Hands-on Ingrasys ES2000 and Kioxia EM6 NVMeoF SSD Setup
Perhaps one of the coolest features of the Ingrasys ES2000 system is that the switches are running SONiC. This is a fully software-defined networking solution running on both switches. Highlighted we have 25GbE links to various EM6 SSDs.
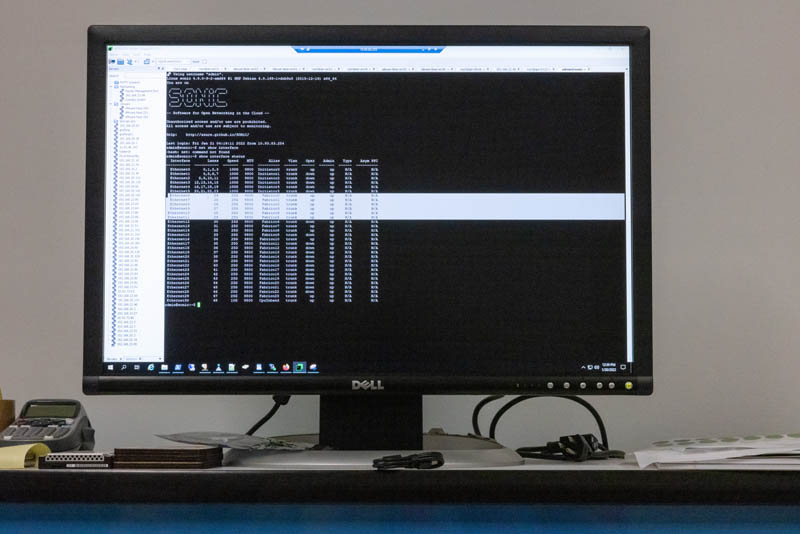
Another fun fact is that because the drives are network-based, we can not just ping, but also Telnet into them. These have a very limited terminal, but it is useful for the lab to be able to do things like manage firmware updates.
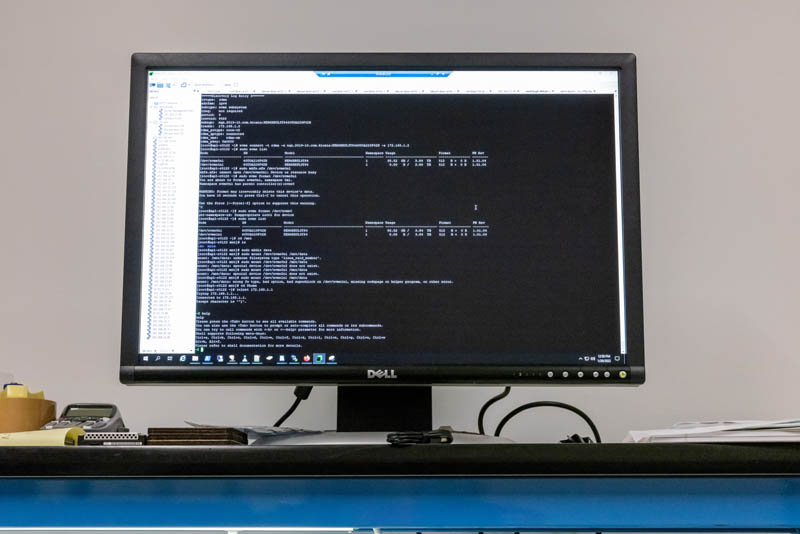
Next, we set up a single drive. We can see that we go from no NVMe devices in the workstation and can discover the EM6 devices over the network.
