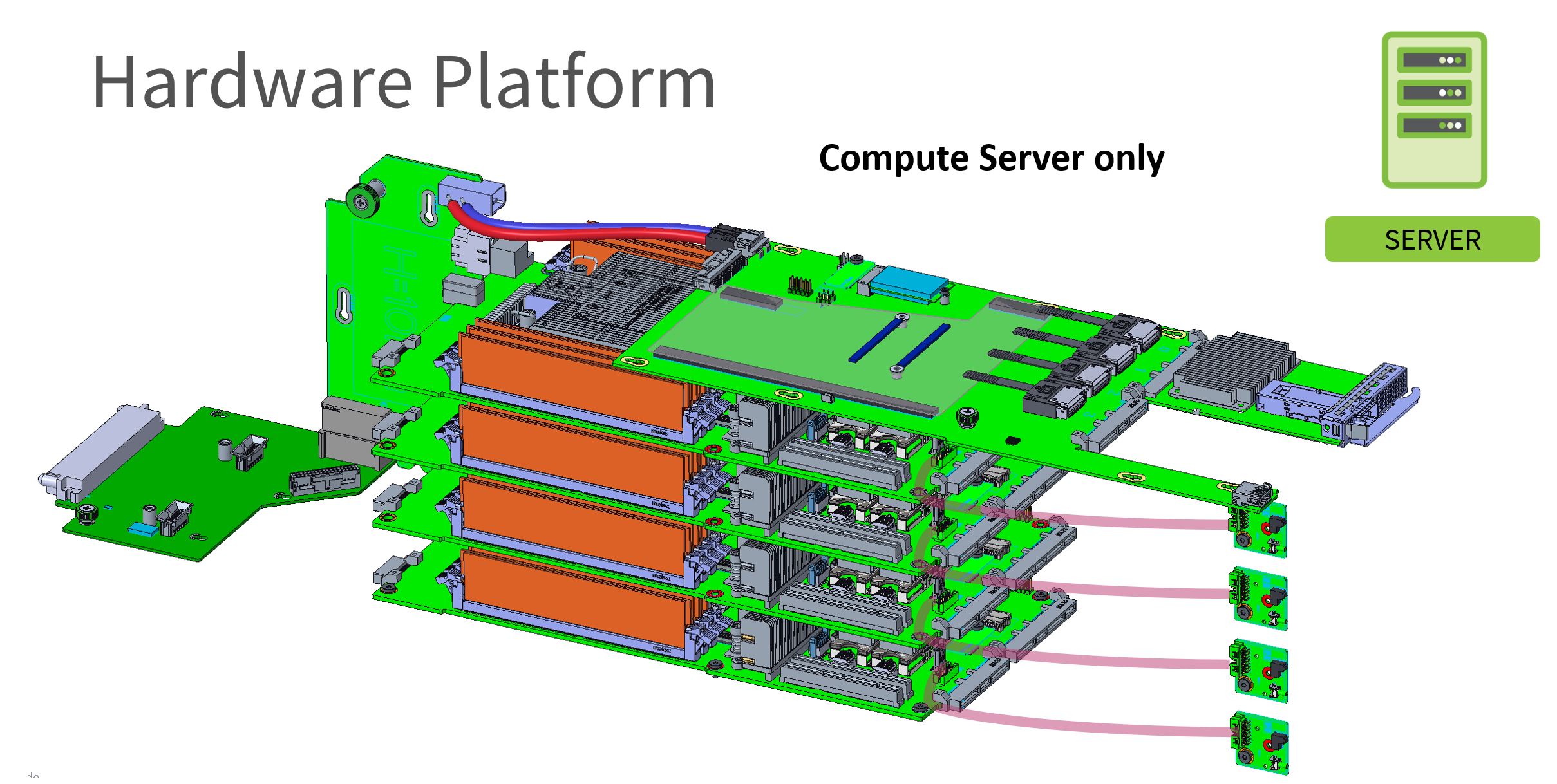
With four of these, one can see the “Compute Server” configuration.
