
The Cerebras Wafer Scale Engine 2 or WSE-2 is one of two architectures I refer to as spaceships. The other is the Intel Ponte Vecchio is a Spaceship of a GPU. While Intel is focused on combining chips from many wafers into smaller packages, Cerebras is perhaps more dramatic, it creates one enormous chip out of an entire wafer. For our readers, we are aware that combining multiple WSE chips would be even cooler, but Cerebras is going to have its first version of that, but using an external interconnect in its talk. This is being done live and Cerebras has close to 1.5 slides per minute so please excuse typos.
Cerebras Wafer Scale Engine 2 WSE-2 at Hot Chips 33
Here are the specs on the WSE-2. Just before this we had the Graphcore Colossus Mk2 IPU talk at Hot Chips 33. In some ways it seems like Graphcore is trying to do something similar, just trying to compete more in form factor with GPUs rather than Cerebras that is trying to do this starting at a massive scale.

The Cerebras CS-2 houses the WSE-2. We were able to take a look at the Cerebras CS-1 Wafer-Scale AI System at SC19 and this appears somewhat similar. I also saw a few and the internals when I visited and did Our Interview with Andrew Feldman CEO of Cerebras Systems.

Part of Cerebras'(s) approach is the observation that models are growing bigger over time, and memory is a major constraint.

As a result, Cerebras is looking at getting more memory and scaling to clusters of CS-2 systems.

Cerebras has weight streaming to enable this scale-out both on-chip/ wafer, but also to more nodes.
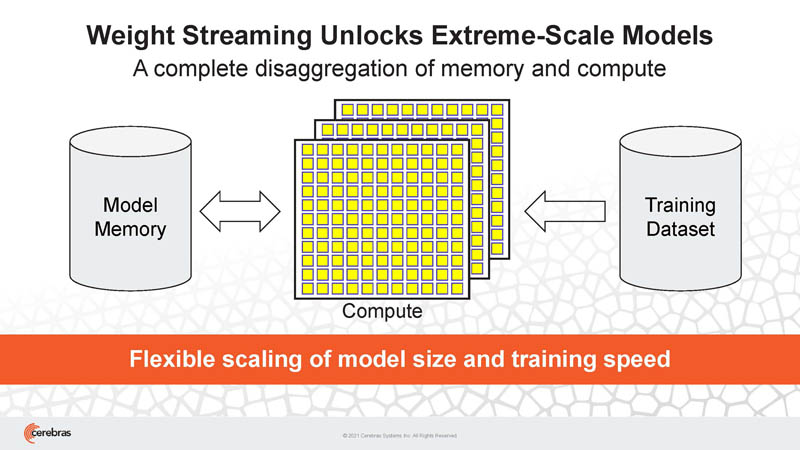
Cerebras has a new MemoryX technology that helps address memory capacity beyond the WSE-2 in the CS-2.

SwarmX Interconnect is the high-speed fabric to scale out to multiple systems. Just as a quick note here, it almost looks like the optics on the SwarmX are not pluggable and have 12 ports. The picture almost looks like one directly plugs in MTP optics to the switch’s faceplate.

Apple pie (my favorite.)

