Dual NVIDIA Titan RTX Power Consumption
For our power testing, we used AIDA64 to stress the NVIDIA Titan RTX’s, then HWiNFO to monitor power use and temperatures.
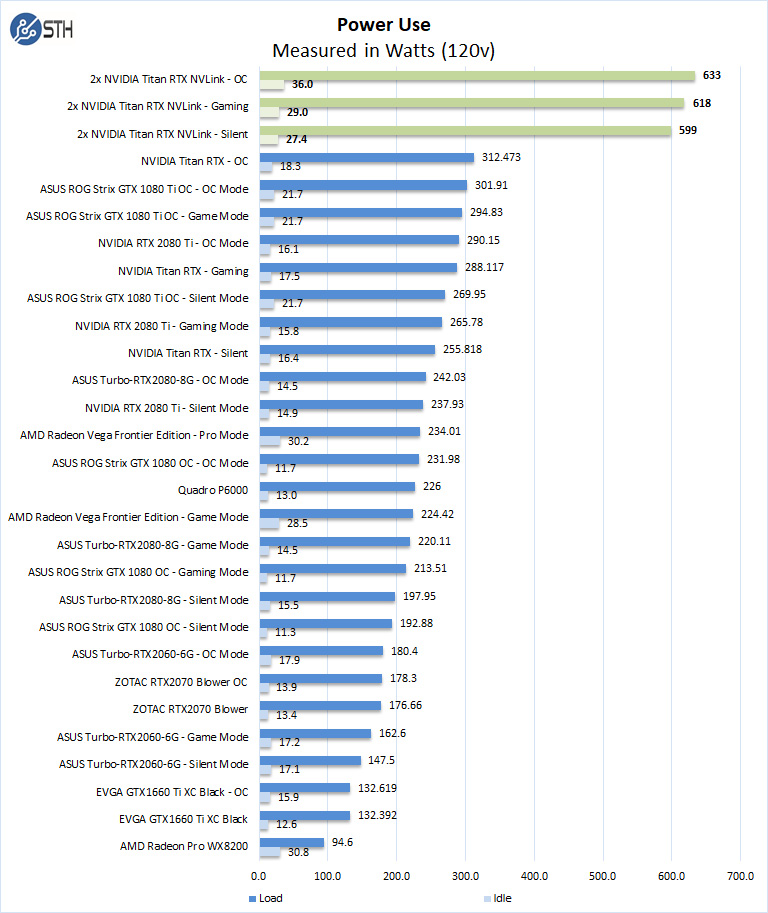
HWiNFO shows us both NVIDIA Titan RTX GPUs running; each Titan RTX will show us different power numbers depending on what each GPU is doing, the primary GPU is usually higher than the secondary GPU. We add the max power numbers of both Titan RTX’s together and then show the results in our graph.
We see the total for both Titan RTX GPUs at 633Watts under full load and 36Watts at idle. It is the most power hungry GPU setup we have tested in this series, yet far lower power than the multi-kW GPU servers we tested. We upgraded our PSU to a Thermaltake Toughpower DPS G RGB 1500W Titanium to be sure we would run clean power to the GPUs. Our bench platform is a dual socket Intel Xeon Scalable system with a large amount of RAM, we felt the need to upgrade the PSU. Keep in mind that for total power draw from the socket we saw numbers as high as 850watts!
A cool feature of the Toughpower DPS G is the monitoring interface which looks like this.
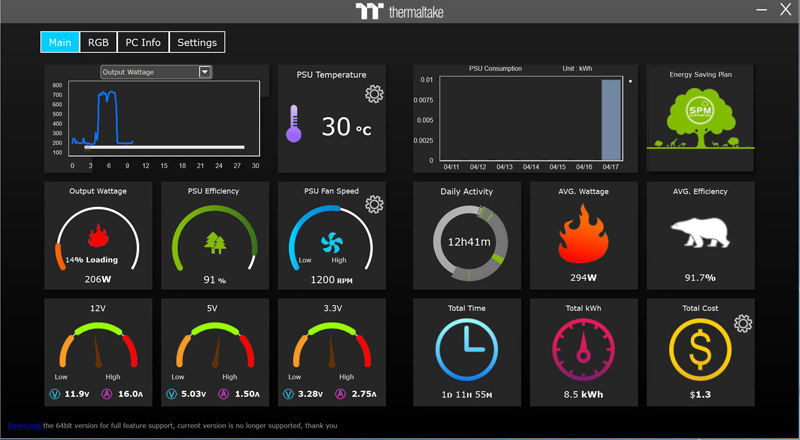
You can enter in your power costs at the far right corner, and it will keep you updated on the running power costs of your system. This is only a windows based PC feature though.