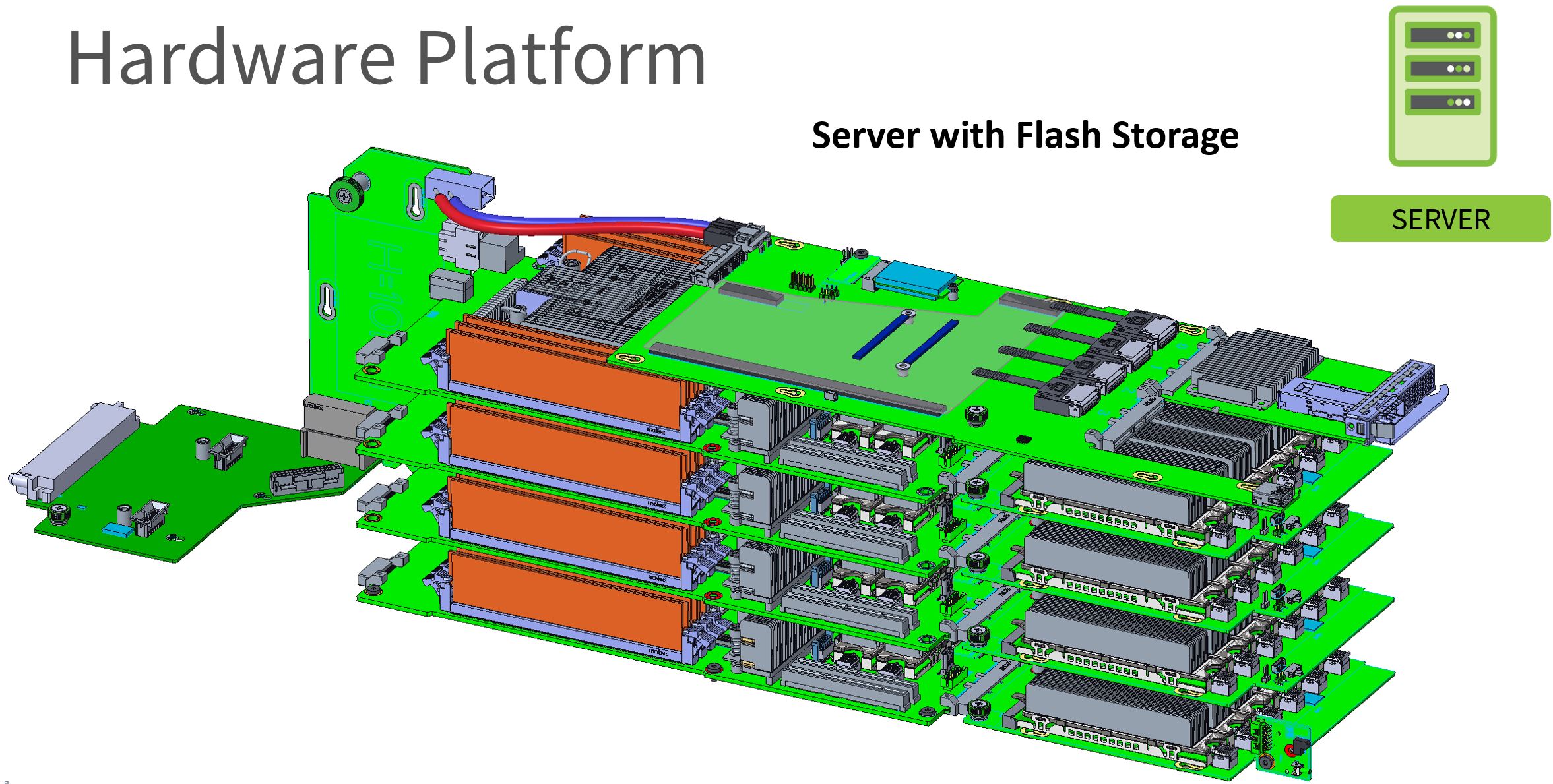
The base Delta Lake motherboard can be extended with a multiple M.2 (6x shown) board for flash storage and utilize a shared NIC.
