Dual Titan RTX NVLink Deep Learning Benchmarks
As we continue to innovate on our review format, we are now adding deep learning benchmarks. In future reviews, we will add more results to this data set and potentially more workloads. In this review, you will notice that we added the NVIDIA GeForce RTX 2080 Ti and RTX 2080 results since our single NVIDIA Titan RTX Review of an Incredible GPU a few weeks ago.
Some of these benchmarks only use one GPU; they do not take advantage of dual NVIDIA Titan RTX NVLink capabilities. Others scale very well. In some cases, smaller amounts of RAM on lower-end GPUs prevented us from running some benchmarks or limited the batch sizes we used. One of the advantages of the 24GB found on each NVIDIA Titan RTX is that one can run some workloads that lower-end parts cannot.
We are going to start with inferencing, then move on to training.
ResNet-50 Inferencing Using Tensor Cores
ImageNet is an image classification database launched in 2007 designed for use in visual object recognition research. Organized by the WordNet hierarchy, hundreds of image examples represent each node (or category of specific nouns).
In our benchmarks for Inferencing, a ResNet50 Model trained in Caffe will be run using the command line as follows.
nvidia-docker run --shm-size=1g --ipc=host --ulimit memlock=-1 --ulimit stack=67108864 --rm -v ~/Downloads/models/:/models -w /opt/tensorrt/bin nvcr.io/nvidia/tensorrt:18.11-py3 giexec --deploy=/models/ResNet-50-deploy.prototxt --model=/models/ResNet-50-model.caffemodel --output=prob --batch=16 --iterations=500 --fp16
Options are:
–deploy: Path to the Caffe deploy (.prototxt) file used for training the model
–model: Path to the model (.caffemodel)
–output: Output blob name
–batch: Batch size to use for inferencing
–iterations: The number of iterations to run
–int8: Use INT8 precision
–fp16: Use FP16 precision (for Volta or Turing GPUs), no specification will equal FP32
We can change the batch size to 16, 32, 64, 128 and precision to INT8, FP16, and FP32.
The results are in inference latency (in seconds.) If we take the batch size / Latency, that will equal the Throughput (images/sec) which we plot on our charts.
We also found that this benchmark does not use two GPU’s; it only runs on a single GPU. You can, however, run different instances on each GPU using commands like.
```NV_GPUS=0 nvidia-docker run ... &
NV_GPUS=1 nvidia-docker run ... &```
With these commands, a user can scale workloads across many GPU’s. Our graphs show combined totals.
We start with Turing’s new INT8 mode which is one of the benefits of using the NVIDIA Titan RTX.
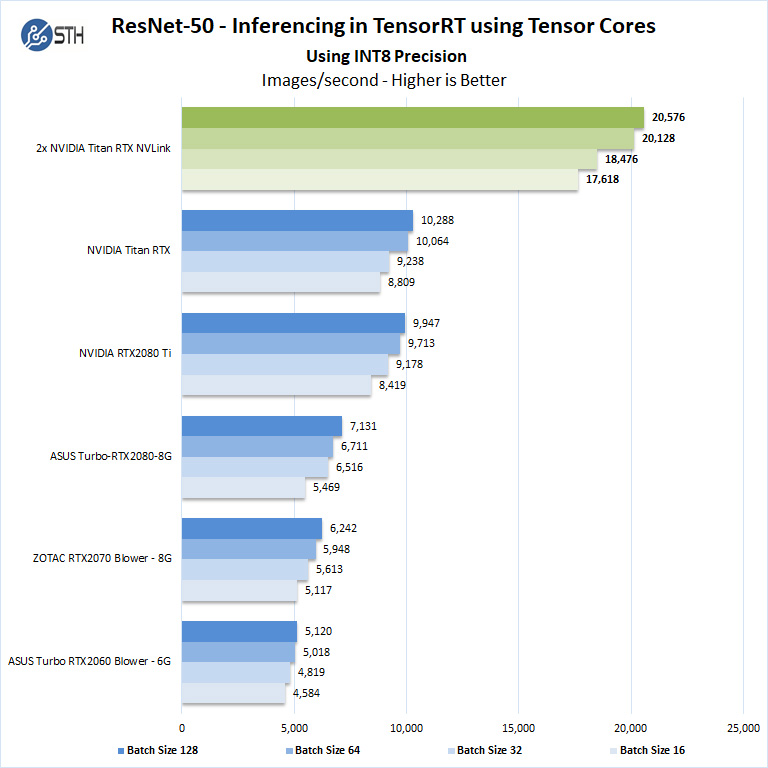
Using precision of INT8 is by far the fastest inferencing method. As we would expect, using larger batch sizes increases performance. We see the NVIDIA GeForce RTX 2080 Ti runs relatively close to the NVIDIA Titan RTX, but there is a benefit to the larger GPU.
