NVIDIA GeForce RTX 3090 NVLink Deep Learning benchmarks
Before we begin, we wanted to note that over time we expect performance to improve for these cards as NVIDIA’s drivers and CUDA infrastructure matures.
ResNet-50 Inferencing in TensorRT using Tensor Cores
ImageNet is an image classification database launched in 2007 designed for use in visual object recognition research. Organized by the WordNet hierarchy, hundreds of image examples represent each node (or category of specific nouns).
In our benchmarks for Inferencing, a ResNet50 Model trained in Caffe will be run using the command line as follows.
nvidia-docker run --shm-size=1g --ipc=host --ulimit memlock=-1 --ulimit stack=67108864 --rm -v ~/Downloads/models/:/models -w /opt/tensorrt/bin nvcr.io/nvidia/tensorrt:20.11-py3 trtexec --deploy=/models/ResNet-50-deploy.prototxt --model=/models/ResNet-50-model.caffemodel --output=prob --batch=16 --iterations=500 --fp16
Options are:
–deploy: Path to the Caffe deploy (.prototxt) file used for training the model
–model: Path to the model (.caffemodel)
–output: Output blob name
–batch: Batch size to use for inferencing
–iterations: The number of iterations to run
–int8: Use INT8 precision
–fp16: Use FP16 precision (for Volta or Turing GPUs), no specification will equal FP32
We can change the batch size to 16, 32, 64, 128 and precision to INT8, FP16, and FP32.
The results are Inference Latency (in sec).
If we take the batch size / Latency, that will equal the Throughput (images/sec) which we plot on our charts.
We also found that this benchmark does not use two GPUs; it only runs on a single GPU.
You can, however, run different instances on each GPU using commands like.
“`NV_GPUS=0 nvidia-docker run … &
NV_GPUS=1 nvidia-docker run … &“`
With these commands, a user can scale workloads across many GPUs.
Also one can use the —device=0,1,2,3,4,… a command to select which GPU to run on, more on this later.
We start with INT8 mode.
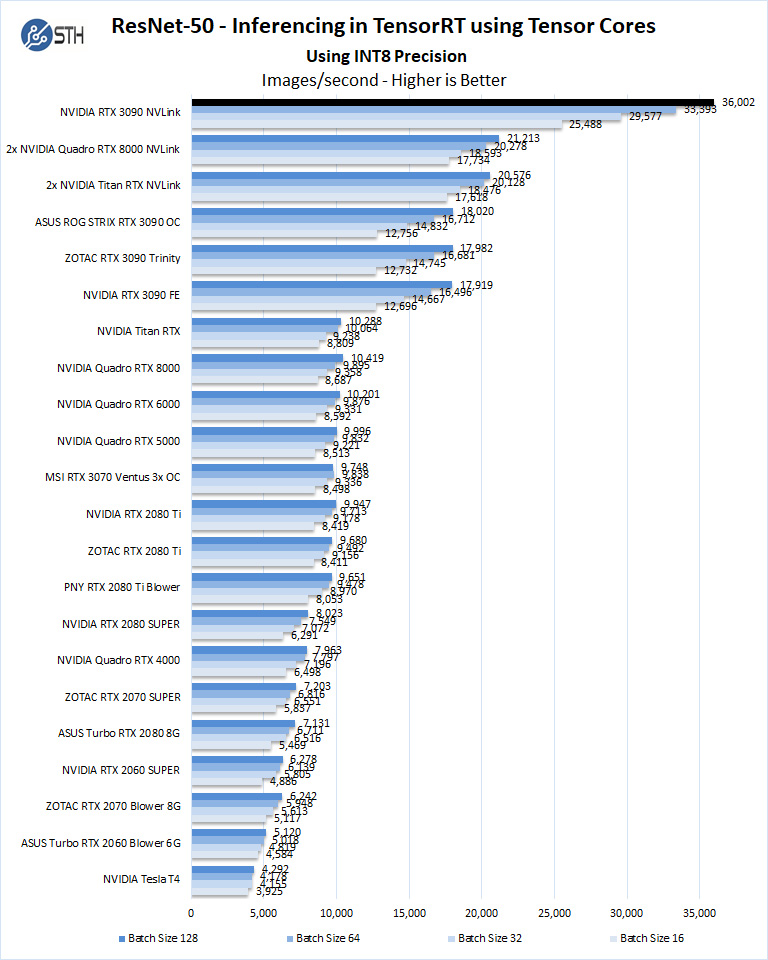
Deep Learning is where a dual GeForce RTX 3090 configuration will shine. Here we will see nearly double the results of a single RTX 3090, and with SLI configurations, it will easily outperform all other configurations we have used to date.
