
Facebook took the stage at OCP Summit 2018 and started with answering the question: why are they still engaged in the Open Compute Project in 2018. The reason is that Facebook “wants to go fast.” Part of that includes the refresh of Yosemite V2 platforms on the compute side and new storage options. The major discussion was around the company’s thirst for bandwidth.

The Facebook Fabric Aggregator
One of the challenges Facebook is facing is not just growth from sources like the 2.1 billion Facebook users plus a few billion more messenger, WhatsApp, and Instagram users. Instead, traffic is growing rapidly inside the data center. Here is a snap of what Facebook presented. Apologies for the angle, we were 4 rows in front of the presenters in the dead middle but these presentations were offset on a significant angle.

Key to the Facebook Internal traffic growth is all of the storage traffic as well as the deep learning traffic that Facebook is leveraging. Although the chart did not have values, it is generally accepted that in 2018 Facebook pushes a lot of traffic over its network.
Specifically, Facebook needed a solution for pushing data between buildings (East-West) and to and from its data centers to the outside world (North-South).
Previously, Facebook’s answer was to purchase the largest chassis switches it could find. During the presentation, Facebook said it was using chassis switches with 512-576 ports of 100GbE, but needed 3x more ports than that.
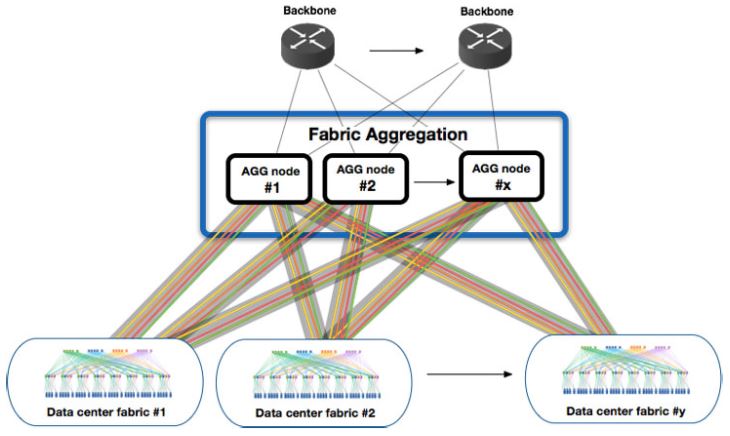
Its solution, somewhat unsurprisingly, is to use the Wedge 100S switch plus its FBOSS software and use a cable backplane to build a massive switch.
By combining multiple “off the shelf” 100GbE switches, Facebook is able to create a relatively inexpensive solution that scales. Although the OCP Summit 2018 example is a single rack, we were told that they can scale to multi-rack solutions. This single rack “only” had 1024x 100GbE ports.

The other advantage of this design is that it allows Facebook to use different cabling options which has a direct impact on costs and power consumption.

Here is a diagram of how the Facebook Fabric Aggregator is moving East-West and North-South bandwidth through the cluster of switches which can push over 2.5PB of traffic per second.
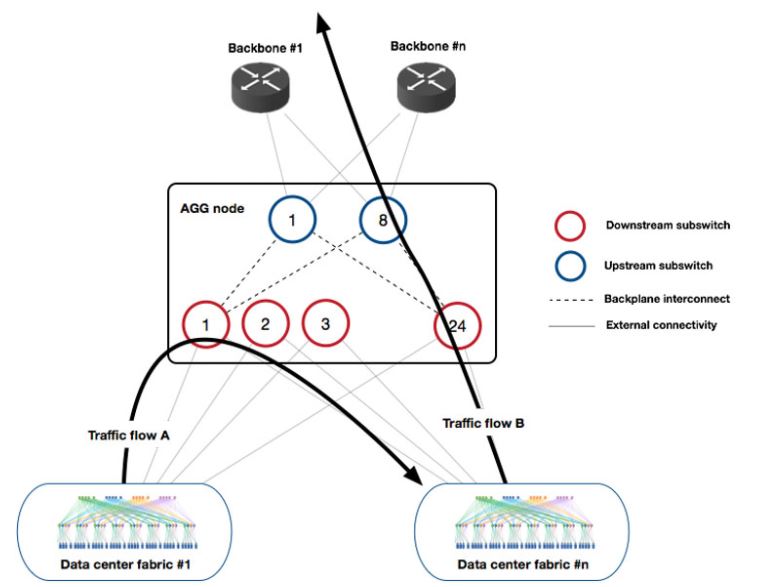
This solution is being contributed to the OCP community and you can read more about it on the Facebook site.
What is Next for Facebook Networking
The big talk at OCP Summit 2018 was not around 100GbE networking. Instead, the community is looking forward to the 400GbE generation.

With a thirst for bandwidth and an infrastructure built upon 1U switches, Facebook is looking at the 400GbE generation and seeing challenges in terms of power consumption and optics for the 400GbE generation.
One of the concepts Facebook seems interested in is co-packaging optics with the switch ASIC. Just before the Facebook talk, Andy Bechtolsheim was on stage presenting this as a concept for the 400GbE generation.

It seems that to solve both the power consumption and availability issues that Facebook and others are seeing with the 100GbE generation that the hyper-scale community is seriously looking at co-packaging laser sources and ASICs and moving away from pluggable optics.



{kind=link}
Yeah, but if you remove the Cambridge Analytics component out of the “Facebook Internal” network growth graph it’s all flat.
joke!! (or is it?)
Also, it’s hard to comment without seeing the scales on the graph, but if there’s little or no growth in Facebook-Internet traffic how is it that they claim an increasing userbase?
Or is this the *rate* of growth, and therefore flat means linear growth?