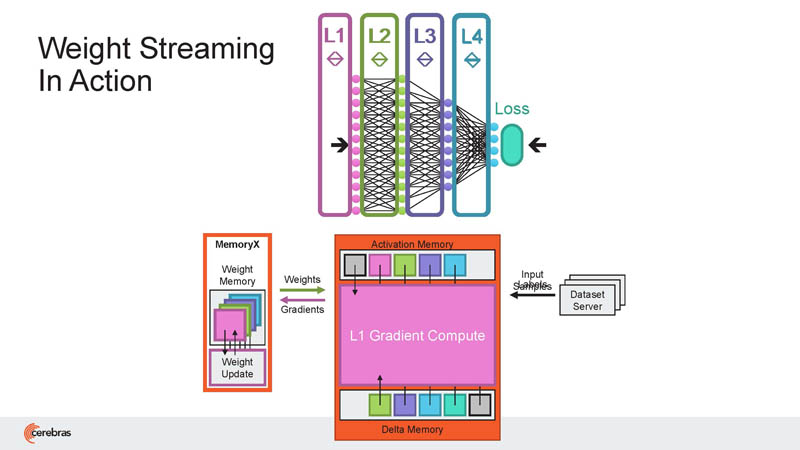
This is the weight streaming model where they can be stored off wafer, and then they are streamed to the CS-2/ WSE-2’s.
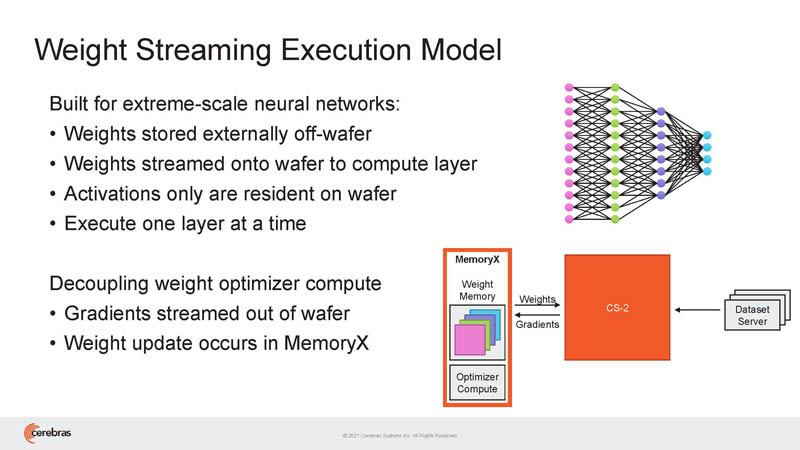
This was a build slide during the talk.
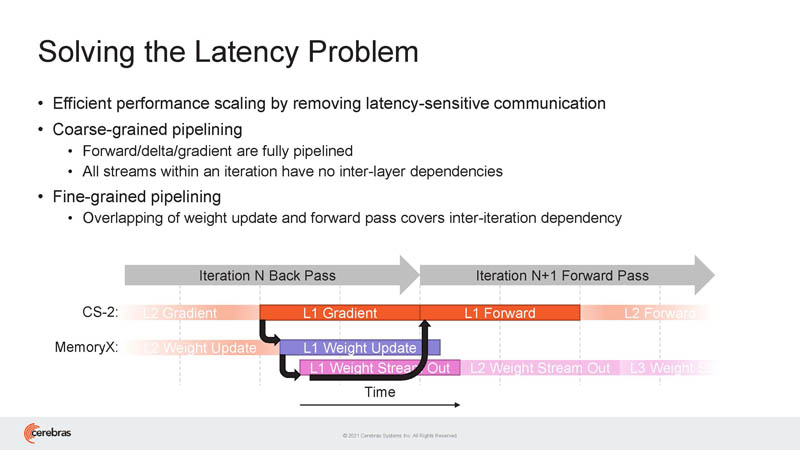
Streaming so much and having so many compute resources, latency can be a challenge, especially during updates. Cerebras has an answer here.
MemoryX we showed earlier and is designed to address storage beyond what fits on the WSE-2 memory. It seems to be a 4TB to 2.4PB capacity solution. 4TB is very possible that it could be DRAM, but the 2.4PB likely has significant NAND in it as well. Yes, I 100% want to see what is in this box. MemoryX can be cabled in adjacent racks and has over 1Tb of bandwidth through the SwarmX.