Now let us look at FP16 and FP32 results.
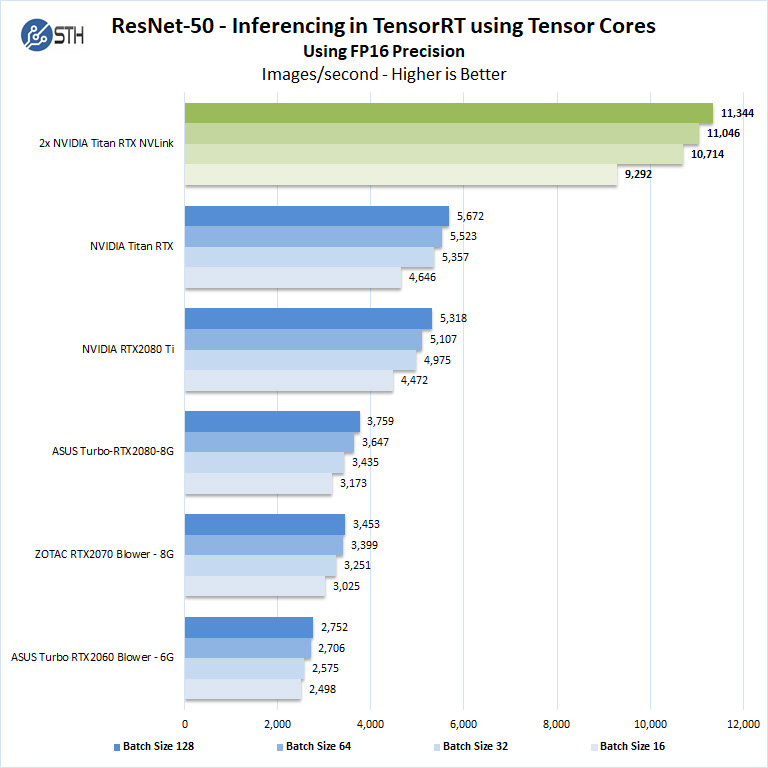
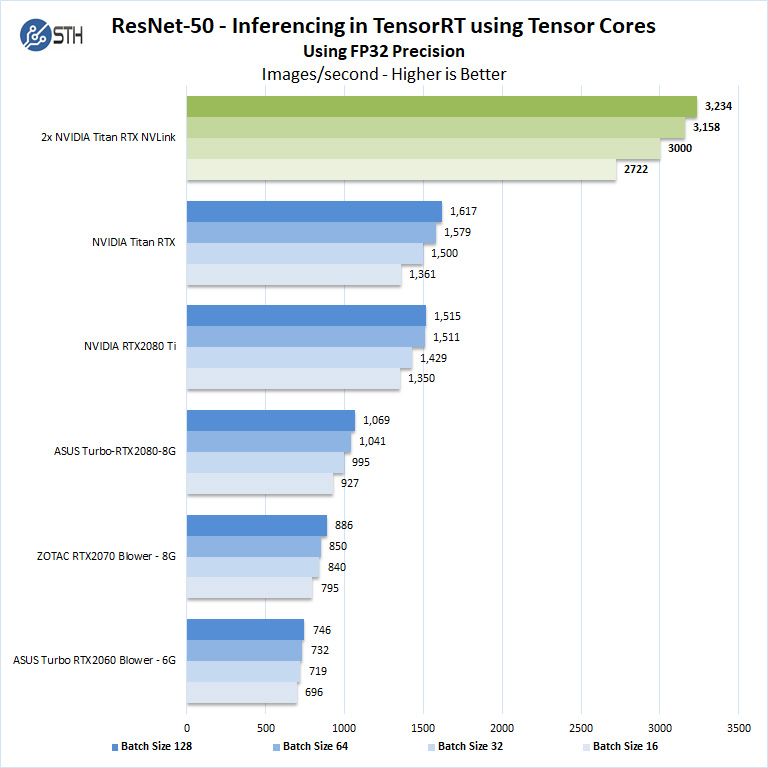
Here again, we see the NVIDIA GeForce RTX 2080 Ti running very close to the NVIDIA Titan RTX. This is not where the main benefits of the Titan RTX and dual Titan RTX GPUs come into play.