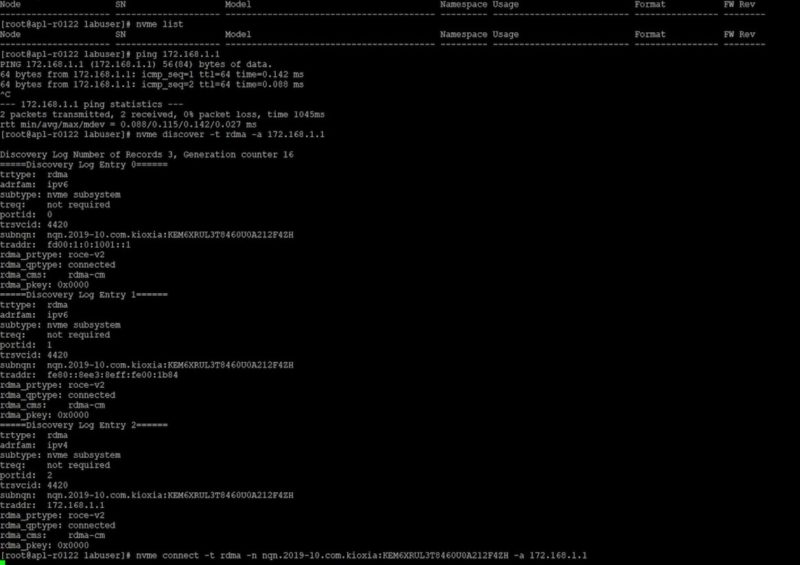
We can then connect to the drive, mount the NVMeoF drive, make a filesystem, and then start transferring data to it.
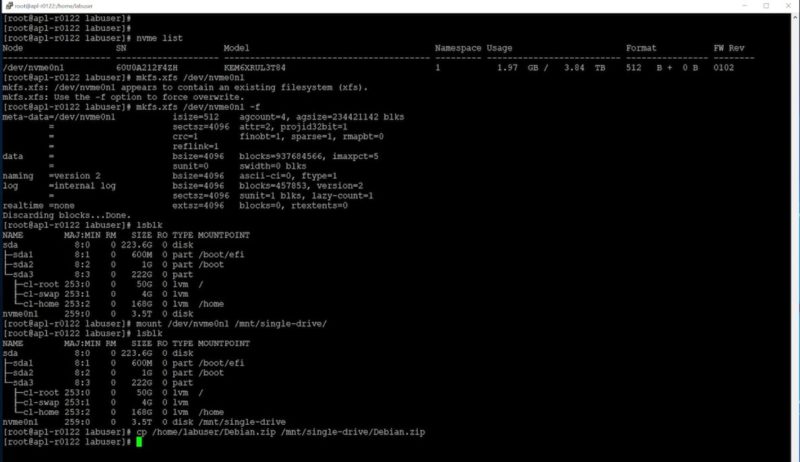
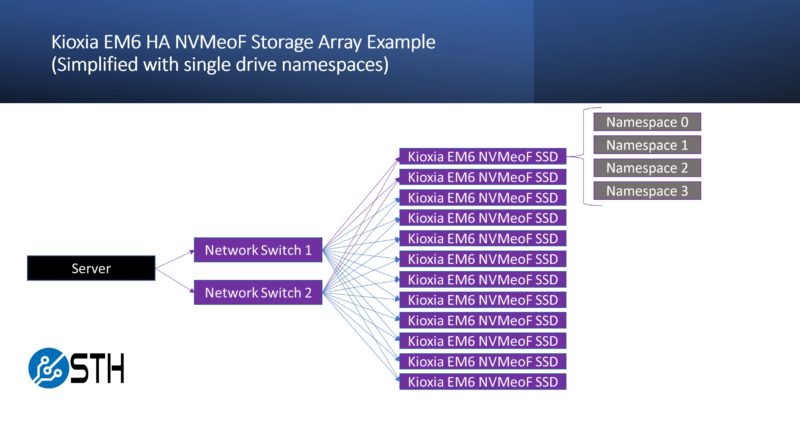
One drive is fun, but we can also do the same with more drives. Next, we are doing it with 23x 3.84TB EM6 SSDs. A script error prevented the 24th drive from being added.
