
At Hot Chips 34 (HC34) there was a tutorial on CXL. This was an in-depth tutorial into things like the mechanisms of cache actions. One tidbit that we have alluded to previously, but did not have a lot on, is the latency added by using CXL. Since we get that question often, it seemed worthwhile to just make a resource dedicated to that question.
How Much Latency Does CXL Introduce?
PCIe has been around for many years, and CXL sits alongside PCIe Gen5 infrastructure (for CXL 1.1 and 2.0.) Putting memory onto the same physical lanes as PCIe Gen5, then adding a CXL controller on the other end, means that there will be additional latency versus traditional DDR interfaces. The main goal, and what we have used as a rough guide, is that accessing memory over CXL should be roughly similar to the latency of moving socket-to-socket in a modern server. At Hot Chips 34, we got some validation of that point.
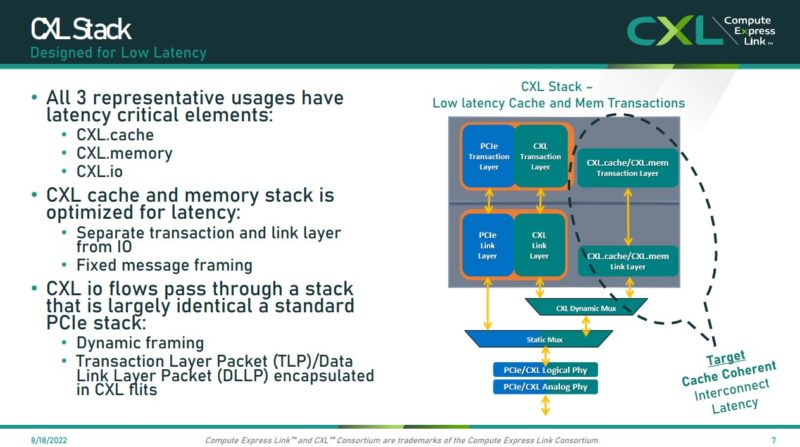
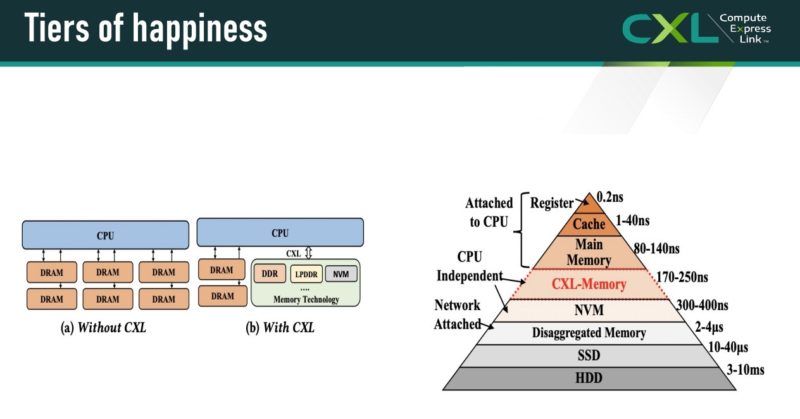
At Hot Chips 34, we got a new pyramid, but it is similar to what we have seen previously. The pyramid goes from registers and caches, out to memory, then to CXL, then to slower memory. The CXL Consortium is using 80-140ns of latency for main memory and 170-250ns for CXL memory.
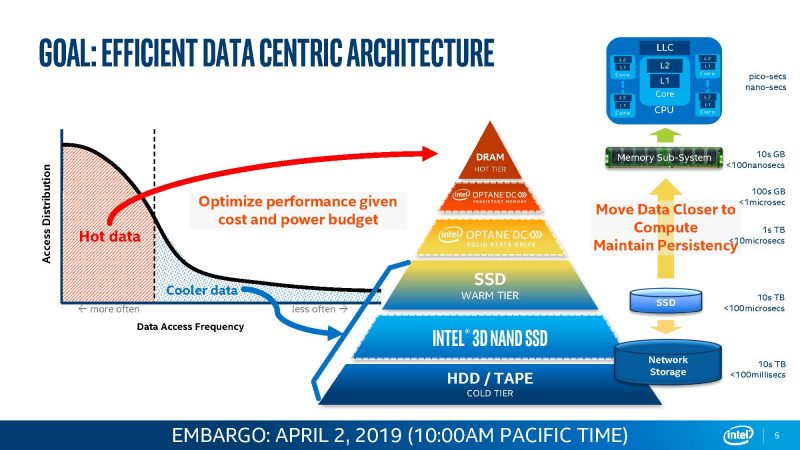
If CXL seems to be occupying a familiar spot, this is below DRAM and above NVMe SSDs, or exactly where Optane sat in Intel’s stack before the Intel Optane $559M Impairment with Q2 2022 Wind-Down.