Facebook can use the PCIe riser slots on the Delta Lake motherboard and use more PCIe expansion for more storage accelerator slots. This puts half of the number of nodes in the Yosemite V3 chassis.
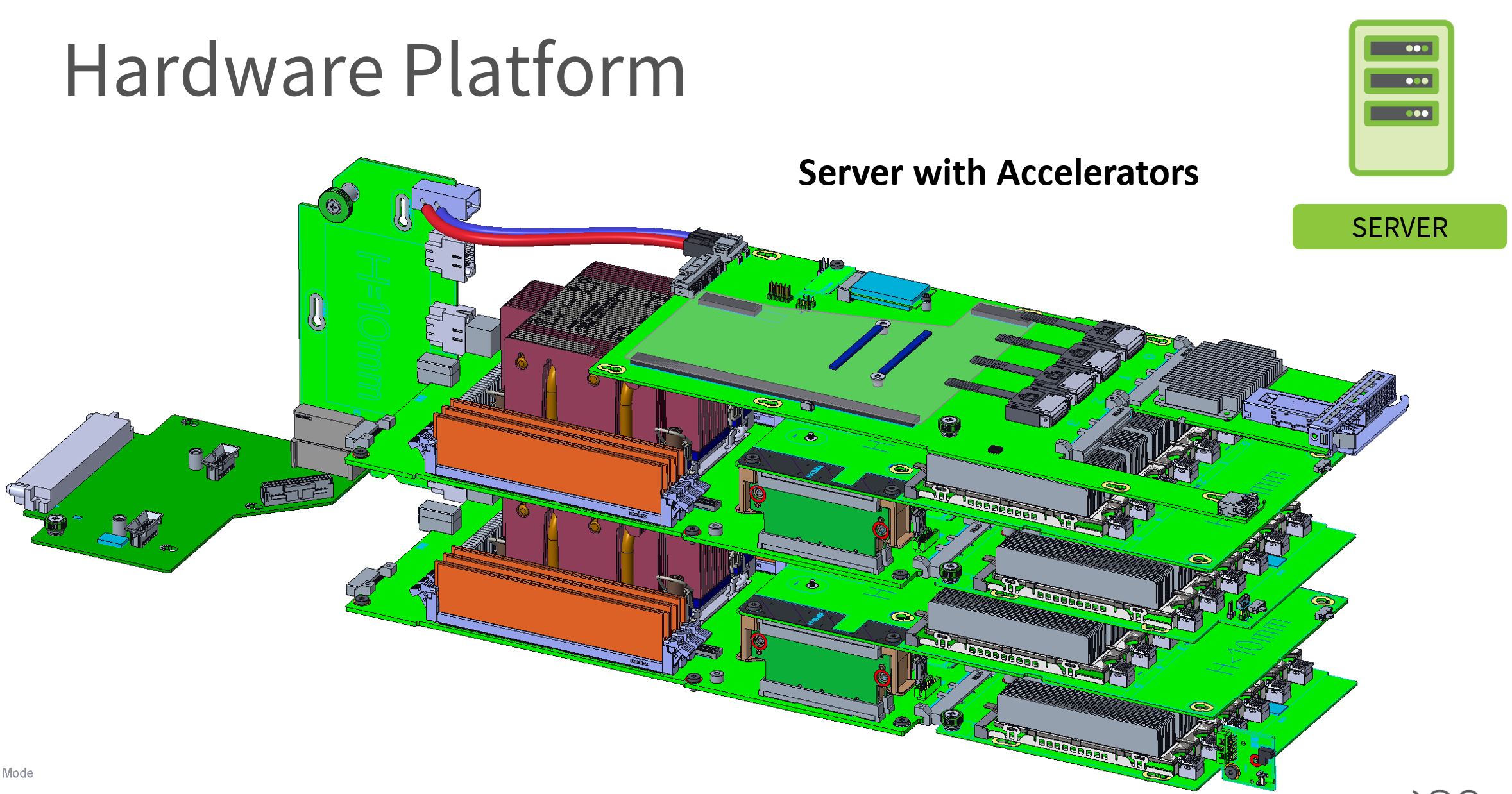
Another option is to have higher-power accelerators with a dedicated NIC for each node. This particular setup uses a 2OU configuration for two nodes per sled as well.