Let us look at FP16 and FP32 results.
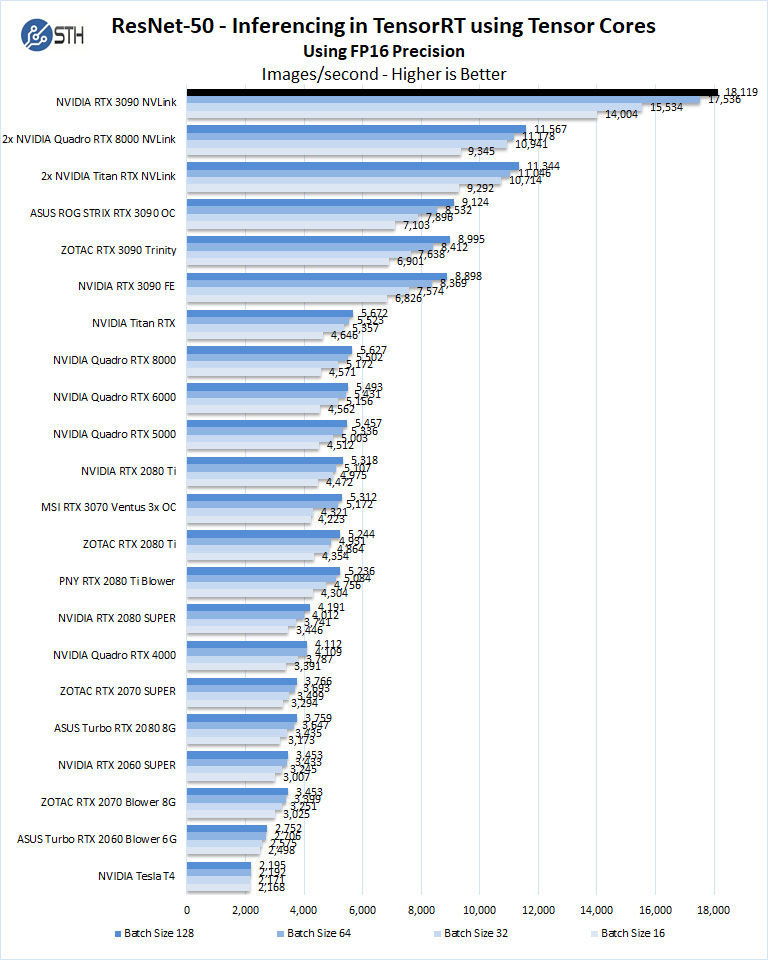
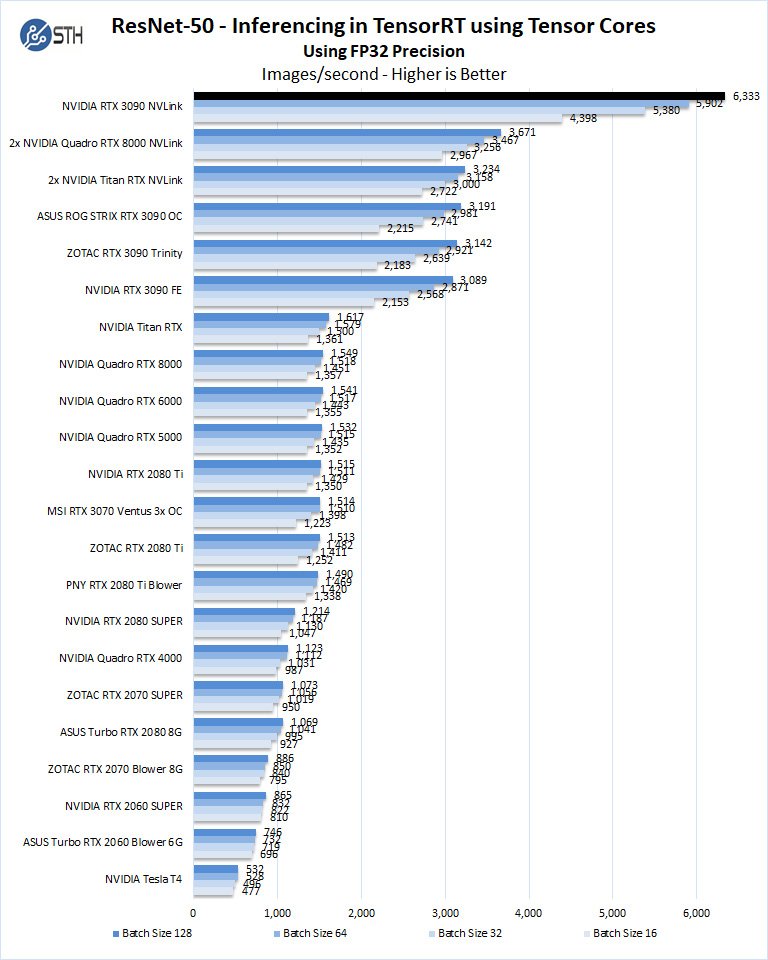
Again, we mentioned this in our NVIDIA Tesla T4 AI Inferencing GPU Benchmarks and Review, but the inference performance of two of these cards exceeds 8-10 NVIDIA T4’s in some cases. Of course, the T4 is a lower power part that is easier to deploy, but if one just wants a single GPU for workstation-style edge inferencing, at similar list prices the RTX 3090 provides much more performance.