As a result, layers can be huge because of the simple size of the chips and the ability to scale out.
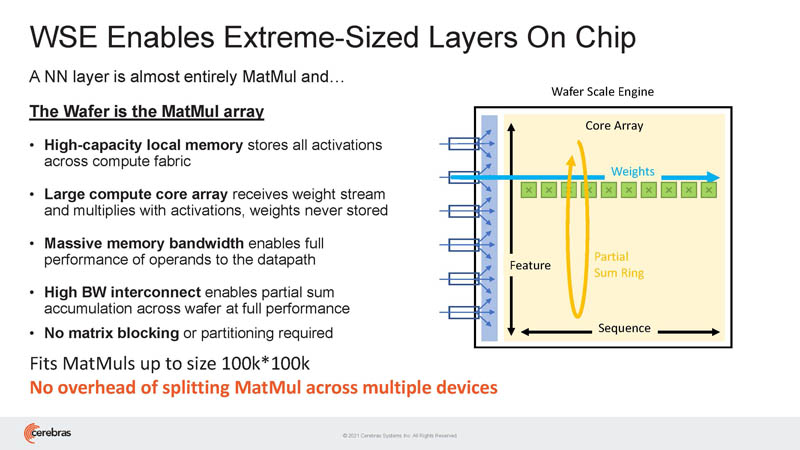
Cerebras is showing that it can drive high utilization even on large layers.
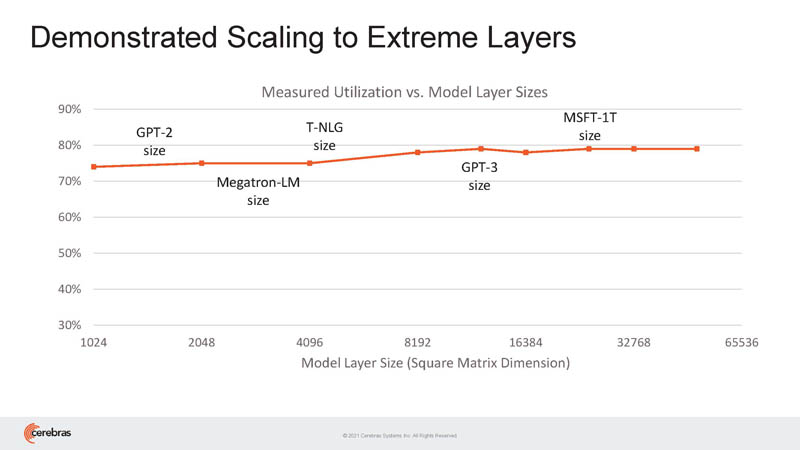
This is how SwarmX works, independent of MemoryX but also with it.
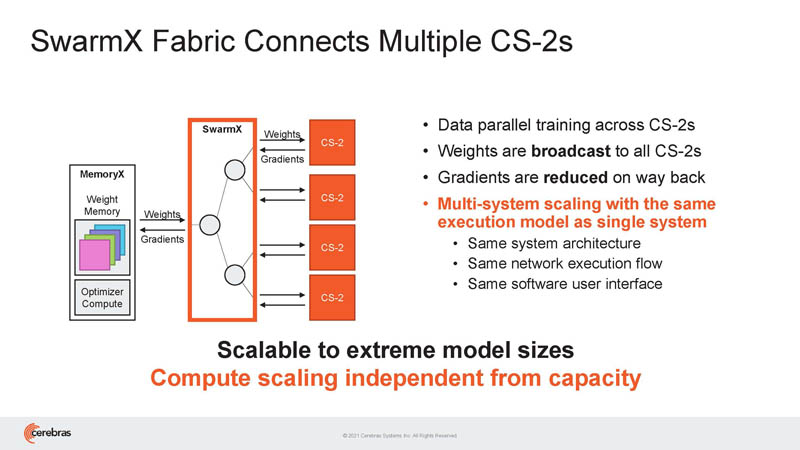
Cerebras says it can scale to high-end problems. Indeed, it shows its best scaling on large problems according to this chart.
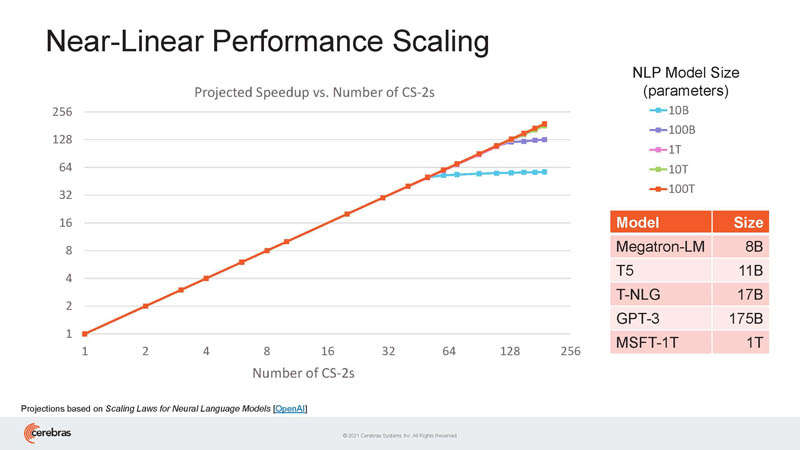
Cerebras is also focusing on sparsity.