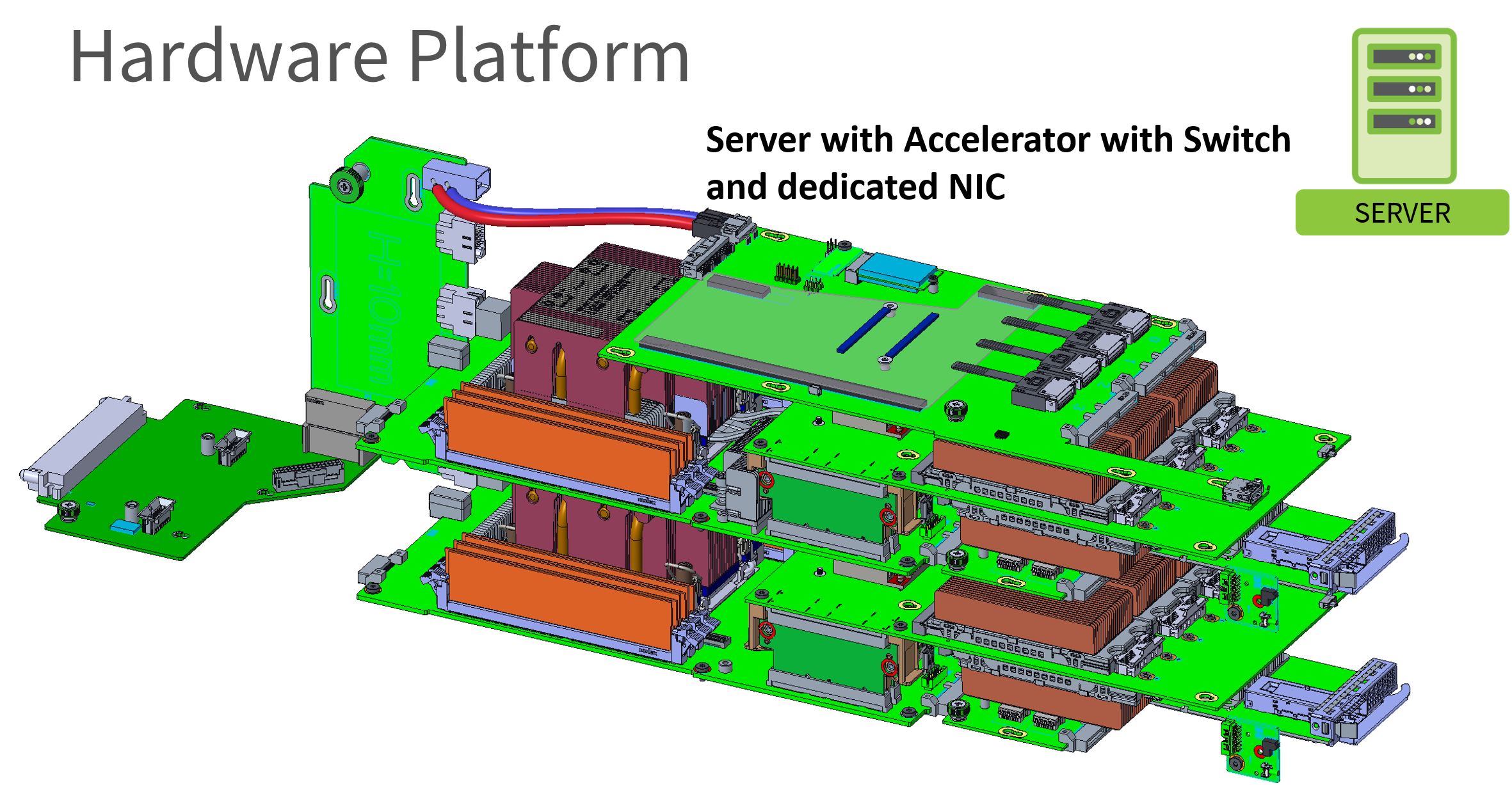
As a quick note here, the Cooper Lake Xeons have an increased heatsink size in 2OU configurations. It also looks like the denser accelerator configurations are being optimized for cooling. This was perhaps done to provide better cooling to these accelerators due to higher TDP than could be handled with the legacy Yosemite V2 design. It also allows servicing nodes easily without having to pull the entire sled so there are some very practical improvements.