The other Optane partner Micron replaced Optane with CXL as it backed out of the JV.
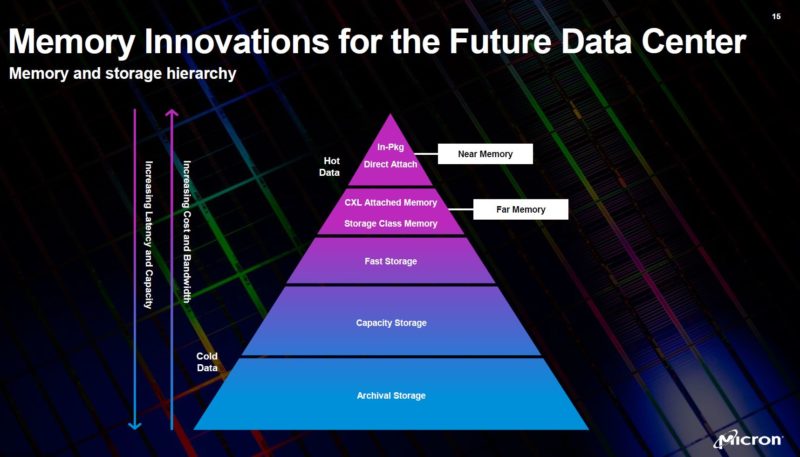
This makes a lot of sense. As we covered in Glorious Complexity of Intel Optane DIMMs and Micron Exiting 3D XPoint. Since Optane turned into a tier that was cached with standard DDR4 memory, it ended up occupying a similar spot to where CXL is envisioned, except CXL benefits the entire ecosystem, not just Intel Xeon CPUs.
Beyond CXL 2.0 is CXL 3.0. That is where we get things like a PCIe Gen6 PHY for twice the bandwidth and also fabric connectivity for multi-level switching using port-based instead of host-based switches. We recently saw a XConn XC50256 CXL 2.0 Switch Chip and that is massive, but the CXL 3.0 versions are still some time away. PCIe Gen6 PHYs add more bandwidth but CXL has some secret sauce that gets 2-5ns better latency due to how it crafts its Flits. Flits here are being used similar to what folks would be more familiar with in the networking space (Flit is a FLow control unIT.)

One of the other exciting aspects about CXL is the ability to use CXL fabric for scaling out the system. Here, as we get to a more disaggregated system architecture (that we covered in our CXL 3.0 piece), memory latencies can grow to 600ns.
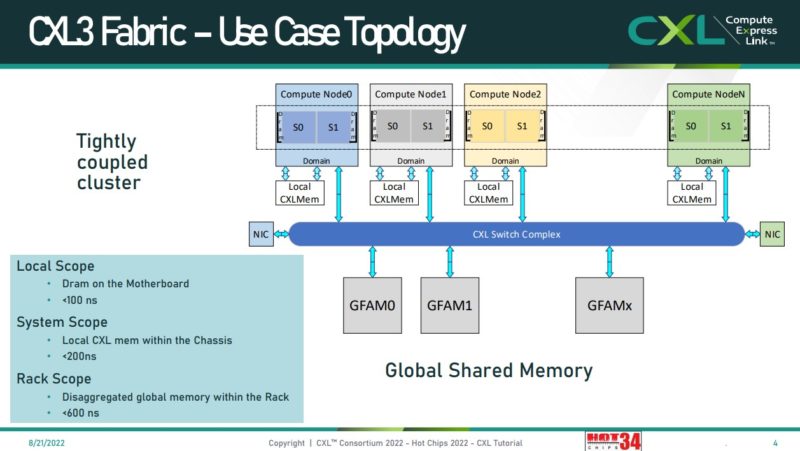
That brings a really interesting challenge. In a system, we can have local memory on a host CPU or other device. We can then have CXL memory/ memory on other NUMA nodes that incur additional latency. Finally, we can have more memory that sits outside of a system and has even higher latency. The net result is that folks are now starting to talk about tiering memory, and mechanisms to utilize memory with different bandwidth and latency characteristics. Again, below note the “CXL <= NUMA socket-to-socket latency” line that is similar to what we have discussed before and is in another presentation above.