Research on sparsity shows it is a 10x opportunity to get more performance with less silicon and at a similar accuracy. That is why NVIDIA, Graphcore, and others are leaning into sparsity.
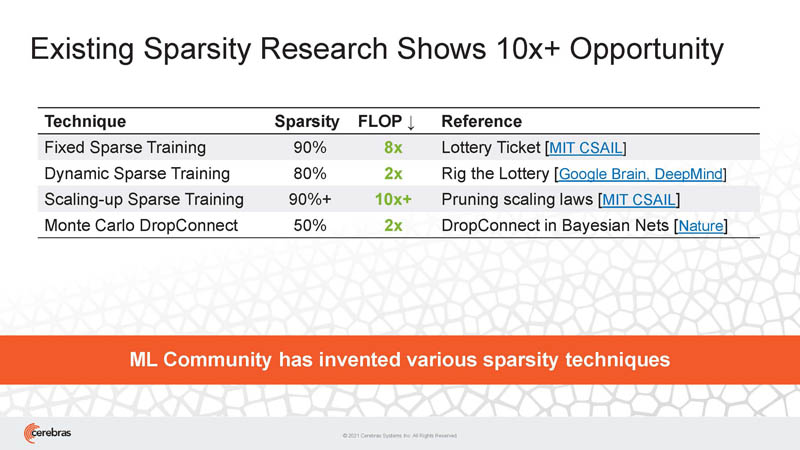
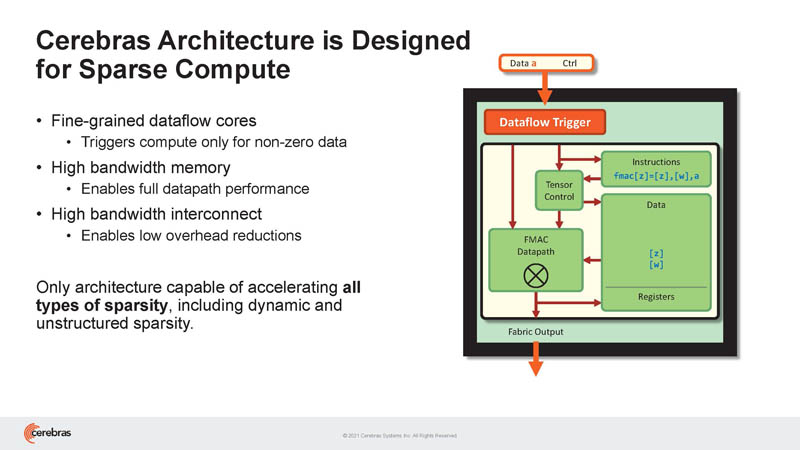
As a result, Cerebras is designed specifically for sparse compute.
Here is the full performance on all BLAS levels slide (running out of time.)

