
We have done a number of smaller builds including DeepLearning01 and DeepLearning02 that we published. While those builds were focused on an introductory, getting your feet wet with frameworks, today we have a different monster, DeepLearning10. This is an 8x NVIDIA GTX 1080 Ti GPU beast and is relatively affordable. We will note that as we are writing the DeepLearning10 piece, DeepLearning11 (a second 8x GPU system) is already up and running half populated with GPUs. As we have seen these systems deployed in Silicon Valley data centers, they are rarely one-offs and are more often clustered.
DeepLearning10: Components
If we had asked NVIDIA would probably have been told to buy P100/ GP100 cards. Unfortunately, we do have budget constraints so we bought 8x NVIDIA GTX 1080 Ti cards. Each NVIDIA GTX 1080 Ti has 11GB of memory (up from 8GB on the GTX 1080) and 3584 CUDA cores (up from 2560 on the GTX 1080.) The difference in price for us to upgrade was sub $1,200, a drop in the bucket in the overall machine cost. We did purchase cards from multiple vendors. That allowed us to do something fun:
Red SLI connector covers are on the side of CPU2 and Black SLI connector covers are on the CPU1 side. We did mess up a power connector seating on one of the cards so this came in handy for troubleshooting. We are primarily using cards from Gigabyte, MSI, Zotac in our two builds.
In terms of the system, we are using a Supermicro SYS-4028GR-TR. Our Supermicro SYS-4028GR-TR review in 2015 found the system to be quite capable of handling many hot cards.

We did have to purchase a “GTX hump” for the server to allow the NVIDIA GTX 1080 Ti power connectors to fit:

You can read more about this process in our Avert Your Eyes from the Server “Humping” Trend in the Data Center piece.
We are using a Mellanox ConnectX-3 Pro VPI adapter that supports both 40GbE (main lab network) as well as 56Gbps Infiniband (deep learning network.) We had the card on hand but using FDR Infiniband with RDMA is very popular with these machines. 1GbE / 10GbE networking simply cannot feed these machines fast enough.

In terms of CPU and RAM we utilized 2x Intel Xeon E5-2690 V3 CPUs and 256GB ECC DDR4 RAM. DeepLearning11 will have E5 V4 CPUs and 128GB RAM to see the power consumption/ performance impact. We will note that dual Intel Xeon E5-2650 V4 are common chips for these systems. They are the lowest-end mainstream processor that supports the 9.6GT/s QPI speed.
One of the major benefits these systems have over using a high-end desktop platform is that the RAM capacity is much higher. There are 24 DIMM slots and you can use LRDIMMs. Again, our choice was relegated to what we had on hand.