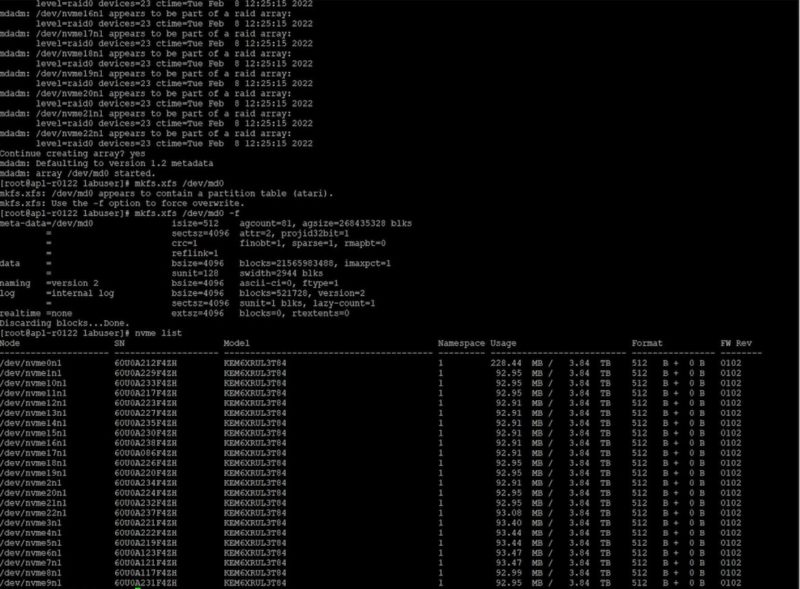
These 23 drives we can then RAID 0, make a file system, and mount for over 80TB usable.
From here, we can start transferring data that is then striped across the drives on the network. In this case, all of the drives were in the same chassis, but since it is an IP network, there is little reason they could not be connected across multiple chassis, racks, and rows in a data center.
Next, let us get to the “so what” of this.
Why This Matters for the Future of Network Storage
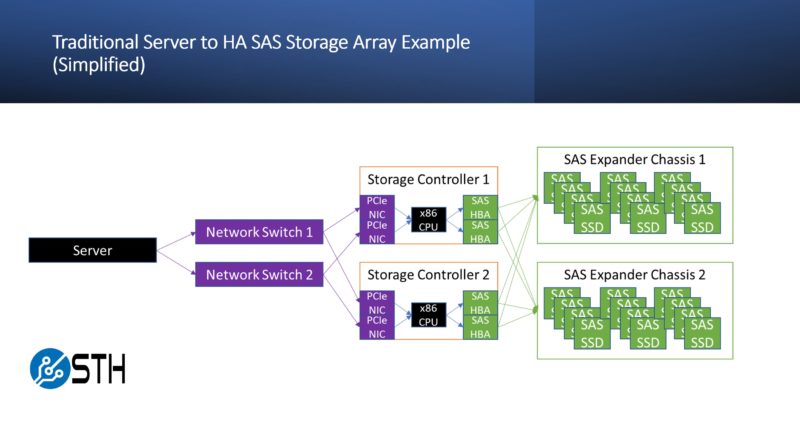
Taking a step back, the idea of having a high-availability SAS storage array seems simple, but there is a lot going on. A server that wants to get data has to send a request via Ethernet. that request is handled by a switch and then goes to the storage controllers. The message is then sent via PCIe to the host CPU, usually an x86 CPU. Then, the x86 CPU needs to determine what to do and then will issue commands over PCIe to a SAS HBA or RAID controller. From there, the SAS command will usually go through a SAS expander and to a SAS SSD. That is a lot of steps actually.