Deep Learning Training Using OpenSeq2Seq (GNMT)
While Resnet-50 is a Convolutional Neural Network (CNN) that is typically used for image classification, Recurrent Neural Networks (RNN) such as Google Neural Machine Translation (GNMT) are used for applications such as real-time language translations.
The command line we use for OpenSeq2Seq (GNMT) is as follows.
nvidia-docker run -it --shm-size=1g --ipc=host --ulimit memlock=-1 --ulimit stack=67108864 -v ~/Downloads/OpenSeq2Seq/wmt16_de_en:/opt/tensorflow/nvidia-examples/OpenSeq2Seq/wmt16_de_en -w /workspace/nvidia-examples/OpenSeq2Seq/ nvcr.io/nvidia/tensorflow:18.11-py3
We then open the en_de_gnmt-like-4GPUs.py and edit our variables.
vi example_configs/text2text/en-de/en-de-gnmt-like-4GPUs.py
First, edit data_root to point to the below path:
data_root = "/opt/tensorflow/nvidia-examples/OpenSeq2Seq/wmt16_de_en/"
Additionally, edit the num_gpus, max_steps, and batch_size_per_gpu parameters under
base_prams to set the number of GPUs, run a lower number of steps (i.e. 500) for
benchmarking, and also to set the batch size:
base_params = {
...
"num_gpus": 1,
"max_steps": 500,
"batch_size_per_gpu": 128,
...
},
We also edit lines 44 and below as shown to enable FP16 precision:
#"dtype": tf.float32, # to enable mixed precision, comment this
line and uncomment two below lines
"dtype": "mixed",
"loss_scaling": "Backoff",
We then run the benchmarks as follows.
python run.py --config_file example_configs/text2text/en-de/en-de-gnmt-like-4GPUs.py --mode train
The results will be Avg. Objects per second trained which we plot.
With this benchmark, we change the batch size and enable FP16 precision. When using two NVIDIA Titan RTX NVLink we changed the num_gpus to 2.
We should note that other GPUs we used to like the RTX 2060, RTX 2070, RTX 2080 and RTX 2080 Ti could not complete this benchmark due to the lack of installed memory. To enable this benchmark to finish on these GPU’s one might need to lower the batch size to smaller values like 32, 16, 8. We tried this but had no luck. Using a batch size 4 could be run but it was decided that this was not a very usable size.
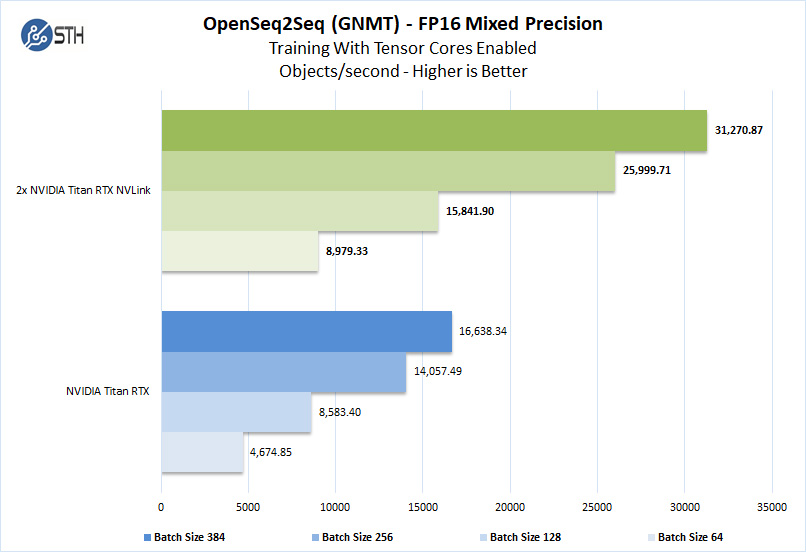