We are using two mirrored Intel DC S3710 400GB SSD boot drives for OS since those are our standard lab drives.
In terms of a cost breakdown, here is what this might look like if you were using Intel E5-2650 V4 chips:
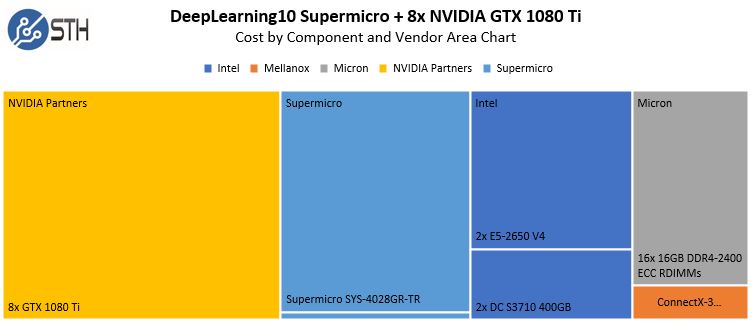
The striking part here is that the total cost of about $15,000 was around three months worth of AWS g2.16xlarge instance time. Being clear, this beast costs us just under $1000/ month if we include power, rack space, WAN bandwidth switch ports, and cables. The payback period for purchasing this kind of monster is sub 4 months compared to AWS. That is why these systems sell like hotcakes.
DeepLearning10: Environmental Considerations
Our system has four PSUs, one could argue whether all four are really necessary. To test this, we let the system run with a giant (for us) model for a few days just to see how much power is being used. Here is what power consumption of the 8x GPU server looks like as measured by the PDU:
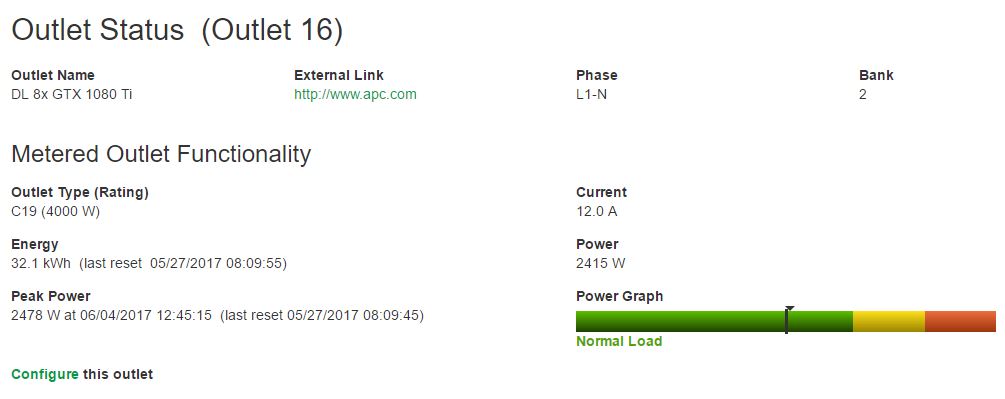
Once we did a bit of performance tuning, this number went up:
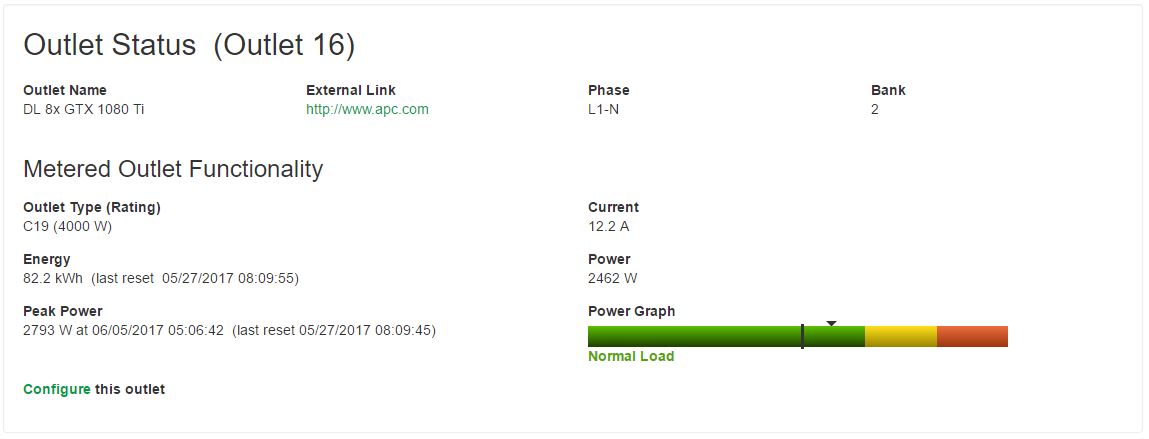
As you can see these systems are so large that they cannot be run even on 30A 120V circuits or A+B power on 2x 15A 120V circuits. That is a nearly 2.8kW peak on 208V power which his more efficient than 120V. Our advice: these need to be in a data center and one that can deliver significant power to a rack.
If you are wondering how loud these servers are, that is the wrong question. At a constant load of around 2.5kW in a 4U-4.5U chassis, the noise produced is extreme. These should only be run in a data center.
Speaking of the data center, using a $1k/ month figure for ongoing costs, here is what the approximately $27,000 cost would look like purchasing the system then operating for one year:
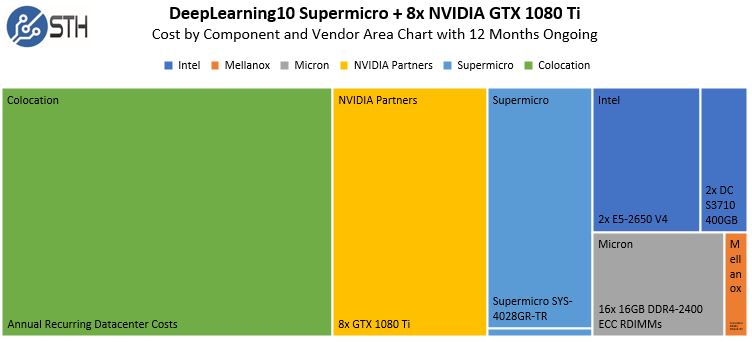
That is about the cost of 5 months of AWS g2.16xlarge instance time if we assume $1k/ month operational costs. We are going to show why we can actually beat this figure by a wide margin in a future piece.
DeepLearning10: Performance Impact
We wanted to show just a bit about how much performance we gained out of the box with this new system. There is a large difference between a $1500 system and a $15,000+ system so we would expect the impact to be similarly large. We took our sample Tensorflow Generative Adversarial Network (GAN) image training test case and ran it on single cards then stepping up to the 8x GPU system. We expressed our results in terms of training cycles per day.
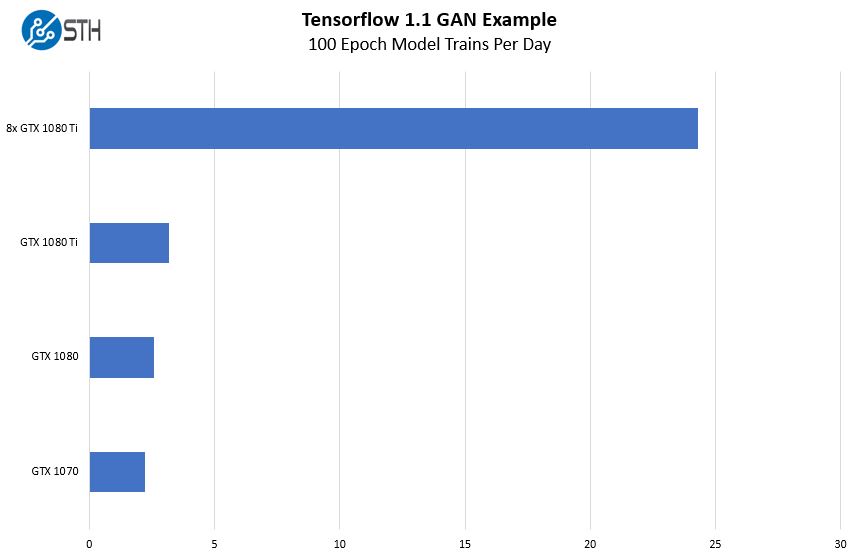
Here is the impact. Our relatively simplistic result shows that just about every hour with the 8x GPU machine we have a new result to pour over and tweak parameters for a subsequent training run. With a single card there is a new model every eight hours. In the context of a work-day, the big machine is a truly awesome tool akin to giving a farmer accustomed to mammal power a diesel tractor.
Those gurus in the field will smirk at this chart and think, there is a lot of tuning that can be done. There is. As another perspective, that learning to get better scaling would take longer than the 24 hours it may take to upgrade to the larger server. If you just need to iterate faster, moving to a larger system is an easy way to get an immediate impact. We also will note that in an upcoming piece, we are going to have a bit more on some great results we saw tuning the system and monitoring.
DeepLearning10: What Could be Better
There are a few items that we wanted to highlight. First, if we are buying a new system, vendors are now touting a PCIe switch architecture with a single root. That helps inter-card bandwidth significantly.
Beyond just the single root there are also 10x GPU systems out there (e.g. the TR2 version of the system we tested.) The benefits are simple. As you fit more GPUs into a system, the cost of the system supporting the CPUs decreases relative to the GPU compute.