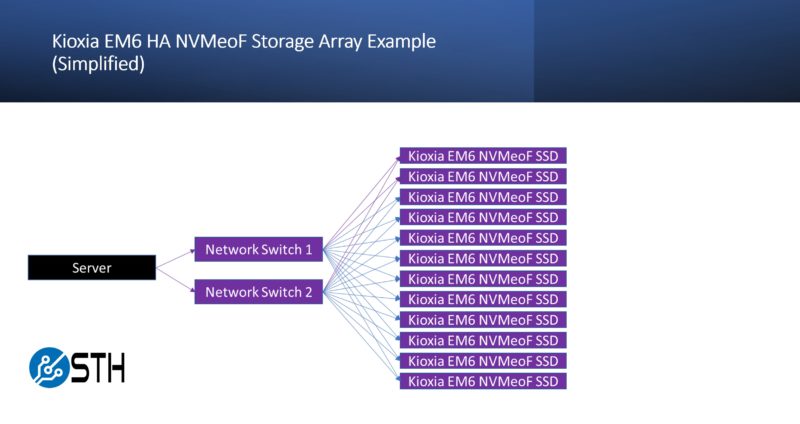
The Kioxia EM6 model, by putting drives directly on the network, means that requests traverse the infrastructure to drives using Ethernet. It also creates fewer “choke points” in the topology because the messaging does not need to go through a storage controller. There is complexity in the networking and management side, but there are entire chunks of complexity being removed by this design. Folks have figured out how to scale IP networks fairly well at this point, and to a larger number of connected devices than SAS/ NVMe arrays.
The real power of this, and something we did not get to show, is when it comes to namespaces. Each drive can be partitioned into multiple smaller namespaces. In our RAID 0 example, imagine, if instead of using one 2TB drive, or 23x 3.84TB drives, the system instead used 100GB namespaces from 23 drives and then had extra capacity for parity. That minimizes the amount of data on a given drive. While it increases the chance that a device will fail, it decreases the impact of a failure for higher reliability. It also means that there is more performance available to saturate NIC bandwidth because data is being pulled from many drives simultaneously.
We are using RAID here for a simple example, but these could be Ceph OSDs, GlusterFS drives or using other storage solutions. To the host system, these look very similar to just normal NVMe SSDs, and that is part of the power.
Final Words
Overall, this is not going to replace all SAS arrays overnight. This is a big technology change. At the same time, it is easy to see the appeal of this style of storage and management to many organizations. Now that devices are becoming available, we will start to see deployments and solutions built around these drives. If I were building a storage startup today, the Koixia EM6 would be a technology I would be very interested in integrating since it provides something different to the market.
Looking forward, the question that should be top of mind is management. That is why the next part in this series will be looking at DPUs and managing the storage provisioning via DPUs so that the infrastructure provider can secure and distribute capacity for solutions like NVMeoF devices. Stay tuned for that.



{kind=link}
Any indication on pricing and availability?
NVMeoF: This all sounds interesting, and perhaps the concrete poured to make my mind has fully cured (my 1st storage task was to write SASI (then SCSI) disk & tape drivers for a proprietary OS)…But how does one take this baseline physical architecture up to the level of enterprise storage array services? (file server, snapshotting, backup, security/managed file access, control head failover, etc)? Hmmmm…Maybe I should just follow the old 1980’s TV show “Soap” tag line “Confused? You won’t be after the next episode of Soap”.
This is really is a lot like SAS, but with Ethernet scale-out. The key thing is that you get the single drive small failure domain.
At one end you could do a 1000+ drive archival system with a few servers that are fully redundant (server failover). At the other end you could put more umph into “controllers” by adding more servers and use storage accelerators like DPUs.
Software defined systems based on plain servers have sizing issues. You spend to much on servers to maintain descent sized failure domains. Even if you decide to add a lot of space to each server, you need a lot of servers to keep the redundancy overhead down (erasure coding). Then you get into a multi PB system before it gets economical. Moving the software to the drives can solve this and given that this is already Ethernet it might not be that far out, but will have cost for on drive processing.
With the good old dual path drive you can start with two servers (controllers) and a 10 drive RAID6 and now scale as far as Ethernet or any other NVMeoF network will take you.
I think this system using erasure coding would be a great pair.
I have done tests of NVMEoF using QDR IB, x4 PCIe3 SSDs and Ryzen 3000 series PCs. Compared to locally attached NVME, NVMEoF had slightly slower POSIX open/close operations and essentially the same read/write bandwidth. Compared to NFS over RDMA, NVMEoF was substantially faster on every metric. So NVMEoF is pretty good, esp if you want to consolidate all your SSDs in one place.