ResNet-50 Training, using Tensor Cores
We also wanted to train the venerable ResNet-50 using Tensorflow. During training, the neural network is learning features of images, (e.g., objects, animals, etc.) and determining what features are important. Periodically (every 1000 iterations), the neural network will test itself against the test set to determine training loss, which affects the accuracy of training the network. Accuracy can be increased through repetition (or running a higher number of epochs.)
The command line we will use is.
nvidia-docker run --shm-size=1g --ipc=host --ulimit memlock=-1 --ulimit stack=67108864 -v ~/Downloads/imagenet12tf:/imagenet --rm -w /workspace/nvidia-examples/cnn/ nvcr.io/nvidia/tensorflow:20.11-tf2-py3 python resnet.py --data_dir=/imagenet --batch_size=128 --iter_unit=batch --num_iter=500 --display_every=20 --precision=fp16
Parameters for resnet.py:
–layers: The number of neural network layers to use, i.e. 50.
–batch_size or -b: The number of ImageNet sample images to use for training the network per iteration. Increasing the batch size will typically increase training performance.
–iter_unit or -u: Specify whether to run batches or epochs.
–num_iter or -i: The number of batches or iterations to run, i.e. 500.
–display_every: How frequently training performance will be displayed, i.e. every 20 batches.
–precision: Specify FP32 or FP16 precision, which also enables TensorCore math for Volta, Turing and AmpereGPUs.
While this script TensorFlow cannot specify individual GPUs to use, they can be specified by
setting export CUDA_VISIBLE_DEVICES= separated by commas (i.e. 0,1,2,3) within the Docker container workspace.
We will run batch sizes of 16, 32, 64, 128, and change from FP16 to FP32.
Some GPU’s like RTX 2060, RTX 2070, RTX 3070, RTX 2080, and RTX 2080 Ti will not show some batch runs because of limited memory.
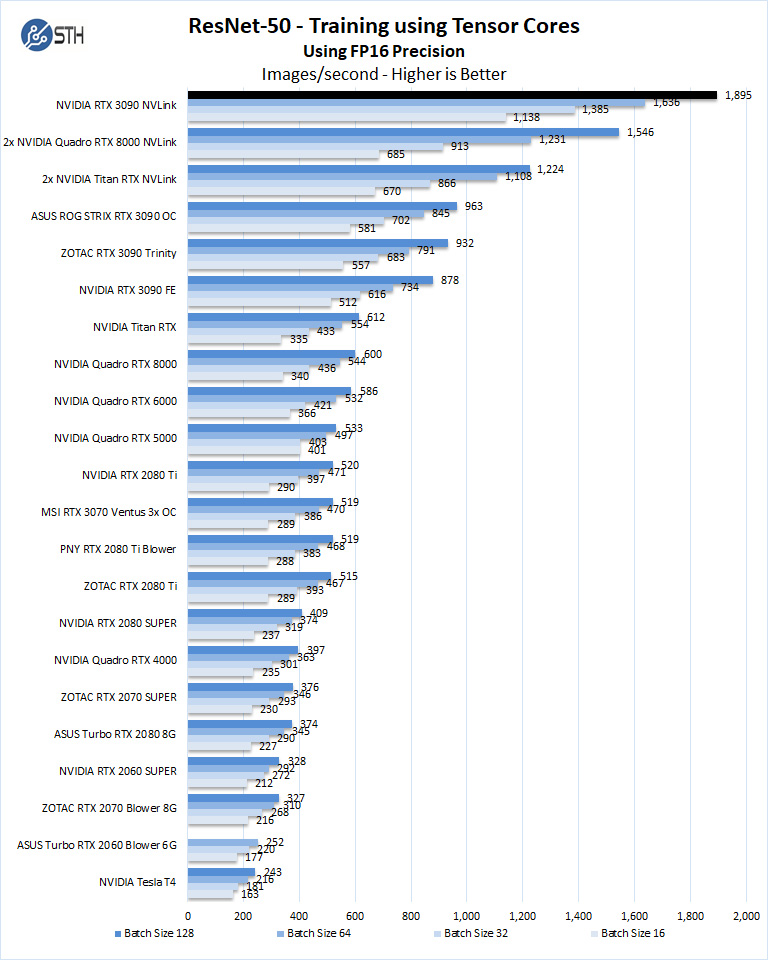
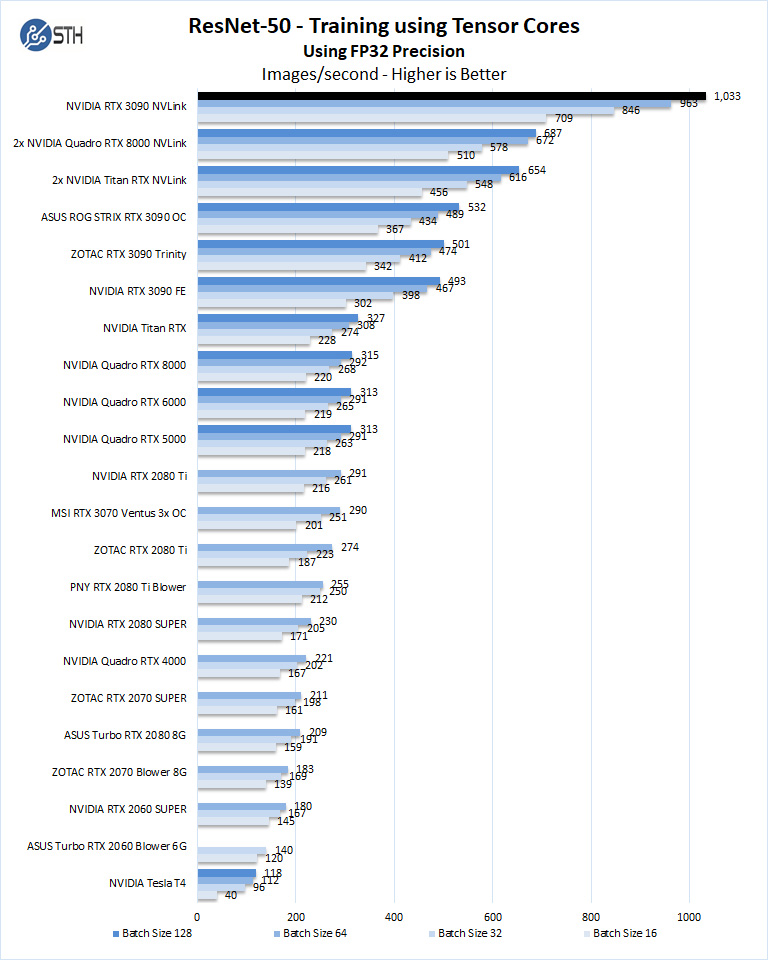
Again, something that is important here is that we have results that exceed three times the best results of the GeForce RTX 2080 Ti.
Training using OpenSeq2Seq (GNMT)
While Resnet-50 is a Convolutional Neural Network (CNN) that is typically used for image classification, Recurrent Neural Networks (RNN) such as Google Neural Machine Translation (GNMT) are used for applications such as real-time language translations.