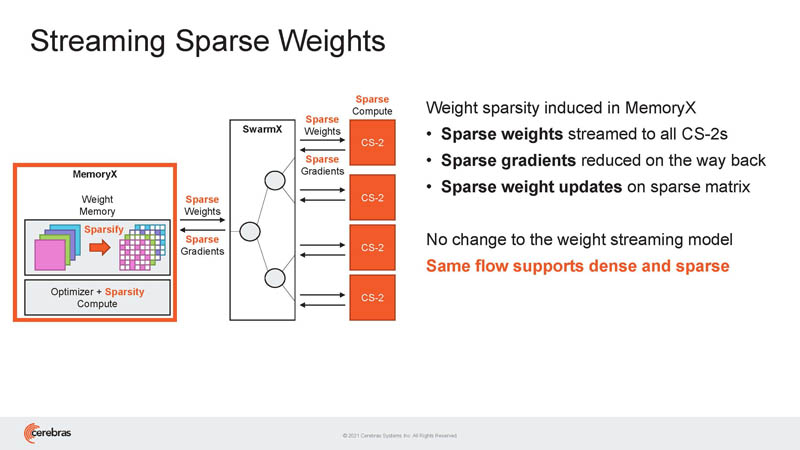
This is how Cerebras seems sparse weights plus MemoryX and SwarmX can be used to handle bigger models.
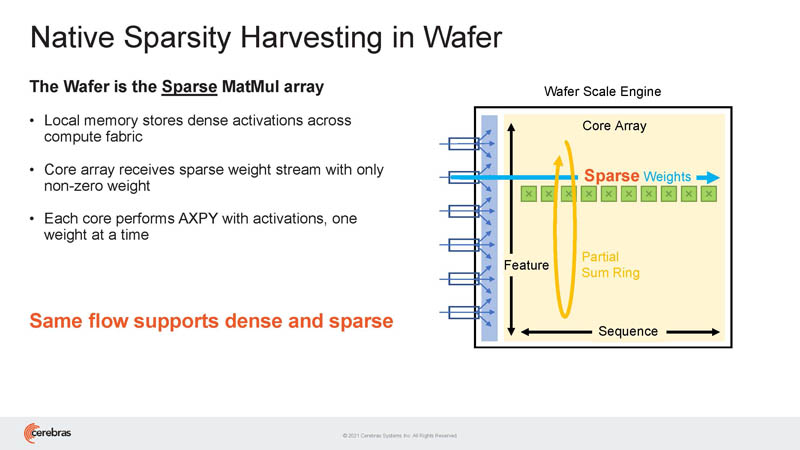
Cerebras can harvest sparsity in wafer.
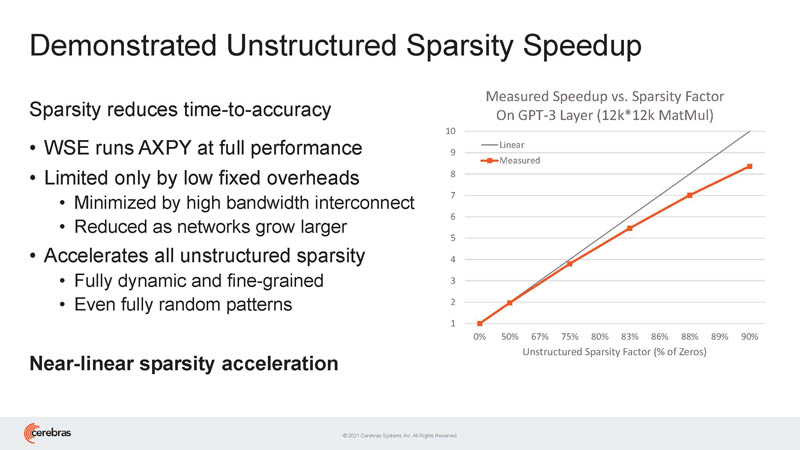
It can also get speedups with sparsity.
The software Cerebras is architecting is designed to scale out beyond the 40GB of onboard SRAM.

This gives some sense of scale of the Cerebras solution, beyond just the wafer. Remember, each WSE is roughly equivalent to a small cluster of GPU-size accelerators. So the 192 CS-2’s is like having a cluster of rack-size clusters in terms of scale.

We are going to give this an appropriate caption:

There is a lot of wow involved in seeing what Cerebras is doing.
Final Words
Overall, Cerebras is doing very cool stuff. Whereas CS-1 and WSE-1 was amazing just that they could get almost an entire wafer to be a single chip, it is now thinking bigger. WSE-2 brings major performance improvements. At the same time though, Cerebras is building memory and interconnect solutions to build bigger clusters. It is very cool to see the company innovating beyond just the big chip.



 and its memory (MemoryX) and interconnect (SwarmX) cluster solutions){kind=link}