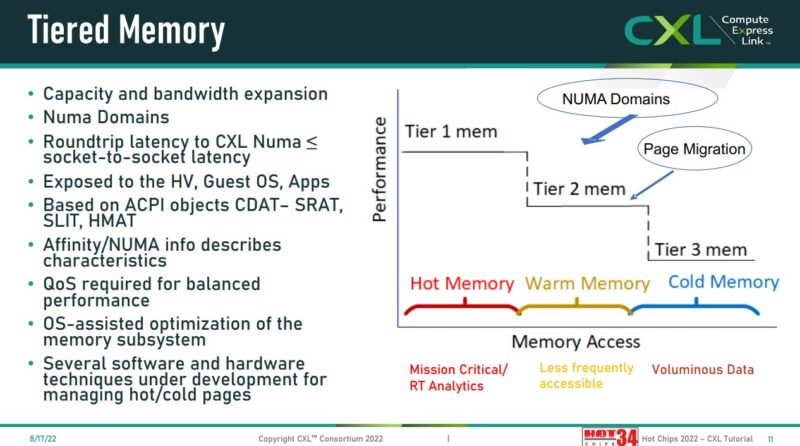
Meta discussed how it is looking at using tiered memory in its infrastructure to save on memory costs. The idea is that memory pages can either be hot or cold and by monitoring the usage and then adjusting placement accordingly, it can best take advantage of different tiers of memory.
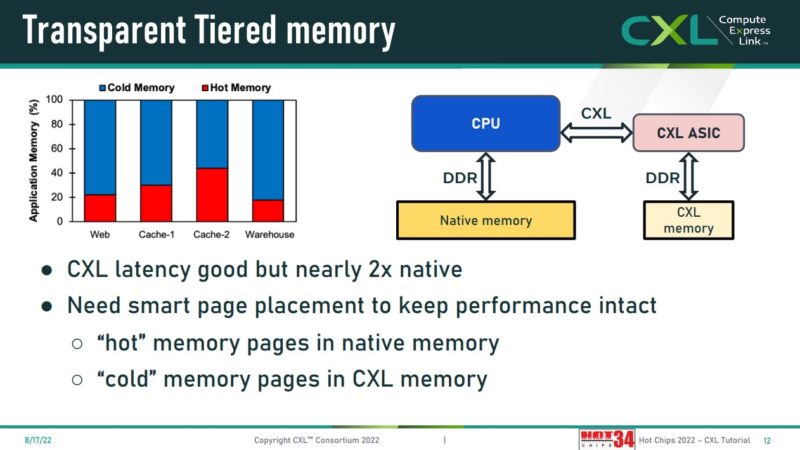
There is still a lot of work that will go into making that a reality, but it is work that will need to happen. CXL memory can be not just DDR4/DDR5. One can use lower-cost DDR3, higher-cost HBM, or other types of memory so even the types of CXL attached memory may have different performance profiles.
Final Words
As you may have noticed, we pulled these slides from a number of different CXL sessions in the workshops today. While there are a number of challenges in the future systems, like CXL 3.0 scaling to 4000+ ports and managing cache coherency across large systems, the operational savings can be immense due to the sheer cost and often poor utilization of DRAM in today’s systems.
Hopefully this article will at least answer the question in terms of how to frame CXL memory latencies as being similar to NUMA (e.g. socket-to-socket) latencies for local systems and at the rack scale being several times higher (<= 600ns.) We will likely see the CXL Memory devices start to appear in the next generation of servers, and then the major ramp into 2025-2027 with new features. If you need a primer on CXL basics, then we have the Compute Express Link or CXL What it is and Examples piece and the taco primer video:



{kind=link}
Thanks for the excellent write-up on CXL. Some of the figures (latency pyramid and system w/ and w/o CXL) used in this blog are generated and reused from our arXiv paper titled “TPP: Transparent Page Placement for CXL-Enabled Tiered Memory” (https://arxiv.org/abs/2206.02878). The work is done in collaboration with Meta. I will highly appreciate it if you kindly add a citation to our paper.
Possible that with a new 5000+ pad socket we move to 10,12 or 16 channel DDR5/6. Cheap + half the latency can get you the ‘Tears of Happiness’