The command line we use for OpenSeq2Seq (GNMT) is as follows.
nvidia-docker run -it --shm-size=1g --ipc=host --ulimit memlock=-1 --ulimit stack=67108864 -v ~/Downloads/OpenSeq2Seq/wmt16_de_en:/opt/tensorflow/nvidia-examples/OpenSeq2Seq/wmt16_de_en -w /workspace/nvidia-examples/OpenSeq2Seq/ nvcr.io/nvidia/tensorflow:20.11-tf2-py3
We then open the en_de_gnmt-like-4GPUs.py and edit our variables.
vi example_configs/text2text/en-de/en-de-gnmt-like-4GPUs.py
First, edit data_root to point to the below path:
data_root = “/opt/tensorflow/nvidia-examples/OpenSeq2Seq/wmt16_de_en/”
Additionally, edit the num_gpus, max_steps, and batch_size_per_gpu parameters under
base_prams to set the number of GPUs, run a lower number of steps (i.e. 500) for
benchmarking, and also to set the batch size:
base_params = {
...
"num_gpus": 1,
"max_steps": 500,
"batch_size_per_gpu": 128,
...
},
Also, edit lines 44 and below as shown to enable FP16 precision:
#”dtype”: tf.float32, # to enable mixed precision, comment this
line and uncomment two below lines
“dtype”: “mixed”,
“loss_scaling”: “Backoff”,
We then run the benchmarks as follows.
python run.py –config_file example_configs/text2text/en-de/en-de-gnmt-like-4GPUs.py –mode train
The results will be Avg. Objects per second trained which we plot.
We should note that other GPUs we used, like the GeForce RTX 2060, RTX 2070, RTX 2080, and RTX2080 Ti could not complete this benchmark due to the lack of installed memory. To enable this benchmark to finish on these GPUs one might need to lower the batch size to smaller values like 32, 16, 8. We tried this but had no luck. Using a batch size four could be run but it was decided that this was not a very usable size.
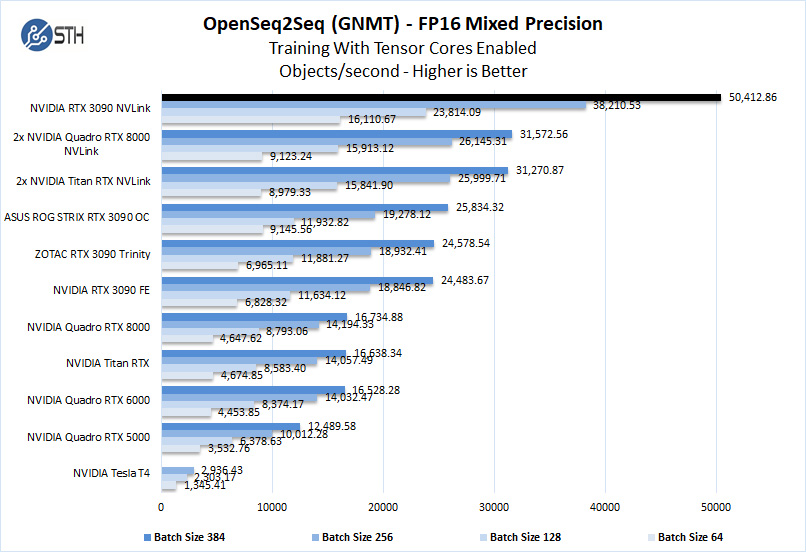
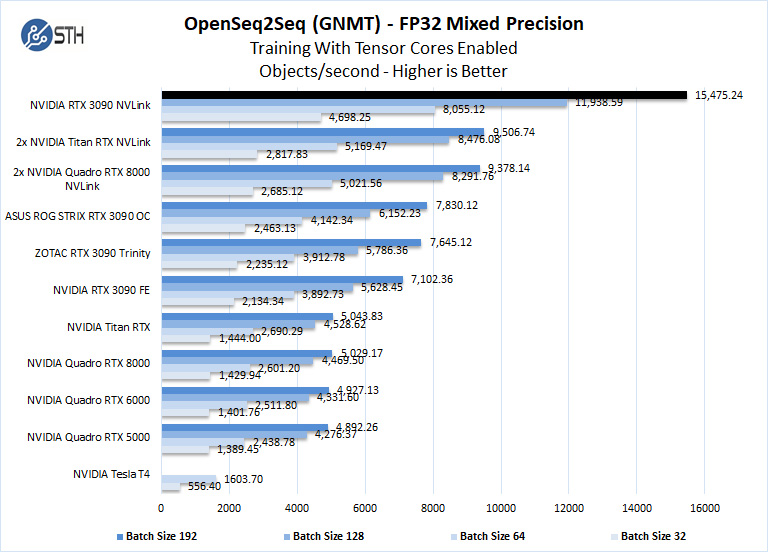
The NVIDIA RTX 3090 has 24GB of installed memory, equal to that of the Titan RTX. The Quadro RTX 8000 includes 48GB of installed memory. Still, the newer Ampere architecture is a clear winner here putting in performance of around three NVIDIA Titan RTX’s here in a use case where memory capacity matters.