That cooling also allows Facebook to add the bfloat16 capable Cooper Lake Xeons, and possibly higher TDP models in 2OU designs. By skipping a “Cascade Lake-D” solution, Facebook can get Barlow Pass DCPMMs that run at DDR4-2933 speeds. One can see how this solution helps unify Facebook’s deployment stack.
Final Words
Intel re-iterated this week that Cooper Lake was coming “soon” in its OCP 2020 keynote by Jennifer Huffstetler. Intel committed to a 2Q 2020 release which means it has a 45-day or so release window remaining.
We tried to show off the Cooper Lake platform and how Facebook is using it. Facebook may be the largest single customer for Cooper Lake Xeons so it is very interesting to see how the company is using the new architecture to unify lower-end 1 socket and higher-end deployment scenarios. That keeps with the theme that Facebook is using the same ISA in Yosemite and larger platforms.
We will, of course, have more details as we can share them on Cooper Lake. Stay tuned to STH for more.
Also, for the Facebook engineering team taking photos. Please feel free to reach out. I am happy to help you take better photos of this gear.



{kind=link}
“but it has at least one killer feature: bfloat16” no, it’s not because Intel hasn’t GPU ready so they added it in CPU side; it’s already available in GPU : Radeon instinct and Nvidia
flo Weird way to look at it, Intel has other BF16 products available like Nervana & products from Habana Labs, why would they need a GPU for that type of workload? Makes no sense. If their customers want BF16 they are better of buying products that is optimized for BF16 workloads, a TPU style products is way more powerful than a GPU that only have a small part of it die dedicated to BF16 instructions, also, Instinct seems to only have BF16 available for ROCm(?)
And Intel expanding the BF16 options to more customers through AVX-512 on their CPU is not a bad thing. It has nothing to do with Intel not having a GPU ready. So yes, it is a killer feature to have it available on the CPU so it’s available to customers without them having to buy a compromised GPU or expensive ASIC/TPU/etc
At one point Intel was planning to fill a bunch of m.2 slots with NNP-I chips. Any word about FB still using those chips?
Are CPUs with avx512 bf16 vector processing more efficient than GPUs on some training operations using sparse datasets in FB’s Zion platform?
The rumors are that AMD is also adding AVX512 in zen4. I haven’t seen they are adding bf16, but seems like they’d want their cpus to be considered for FB servers.
This is a paper on the FB Zion training platform.
https://arxiv.org/pdf/2003.09518.pdf
Interested in knowing what options Facebook will have for accelerators in M.2 form factor. Also Facebook seems to be a diehard advocator for M.2 carrier of SSDs.
It seems weird to me comparing this to Skylake-D. Why would you need bfloat16 in a webserver, why would you want multiple NUMA nodes?
probably to do ML on the edge
They want to use the spare cycles of the web servers when it is the night in the region to help for the ML training.
“By skipping a “Cascade Lake-D” solution, Facebook can get Barlow Pass DCPMMs that run at DDR4-2933 speeds. One can see how this solution helps unify Facebook’s deployment stack.”
There is speculation that Barlow Pass (gen 2 DCPMM) doubles gen 1 max capacity to 1TB per stick … also that it can go do 3200MT/sec. Perhaps this memory capacity feature is becoming more attractive as models keep growing.
https://www.theregister.co.uk/2019/09/26/intel_gen_2_optane/
is that single NIC doing virtual functions to support the networking of many nodes behind it?
“Cascade Lake will support the new Barlow Pass Intel Optane DCPMMs which are the next-generation of DCPMMs …”
Should be “Cooper Lake will support …”