In terms of networking, we are a relatively small operation. Ideally, we would be using EDR Infiniband with this or Omni-Path for 100Gbps networking instead of the 56Gbps / 40GbE we are limited to now.
In terms of RAM, we would have loved to purchase more, however, the STH lab is currently experiencing a major DDR4 rush given test systems that are setup.
Final Words For Now
Of course, there is still more to come. As you may have noticed, we are building two of these systems, not just one. Sadly, budget constraints meant we were only able to get 12 of the 16 necessary NVIDIA GTX 1080 Ti’s over the last two weeks. We did try the 3-fan non-blower style fan options and the Founders Edition versions with blower fans are, by far, superior in 7 of the 8 slots.

We did not account for our labor time for installation and setup. It took one person approximately 45 minutes to go from boxes of component parts, rack, cable and get the system online. Teams will finish this task much faster than we did. We also had built a handful of 8x GPU systems previously so we had an idea of how to put these together.
Beyond just getting the hardware, tuning and multi-GPU scaling are not trivial topics. If you look at the larger cluster admins in the deep learning field, these are topics that weigh heavily on decisions. In systems like ours, we have even seen admins install two Mellanox Infiniband cards so that they could avoid the QPI bus between CPUs at all costs.
The hardware we are using is just about the least expensive way to do this. Titan Xp’s would be better options. Realistically, NVIDIA wants you to purchase Tesla cards that have better half and double precision, and that also can utilize NVLink. While we would love to, we also think one of the reasons NVIDIA has done so well in this market is because of the ability to run cards like the GTX 1080 Ti and get great performance from them. For $700 you can buy a NVIDIA GTX 1080 Ti and have formidable performance in your local workstation. Compare this to an Intel Xeon Phi x200 developer system that costs $5000 and NVIDIA has a strong value proposition.