Additionally, with a mobile app, you can monitor the system on your phone.
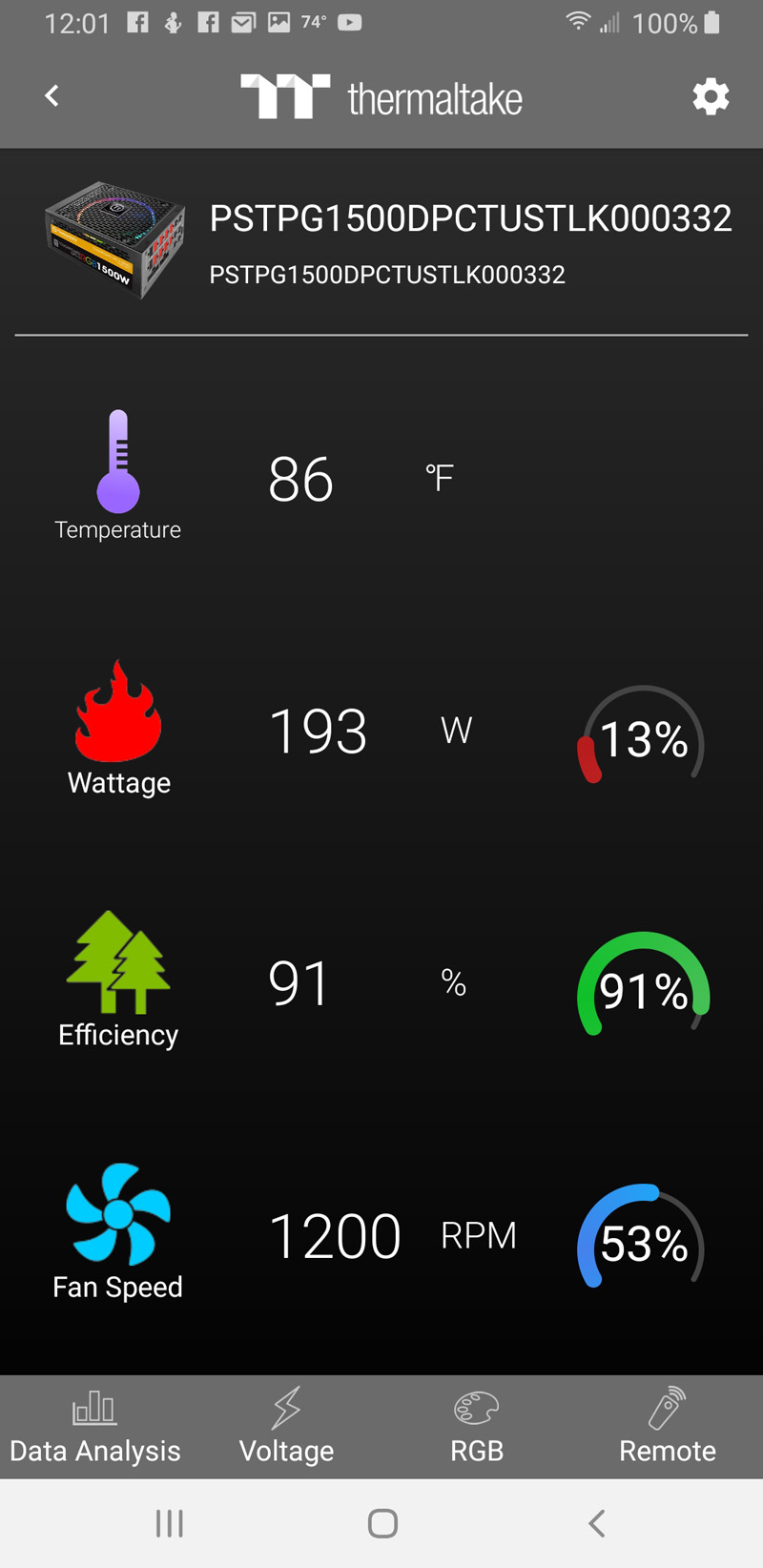
For the IT administrator with several users running dual NVIDIA Titan RTX setups in an office setting, this type of capability may be useful. For the system integrators and VARs that read STH, this may be something to look into for these setups.