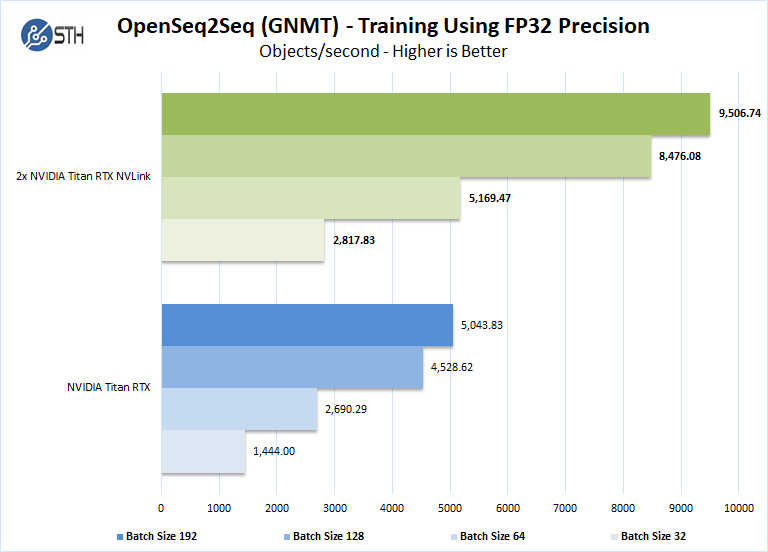
OpenSeq2Seq was a very useful benchmark to run with the dual Titan RTX NVLink setup. For one reason, it is a very memory hungry benchmark which keeps the lower end GPUs from running, and the best reason is it scales with more than one GPU.
Deep Learning Training Using Tensorflow
We also wanted to train the venerable ResNet-50 using Tensorflow. During training the neural network is learning features of images, (e.g. objects, animals, etc.) and determining what features are important. Periodically (every 1000 iterations), the neural network will test itself against the test set to determine training loss, which affects the accuracy of training the network. Accuracy can be increased through repetition (or running a higher number of epochs.)
The command line we will use is:
nvidia-docker run --shm-size=1g --ipc=host --ulimit memlock=-1 --ulimit stack=67108864 -v ~/Downloads/imagenet12tf:/imagenet --rm -w /workspace/nvidia-examples/cnn/ nvcr.io/nvidia/tensorflow:18.11-py3 python resnet.py --data_dir=/imagenet --layers=50 --batch_size=128 --iter_unit=batch --num_iter=500 --display_every=20 --precision=fp16
Parameters for resnet.py:
–layers: The number of neural network layers to use, i.e. 50.
–batch_size or -b: The number of ImageNet sample images to use for training the network per iteration. Increasing the batch size will typically increase training performance.
–iter_unit or -u: Specify whether to run batches or epochs.
–num_iter or -i: The number of batches or iterations to run, i.e. 500.
–display_every: How frequently training performance will be displayed, i.e. every 20 batches.
–precision: Specify FP32 or FP16 precision, which also enables TensorCore math for Volta and Turing GPUs.
While this script TensorFlow cannot specify individual GPUs to use, they can be specified by
setting export CUDA_VISIBLE_DEVICES= separated by commas (i.e. 0,1,2,3) within the Docker container workspace.
We will run batch sizes of 16, 32, 64, 128 and change from FP16 to FP32. Our graphs show combined totals.
Some GPU’s like GeForce RTX 2060, RTX 2070, RTX 2080 and RTX 2080 Ti will not show higher batch size runs because of limited memory.
