Using Accelerators for Big Gains
One of the questions we got asked after the piece a few weeks ago on using accelerators for AI, crypto, and HPC workloads was about the power consumption delta. Since we did that last piece in AWS, we did not have access to that data. So to get that data, we simply used the Inspur server running the same workloads to see what we would get. With that, we saw some fairly huge differences.

A key note on this is the methodology. One of the big challenges with doing accelerator v. no-accelerator is simply getting a useful comparison. We tend to run shorter workloads that take minutes or hours, but real-world systems run 24×7. Further, if workload A using acceleration Aa and no-acceleration An perform at different rates, and over different time periods, then it is harder to compare power consumption between Aa and An. What we did was simply to average power consumption over the main run. We tied the data to the server sensor data plus also were monitoring with the trusty Extech 380803 TrueRMS power meters between the systems and PDUs, as well as the PDU. That gave us PDU data along with system PSU data that we could then tie into time intervals for the workloads. Each of these workloads has periods where they are running at a sustained performance level, and that is what we are using here. We can then get an average power consumption during the sustained portion and the average performance, and get some nice power/ performance ratios.
NAMD STMV AVX2 v AVX-512
Here we are using our STMV workload, and specifically, we are going to use the non-Tiled AVX-512 result versus just using AVX2 to keep this as apples-to-apples as we can get. Of course, as we saw in the previous piece, the AVX-512 Tiled results are much better, but we wanted to show this as more of low-hanging fruit.
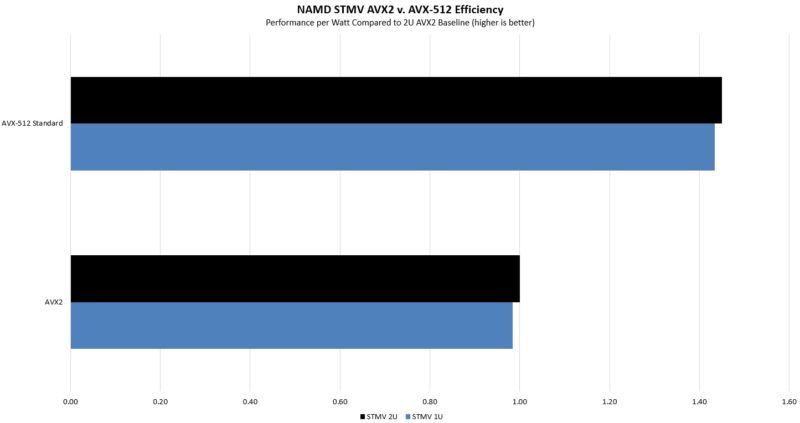
What was most interesting about this one was that the power consumption was close. The AVX2 results actually had lower power consumption than the AVX-512 results. Something to remember here is that especially at these power levels, fans are spinning at high speeds, and thus cooling is a much higher percentage of system power as we saw in our 1U v. 2U results.
Still, when it comes to the amount of work for the power used, the AVX-512 version was clearly better, and by a significant amount. In a world where getting 1-2% on power supplies or fan differences matters. Getting something this large is borderline astounding. This is also why many of the higher-end systems are looking at transitioning to liquid cooling because fans and air cooling are using so much of the total system power here.
Tensorflow with DL Boost
The second workload we looked at was Tensorflow and again we are using the DL Boost acceleration in the Ice Lake systems.
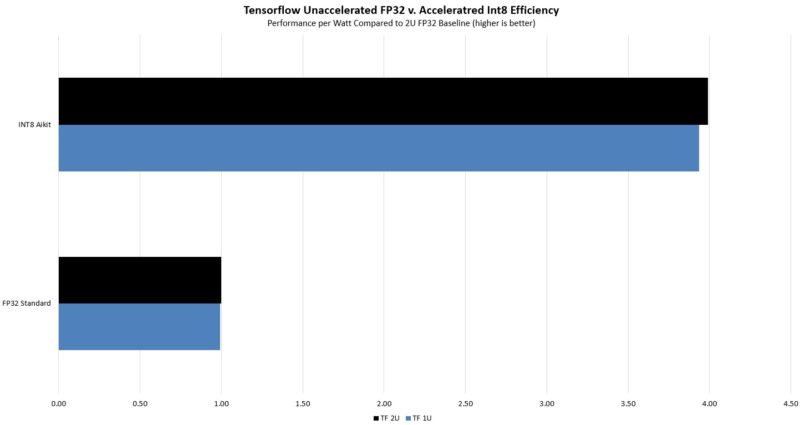
Here again, we saw relatively similar power consumption, but we also saw a huge delta in terms of performance. The net impact was a huge efficiency delta. Most of this is driven by being able to do Int8 instead of FP32. Still, this is an example where the built-in accelerator really drives a huge efficiency gain.
Let us take a second and talk accelerators here. The reason the fan discussion is very important is that a lot of the time folks talk about accelerators in terms of package power consumption. We do it as well. When we look at the NVIDIA T4 that will be part of the NF5180M6’s review configuration, nvidia-smi will tell us the power consumption of that passively cooled GPU. What it is not doing is taking into account the power consumption of the chassis fans that have to cool the GPU. As we have seen, when we are using 15% of incremental system power for cooling, the actual impact of using PCIe accelerators is higher than many discuss. The challenge, of course, is that while major vendors all have the ability to adjust fan speeds to cool passively cooled PCIe accelerators, the algorithms are different and things like how many drives are populated start to matter. Still, when an accelerator claims board power consumption is the total power consumption impact, as a STH reader, you will now know that it is missing a large chunk of system power impact.
WordPress NGINX PHP-FPM
In terms of WordPress, we saw a bit of a different outcome because we actually had lower power in our setup and higher performance.