Dual NVIDIA Titan RTX Cooling Performance
A key reason that we started this series was to answer the cooling question. Blower-style coolers have different capabilities than some of the large dual and triple fan gaming cards. In the case of the NVIDIA Titan RTX which uses dual fans and huge full-card vapor chamber that spans the entire PCB which cools the GPU rather well. As we are using two Titan RTX’s in this review keeping spacing between the GPU’s is important, hence the reason we used the 4-Slot NVLink Bridge. The Titan RTX’s generate a lot of heat, especially when training so the extra space is important for air-flow.
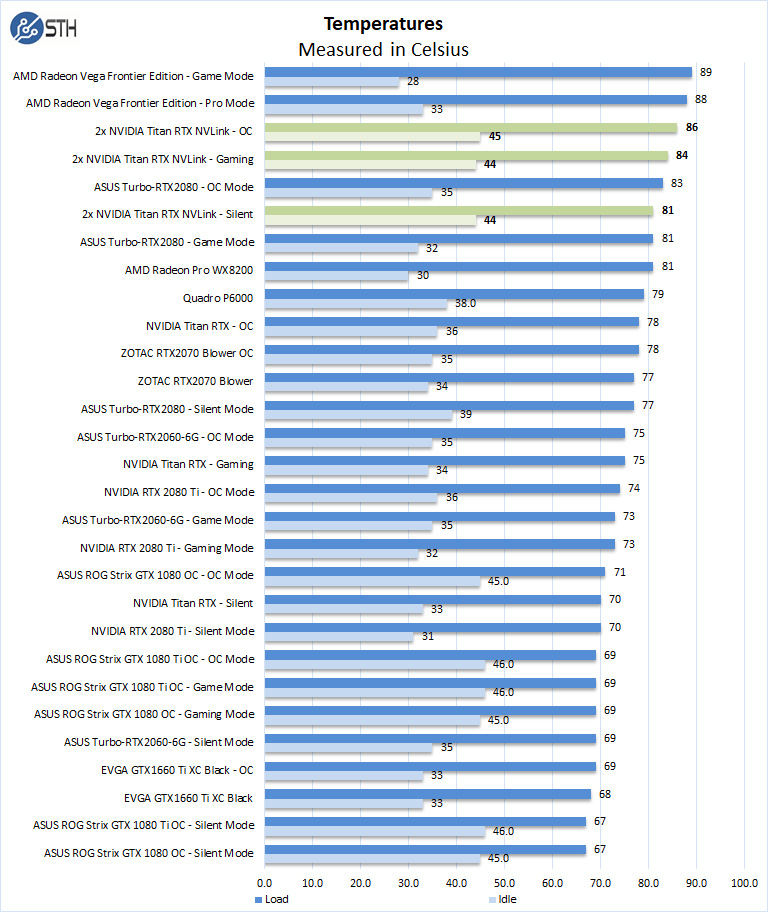
Like the power tests, HWiNFO shows us both NVIDIA Titan RTX GPUs running; each Titan RTX will show us different temperature numbers depending on what each GPU is doing, the primary GPU is usually higher than the secondary GPU. We used the highest temperature for our graphs. Our warmest Titan RTX typically ran 10C higher than our single NVIDIA Titan RTX did.
Final Words
We spent many days benchmarking the dual NVIDIA Titan RTX with NVLink system; it has had its ups and downs. We were a bit disappointed with some benchmarks not fully using these two GPU’s in NVLink. Frankly, that was expected.
Stepping back and looking at what users will be using these cards for, in workstations, dual NVIDIA Titan RTX GPUs with NVLink have a dramatic impact in some situations. For example, rendering performance was superb and that can have a real-world economic benefit. Offsetting the $5.1K plus tax initial purchase is the time saved in heavy render workloads.
Likewise, those innovators doing deep learning training on their workstations will benefit a great deal with the amount of memory and the raw compute power of the solution. Lower-end GPUs simply cannot run some deep learning workloads at reasonable batch sizes. In a workstation where one is constrained by physical machine size, lower-power wall circuits, and acoustics, there is a limit to how many GPUs one can run. Scaling up to two larger GPUs is very reasonable while getting the same performance from four or more GPUs may not be. Make no mistake, if you are a company hiring a deep learning engineer and want to show you are investing in them the dual NVIDIA Titan RTX with NVLink setup makes an excellent impression.