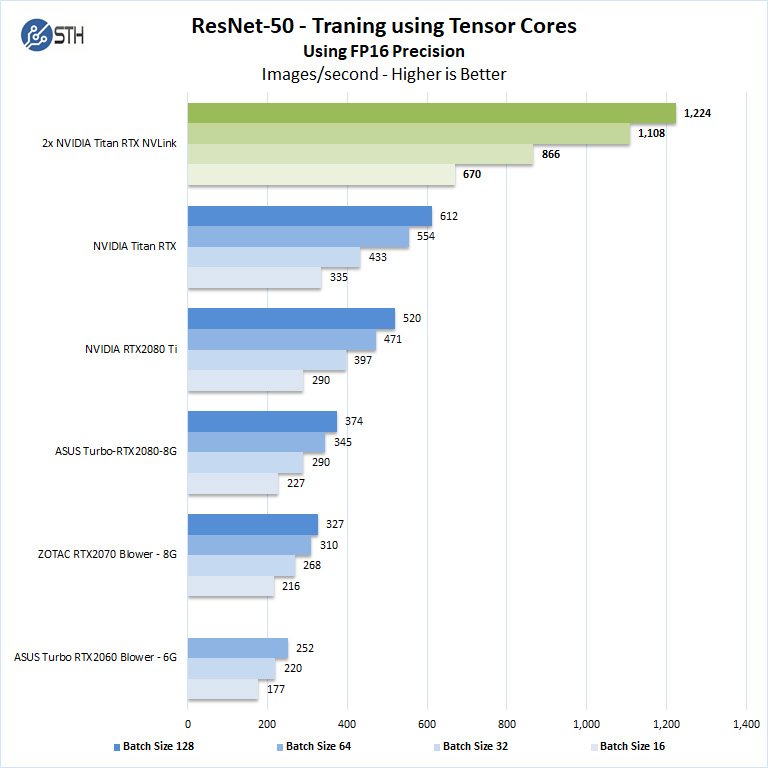
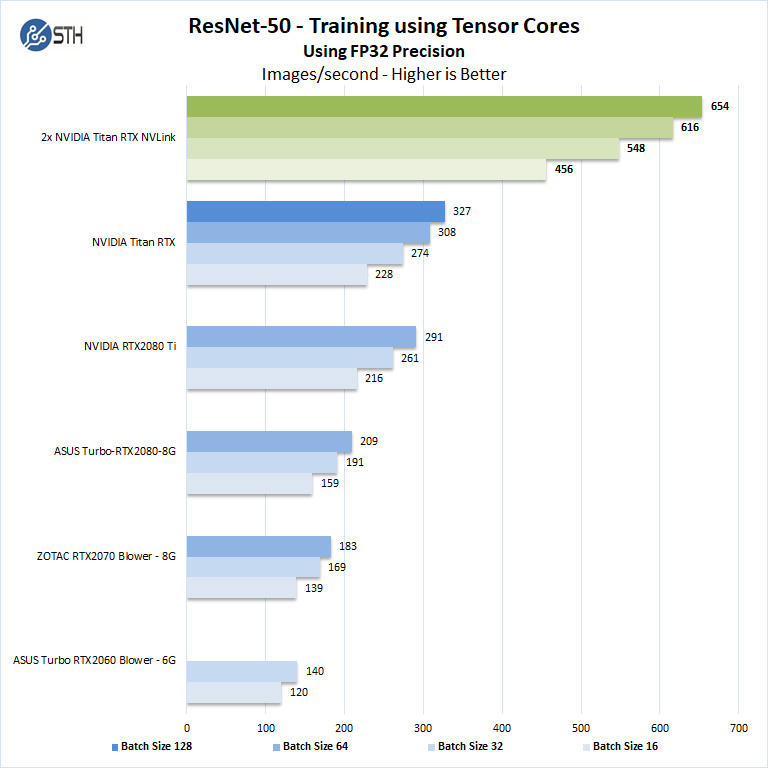
The NVIDIA Titan RTX has an advantage with 24GB memory and can complete all benchmarks, while others can only run lower batch sizes. Using larger batch sizes means more performance as we can see. In turn, that means one can train at even faster paces.
On the desktop side, most systems will be practically limited to 1-2 GPUs. When you have limited capacity for GPUs, having bigger GPUs and scaling up is one of the only practical ways to increase performance.
Next, we are going to look at the dual NVIDIA Titan RTX NVLink power and temperature tests, and then give our final words.