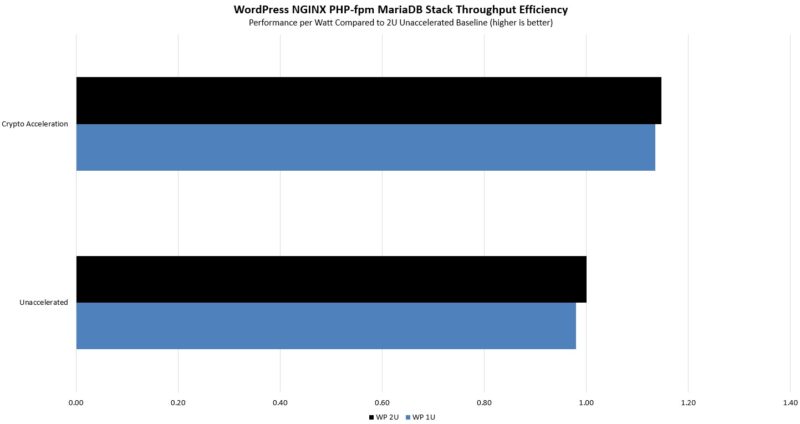
This was a less exciting one than we expected. In terms of power consumption, overall power consumption seemed much lower, but that was an impact of the averaging over the run. As we saw previously, this is not the biggest performance gain because the acceleration is only on a portion of the workload. At the same time, this is good.
Final Words
As we have gone through this exercise, a few insights stood out.
- Getting the power situation sorted, with high-quality power supplies, even sticking to AC power and normal 200-240V power can yield 3-6% lower power consumption. This is an important one to get right.
- As systems get to higher power levels, we will see 15%+ of server power go to cooling. Using 2U chassis instead of 1U chassis means we can get some of that power back. Ultimately, this will push dense systems to liquid cooling especially as that hits 20% levels on higher-end systems.
- The impact of using PCIe accelerators is more than just package power. Incremental cooling costs become a significant portion of the power budget, especially in higher-end systems. In lower-power systems where cooling is a lower overall percentage of power consumption the impact of adding a dedicated accelerator is less.
- Ultimately, having accelerators in CPUs is about more than just performance gains. The power consumption benefits of using the accelerators can be enormous. We used the Intel Ice Lake generation CPUs here because they are basically the first generally available CPUs with this level of acceleration. Other vendors will add their own accelerators over time. We also know that the next-generation Sapphire Rapids Xeons will have more built-in acceleration for AI and other workloads because the performance and efficiency gains are so high.
What we presented here is likely going to be different than what you will see with other server vendors, CPU SKUs, configurations, and so forth. Still, the basic principles should apply. According to Digital Realty, one of the largest data center operators in the world, about 3% of global electricity output goes to power data centers. Using technology that exists today to get 10%+ better power efficiency not only saves money but also has a direct impact on the environmental burden of the world’s compute infrastructure.
Everyone has limitations when it comes to facilities, budgets, and so forth, but this is an area where we are going to urge our readers to take notice of and think about the impacts of seemingly small choices in power efficiency.



{kind=link}
I had no idea fans used that much power. I’d say this is the best power article I’ve seen in a long time.
Wow that’s amazing. That’s the whole “if it completes faster then it’s more efficient” argument, but it’s cool. Do those accelerators work for SpecINT and SpecFP?
I’ll be sending this out.
Nice analysis
It’s surprising that the market hasn’t moved to a combined UPS+PSU per rack format and basically connect individual servers with just a 12V connector. Efficiency wise that would be a far bigger delta than the bump in 80Plus rating on a single PSU, as well as creating more space in a chassis and reducing cooling needs in a single unit.
U need pretty damn big amount of copper. 4 AWG for average server, and of your rack has 10+ nodes…
This is physics, 99% sure it is already have been calculated.
On the amount of copper I doubt this is a big impact on a full rack in terms of cost compared to 10+ PSUs (if anything it’ll be cheaper and reduce maintenance as well). As you’re in low voltage you can just use bus bars with the PSU+UPS in the middle. To my knowledge AWS Outposts already have this design.
We saw about the same as you. We did the change-out to 80+Ti psus and 2U and we got around a 3% lower monthly power for the new racks.
I know that’s not your exact number but it’s in your range so I’d say what you found is bingo.
Going to 12 VDC would definitely introduce a lot of extra cost (significantly more metal), lost space due to all the thicker cables/bus bars, higher current circuit breakers, etc. and to top it all off you still get a drop in efficiency that comes any time you lower the voltage regardless of AC or DC. Then you still need a power supply anyway to convert the 12 V into the other voltages used inside each machine, and what’s the efficiency of that? This is why power to our homes is delivered at 240 V (even in the US) and power distribution begins at 11 kV and goes up from there. The higher the voltage the more efficient, and conversely the lower the voltage the more loss, for both AC and DC.
But DC is more efficient at the same voltage as AC and this is why there is a move towards powering equipment off 400 VDC. You can find a lot of stuff online about data centers running off 400 VDC, and new IEC connectors have been designed that can cope with the electrical arc you get when disconnecting DC power under load. For example normal switch-mode power supplies found in computers and servers will happily run off at least 110 to 250 VDC without modification, but if you disconnect the power cable under load, the arc that forms will start melting the metal contacts in the power socket and cable. I believe the usual IEC power plugs can only handle around 10 disconnects at these DC voltages before the contacts are damaged to the point they can no longer work. Hence the need to design DC-compatible replacements that can last much longer.
The advantage of using mains voltage DC also means the cable size remains the same, so you don’t need to allocate more space to busbars or larger sized cables. You do need to use DC-rated switchgear, which does add some expense. But your UPS suddenly just becomes a large number of batteries, no inverter needed, so I suspect there is a point at which a 400 V DC data center becomes more economical than an AC one.