{kind=link}
Incredible ! The tandem operates at 10x the performance of the best K5200 ! This is a must have for every computer laboratory that wishes to be up to date allowing team members or students to render in minutes what would take hours or days ! I hear Dr Cray sayin ” Yes more speed! “
This test would make more sense if the benchmarks were also run with 2 Titan RTX but WITHOUT NVlink connected. Then you’d understand better whether your app is actually getting any benefit from it. NVLink can degrade performance in applications that are not tuned to take advantage of it. (meaning 2 GPUs will be better than 2+NVLink in some situations)
I’m kind of missing the: NAMD Performance.
STH is freaking awesome. Great review William. You guys have got a great dataset building here
Great review yes – thanks !
2x 2080 Ti would be nice for a comparison. Benchmarks not constrained by memory size would show similar performance to 2x Titan at half the cost.
It would also be interesting to see CPU usage for some of the benchmarks. I have seen GPUs being held back by single threaded Python performance for some ML workloads on occasion. Have you checked for CPU bottlenecks during testing? This is a potential explanation for some benchmarks not scaling as expected.
Literally any amd GPU loose even compared to the slowest RTX card in 90% of test…In int32 int64 they don’t even deserve to be on chart
@Lucusta
Yep the Radeon VII really shines in this test. The $700 Radeon VII iis only 10% faster than the $4,000 Quadro RTX 6000 in programs like davinci resolve. It’s a horrible card.
@Misha
A Useless comparison, a pro card vs a not pro in a generic gpgpu program (no viewport so why don’t you say rtx 2080?)… The new Vega VII is compable to rtx quadro 4000 1000$ single slot! (pudget review)…In compute Vega 2 win, in viewport / specviewperf it looses…
@Lucusta
MI50 ~ Radeon VII and there is also a MI60.
Radeon VII(15 fps) beats the Quadro RTX 8000(10 fps) with 8k in Resolve by 50% when doing NR(quadro RTX4000 does 8 fps).
Most if not all benchmarking programs for CPU and GPU are more or less useless, test real programs.
That’s how Puget does it and Tomshardware is also pretty good in testing with real programs.
Benchmark programs are for gamers or just being the highest on the internet in some kind of benchmark.
You critique that many benchmarks did not show the power of nvlink and using pooled memory by using the two cards in tandem. But why did you not choose those benchmarks and even more important, why did you not set up your tensorflow and pytorch test bench to actually showcase the difference between nvlink and one without?
It’s a disappointing review in my opinion because you set our a premise and did not even test the premise hence the test was quite useless.
Here my suggeation: set up a deep learning training and inference test bench that displays actual gpu memory usage, the difference in performance when using nvlink bridges and without, performance when two cards are used in parallel (equally distributed workloads) vs allocating a specific workload within the same model to one gpu and another workload in the same model to the other gpu by utilizing pooled memory.
This is a very lazy review in that you just ran a few canned benchmark suites over different gpu, hence the rest results are equally boring. It’s a fine review for rendering folks but it’s a very disappointing review for deep learning people.
I think you can do better than that. Pytorch and tensorflow have some very simple ways to allocate workloads to specific gpus. It’s not that hard and does not require a PhD.
Hey William, I’m trying to set up the same system but my second GPU doesn’t show up when its using the 4-slot bridge. Did you configure the bios to allow for the multiple gpus in a manner that’s not ‘recommended’ by the manual.
I’m planning a new workstation build and was hoping someone could confirm that two RTX cards (e.g. 2 Titan RTX) connected via NVLink can pool memory on a Windows 10 machine running PyTorch code? That is to say, that with two Titan RTX cards I could train a model that required >24GB (but <48GB, obviously), as opposed to loading the same model onto multiple cards and training in parallel? I seem to find a lot of conflicting information out there. Some indicate that two RTX cards with NVLink can pool memory, some say that only Quadro cards can, or that only Linux systems can, etc.
I am interested in building a similar rig for deep learning research. I appreciate the review. Given that cooling is so important for these setups, can you publish the case and cooling setup as well for this system?
I only looked at the deep learning section – Resnet-50 results are meaningless. It seems like you just duplicated the same task on each GPU, then added the images/sec. No wonder you get exactly 2x speedup going from a single card to two cards… The whole point of NVLink is to split a single task across two GPUs! If you do this correctly you will see that you can never reach double the performance because there’s communication overhead between cards. I recommend reporting 3 numbers (img/s): for a single card, for splitting the load over two cards without NVLink, and for splitting the load with NVLink.