Next, we will look at the dual GeForce RTX 3090 power and temperature tests and then give our final words.



{kind=link}
Darn son that’s the bossliest beast I ever did see!!!
DirectX 12 supports multi GPU but has to be enabled by the developers
NVlink was only available on the 2080 Turing cards – so only the high end SKU having it – nothing new. AMD’s solution is what again? Nothing.
in DX11 games – dual 2080Ti were a viable 4K 120fps setup – which I ran until I replaced them with a single 3090. 4K 144Hz all day in DX11.
I would imagine someone will put out a hack that fools the system into enabling 2 cards – even if not expressly enabled by the devs
2 different cards is about as ghetto as it gets and shows the (sub)standards of this site – Patrick’s AMD fanboyism is the hindrance to this site – used to check every day – but now check once a week – and still little new… even the jankiest of yootoob talking heads gets hardware to review.
As an aside, I hope ya’ll get a 3060 or 3080 TI to review.
The possibility of the crypto throttler affecting other compute workloads has me very worried… and STH’s testing is very compute focused.
Good review Will, ignore the fanboy whimpers any regulars knows how false his claims are.
Next up A6000?
Curious how close the 3090 is.
Nice review. I wonder how well the temperature can be controlled with a GPU water cooler.
Thanks for the review. It would be awesome to see how much the NVLink matters. I’m particularly interested for ML training – does the extra bandwidth help significantly, v.s. going through PCIe?
One huge issue is the pricing.
Many see the potential ML / DL Applications of the 3080 and their first idea is to stick them in Servers for professional use. The issue with that is that, in theory, this is a datacenter use of the GPU and thus violates the Nvidia Terms of Use…
AFAIK only Supermicro sells Servers equipped with the RTX 3080… why they are allowed to do that ? IDK… considering it is supermicro, they might just not care.
Here comes the pricing issue though. If you are offering your customers the bigger brands such as HPE and Dell EMC you are stuck with equipping your Servers with the high end datacenter GPUs such the V100S or A100 which cost 6-8 times as much as a RTX 3080 with similar ML perfomance … on paper.
Nvidia seems to be shooting themselfes in the foot with this. In addition to making my job annoying trying to convince customers that putting a RTX 3080 into their towers should be considered a bad idea.
I’ve got exactly the same 2 cards!
What specific riser did you use? I’d like to hear your recommendation before I purchase something random ;).
I have two 3090, same brand and connected with the original NVLink.
We acquired these for a heavy weight VR application done with Unreal Engine 4.26
We tested all the possible combinations but we couldn’t make them work together in VR. Only one GPU is taking the app. We checked with the Epic guys and they don’t have a clue. We contacted Nvidia technical support and the guys of the call center literally don’t have any page to use it against this extreme configuration We want to use one eye per GPU but it is not working. Anyone has an idea or knows something. Any help is more than welcome !!!!!
Dual gpu LOL Can’t believe people keep doing this hahaha
One of the problems I have run into with multiple Cards is that they do not seem to increase the overall GPU memory available. I have configurations where there are 2-4 cards in the computers and when I run applications, they only seem to think that I have 12 GB of GPU memory only. Even when 2 are NVLinked. I see the processes spread out amongst the cards, but for large data files, I see that my GPU footprint increase to around 11.5 – 11.7 GB and things slow down when this happens. Thus, GPU memory seems to be the bottle neck that I have been running into (12 GB on the 3080ti and the 2080ti).
While getting cards has been a little difficult, it isn’t that hard to source a pair of the same cards. I currently have 3 x rtx3090 ftw3 ultra cards and 1 3090 from an Alienware.
I learned long ago while running a pair of gtx1080ti’s, very few dev’s utilized the necessary products to benefit from SLI. One card just sat silently while the other worked. Perhaps they’ve improved. Only time will tell.
I have Asus Strix 3090s (x2) and with NVLink Bridge (4Slot) cant get Nvidia control panel to see that they are connected, no option to enable SLI/NVlink. using latest driver 512.59
was your bench using pcie4 hardware because this could bottleneck your performance.
you should be seeing an improvement in performance close to 1.5+ times performance which would put it above the 4090 what psu did you use?