{kind=link}
This is so hot! I got a big stiffie! We’re looking at either the 8 or 10’s for work.
I like the TCO numbers.
We’re going to ask our sales guy about the GTX systems. You’re missing that they’re 88TFLOPS FP32. USA maybe you can all use TESLA but in India this is more realistic for us.
Minor spelling mistake.
“Being clear, this beat costs us just under $1000/ month if we include power, rack space, WAN bandwidth switch ports, and cables.”
beat should be beast.
Thanks! Fixed.
where did you buy the server and server hump?
We bought a couple of these boxes 2-3 months back with literally the same configuration for deep learning and are more than happy with them. One thing that we noticed was that the 1080 (ti and non-ti) run into thermal throttling due to the conservative fan controller curve on the FE cards. To overcome this we wrote a script that regulates the monstrously loud fans of the chassis to the gpu temperature. Email me if you run into the same problem.
There’s also a report of 18 GPUs using a X9DRX+-F Motherboard: https://devtalk.nvidia.com/default/topic/649542/18-gpus-in-a-single-rig-and-it-works/ .
Physically 16 can go in the 4U Fat Twins but it’s not single root. That does show how many can go into 4U (instead of 4.5U).
In need of right angle power plugs or some risers. Maybe add a Dryer Plug.
Hi..
which Nvidia driver you are using ?
Hey thanks a lot for this awesome instructions to build a cost-efficient deep learning machine!
However, I am wondering about the PSU capability to handle all these cards. The 4028GR-TR ships with 1600W redundant PSUs, but the GPUs alone with a power consumption ot maximum 250W will take up to 2000W.
Have you configured the system with stronger PSUs?
Best regards,
Timo
Hi Timo, these machines and the -TR2 with 10x GPUs (our DeepLearning11) have not two redundant PSUs, but four.
You can also run the cards at 300W which adds more power consumption as you may imagine.
Hey, would you reckon end the founders edition 1080ti cards for a dual GPU setup? The other card I’m considering is the evga hybrid cooled card which runs at much lower temps, not sure which is better for a deep learning setup
If you ever want to run a larger setup, e.g. in 1U, 2U or 4U servers, you will want the FE cards.
If you just have a desktop, either is fine but the hybrid will likely be cooler and have higher stock clocks.
Hi Patrick, nice write-up. Just wondering, did you have to buy the 8pin to 2x8pin connectors to power the 1080ti cards??
Thanks
Juan – we received these with our chassis but it is a good item to ensure you are getting while ordering.
Hey i ask my self, what is about the heat development in your system? If i have a look on the first picture i would say the cards will produce, in a permanent usage *like DeepLearning to much heat. And may not be produced for such a usage.
Why Nvidia is selling then Tesla P100 cards for DeepLearning? I would say they may have a better architecture for a permanent usage or?
In the data center, heat is less than an issue. These are heavy systems so we tend to rack them in the bottom half of our racks which have cooling provided via in-floor vents.
Sounds very promising. But i still ask my self then … where is the difference between a Tesla P100 and a 1080 TI? You have experiences running 1080 TI or 1080 in a nearly permanent workload? Are they capable of running permanent? If they are … i dont see the point to use a Tesla P100 right?
Mario, here are the stats on DeepLearning11, the 10x NVIDIA GTX 1080 Ti update to this one as of now (29 Nov 2017):
u@deeplearning11:~$ uptime05:06:49 up 151 days, 16:07, 2 users, load average: 12.56, 12.54, 12.57
I think they are a higher failure rate from what I have heard from some of the companies running 1000’s of them. Perhaps the questions is whether the performance and the reliability are worth the discount.
you need to run EVGA precision as well as the most recent nvidia drivers. The EVGA Precision tool will allow you to set the fan speeds and other settings .
More important than having a cool room and cold air, is getting the HOT AIR OUT. Home Depot has window fan units you can use.
Hello, i just stumbled upon this site.
Is this possible in the GPU oriented blade server too? Like the Super micro-superblade?
Because if possible, it’s worth a lot to just buy the blades GPU-less and then populate the whole system with 1080TIs.
You need the right power cables for this to work on blades but it should work for them. Are you in Silicon Valley by chance? We can try if so.
Which OS have you running on this machine? We have a similar setup and tried Ubuntu. There the machine crashes regularly.
Fabian – we use Ubuntu. There is a PLX switch firmware update that Supermicro support can get you that fixes instability in some configurations/ workloads.
Hi,
I just purchased this exact set up, is there anyway you could please send me the script you use to control fan speeds to GPU temps?
Also, if you don’t mind could you please tell me the part number for the Supermicro “hump” lid?
thank you so much!