{kind=link}
Incredible ! The tandem operates at 10x the performance of the best K5200 ! This is a must have for every computer laboratory that wishes to be up to date allowing team members or students to render in minutes what would take hours or days ! I hear Dr Cray sayin ” Yes more speed! “
This test would make more sense if the benchmarks were also run with 2 Titan RTX but WITHOUT NVlink connected. Then you’d understand better whether your app is actually getting any benefit from it. NVLink can degrade performance in applications that are not tuned to take advantage of it. (meaning 2 GPUs will be better than 2+NVLink in some situations)
I’m kind of missing the: NAMD Performance.
STH is freaking awesome. Great review William. You guys have got a great dataset building here
Great review yes – thanks !
2x 2080 Ti would be nice for a comparison. Benchmarks not constrained by memory size would show similar performance to 2x Titan at half the cost.
It would also be interesting to see CPU usage for some of the benchmarks. I have seen GPUs being held back by single threaded Python performance for some ML workloads on occasion. Have you checked for CPU bottlenecks during testing? This is a potential explanation for some benchmarks not scaling as expected.
Literally any amd GPU loose even compared to the slowest RTX card in 90% of test…In int32 int64 they don’t even deserve to be on chart
@Lucusta
Yep the Radeon VII really shines in this test. The $700 Radeon VII iis only 10% faster than the $4,000 Quadro RTX 6000 in programs like davinci resolve. It’s a horrible card.
@Misha
A Useless comparison, a pro card vs a not pro in a generic gpgpu program (no viewport so why don’t you say rtx 2080?)… The new Vega VII is compable to rtx quadro 4000 1000$ single slot! (pudget review)…In compute Vega 2 win, in viewport / specviewperf it looses…
@Lucusta
MI50 ~ Radeon VII and there is also a MI60.
Radeon VII(15 fps) beats the Quadro RTX 8000(10 fps) with 8k in Resolve by 50% when doing NR(quadro RTX4000 does 8 fps).
Most if not all benchmarking programs for CPU and GPU are more or less useless, test real programs.
That’s how Puget does it and Tomshardware is also pretty good in testing with real programs.
Benchmark programs are for gamers or just being the highest on the internet in some kind of benchmark.
You critique that many benchmarks did not show the power of nvlink and using pooled memory by using the two cards in tandem. But why did you not choose those benchmarks and even more important, why did you not set up your tensorflow and pytorch test bench to actually showcase the difference between nvlink and one without?
It’s a disappointing review in my opinion because you set our a premise and did not even test the premise hence the test was quite useless.
Here my suggeation: set up a deep learning training and inference test bench that displays actual gpu memory usage, the difference in performance when using nvlink bridges and without, performance when two cards are used in parallel (equally distributed workloads) vs allocating a specific workload within the same model to one gpu and another workload in the same model to the other gpu by utilizing pooled memory.
This is a very lazy review in that you just ran a few canned benchmark suites over different gpu, hence the rest results are equally boring. It’s a fine review for rendering folks but it’s a very disappointing review for deep learning people.
I think you can do better than that. Pytorch and tensorflow have some very simple ways to allocate workloads to specific gpus. It’s not that hard and does not require a PhD.
Hey William, I’m trying to set up the same system but my second GPU doesn’t show up when its using the 4-slot bridge. Did you configure the bios to allow for the multiple gpus in a manner that’s not ‘recommended’ by the manual.
I’m planning a new workstation build and was hoping someone could confirm that two RTX cards (e.g. 2 Titan RTX) connected via NVLink can pool memory on a Windows 10 machine running PyTorch code? That is to say, that with two Titan RTX cards I could train a model that required >24GB (but <48GB, obviously), as opposed to loading the same model onto multiple cards and training in parallel? I seem to find a lot of conflicting information out there. Some indicate that two RTX cards with NVLink can pool memory, some say that only Quadro cards can, or that only Linux systems can, etc.
I am interested in building a similar rig for deep learning research. I appreciate the review. Given that cooling is so important for these setups, can you publish the case and cooling setup as well for this system?
I only looked at the deep learning section – Resnet-50 results are meaningless. It seems like you just duplicated the same task on each GPU, then added the images/sec. No wonder you get exactly 2x speedup going from a single card to two cards… The whole point of NVLink is to split a single task across two GPUs! If you do this correctly you will see that you can never reach double the performance because there’s communication overhead between cards. I recommend reporting 3 numbers (img/s): for a single card, for splitting the load over two cards without NVLink, and for splitting the load with NVLink.