Waiting for the price. Would be so nice to lose the Intel/AMD/ARM CPU tax on storage machines.
Can one NVMEoF device support concurrently access from multiple nodes?
Is each of these limited to 25 GbE (~3 GB/sec?) , with individual breakout cables from a 100 GbE connection? I can see where getting near PCI-e 3.0 NVME speeds from even a single storage drive without even needing host servers would prove interesting!
Very interesting! I wonder why they chose to run a full IP stack on the drives rather than keep it at the Ethernet layer? I suppose it does offer a lot more flexibility, allowing devices to be multiple hops away, but then you have a whole embedded OS and TCP stack on each device to worry about from a security standpoint. I suppose the idea is that you run these on a dedicated SAN, physically separate from the rest of the network?
@The Anh Tran – technically yes, you can mount an NVMEoF device on several hosts simultaneously. But it is in general a risky thing to do.
The different hosts see it as a local block device and assume exclusive access. You’ll run into problems where changes to the filesystem made by one host are not seen by other hosts – very bad stuff.
If all hosts were doing strictly read-only access then it would be safe. I did this to share ML training data amongst a couple of GPU compute boxes. It worked. Later, I tried updating the training data files from one host – the changes were not visible to the other hosts.
If, say, you were sharing DB data files amongst the members of a DBMS cluster via this method you would surely corrupt all your data as each node would have it’s own idea of file extents, record locations, etc. They’d trash each other’s changes.
This does sound interesting, I’m wondering what level of security / access control is provided. One would probably want to encrypt the data locally on the host (possibly using a DPU which could even do it transparently) before writing to the drive.
How much?
https://www.ingrasys.com/es2000
@Malvineous – The first RoCE version was plain ethernet, but they moved to UDP/IP in v2 to make routing possible. All this is handled by the NICs so it can RDMA directly to memory. There is also Soft-RoCE for NICs that does not support it in hardware.
@Hans: Last time I asked HPE for a quote on their J2000 JBOF, I suddenly got the urge to buy two servers with NVMe in the front Hoping that upcoming SAS4 JBODs will be tri-state so we at least can have dual-path over PCIe.
Access control and protocol latency will limit use cases, AC could be performed by the switch fabric eg by MAC or IP
This is truly exciting. I started working on distributed storage back in the days of Servenet, then infiniband, then RDMA over infiniband, then RDMA over ethernet,…
Kioxia has delivered an intelligent design that can be used to disaggregate storage with out the incredibly bad performance impact (latency, io rate, and throughput) of “Enterprise Storage Arrays”. It truly sucks that IT has been forced to put up with the inherent architectural flaws of storage arrays based on design principles from the 1980’s.
I wonder what the power consumption of those controllers ‘per drive’ is, nvme aren’t exactly friendly by themselves to the overall power budget per rack per-se.
Personally I’d like to see NVME get replaced with some of that new nextgen tech Intel were talking of a few years back, though never heard about it again since.
The principle with this tech is sound, the management sounds a real headache, looking forward to seeing how fully fleshed out the ‘software’ side becomes, as in, point-and-click for the sysadmin billing by the minute.
This is nuts. My drives will now run Linux and have dual Ethernet?? Also, makes sense.
Just noticed the trays are much deeper than the present drives. Does this hint at a future(?) drive form-factor?
Too many folks here are still looking at this in the old “x*controllers+disks presented to hosts” fashion. Look at the statement “imagine, if…the system instead used 100GB namespaces from 23 drives”. This is incredibly powerful – picture your VM managing a classic array built from namespace #1. Your next VM has a different array layout on namespace #2, and your DPU is running its own array on namespace #3. You can do old-school arrays, object-type arrays, distributed, or whatever you want all backed by a common set of drives which just need more disks added to the network in order to expand.
The only major issue I see here is all the testing is done using IPv4, which would swiftly run out of addresses if you scale. IPv6 is despised yes, but at least show us it works please.
When can we hope for some performance measures? Latency and rate would be the interesting measures, since they could be compared on the same system and SSD with direct PCIe.