
Cerebras makes a wafer-sized computing chip, and the infrastructure around it is used to build something much bigger than NVIDIA’s GPUs. At Hot Chips 2024, we will learn more about the company’s move into the AI inference space. I got a sneak preview of the performance, and it feels almost silly compared to H100 inference. Instead of having to scale to multiple GPUs or even just go off-chip to HBM memory, Cerebras just puts the entire model into a giant chip’s SRAM.
Please excuse typos. This is being written live at Hot Chips.
Cerebras Enters AI Inference Blows Away Tiny NVIDIA H100 GPUs
As a recap, Cerebras has a giant chip that has 44GB of SRAM and tons of cores. This is the biggest square chip you can make from a round wafer.

Here is the scale again versus a typical GPU. While GPUs break down the large wafer into small chips and then try to stitch them together, Cerebras just leaves them assembled as a wafer chip.

Here is what the box looks like.

Outside the box there are many servers. Cerebras started with a cluster in Santa Clara that we covered.

Here is the second cluster up in Stockton, CA of a similar size.

The third system was five times as large in Dallas, Texas.

The new cluster is in MN and is eight times larger than the first.

The chip was designed to train large models.
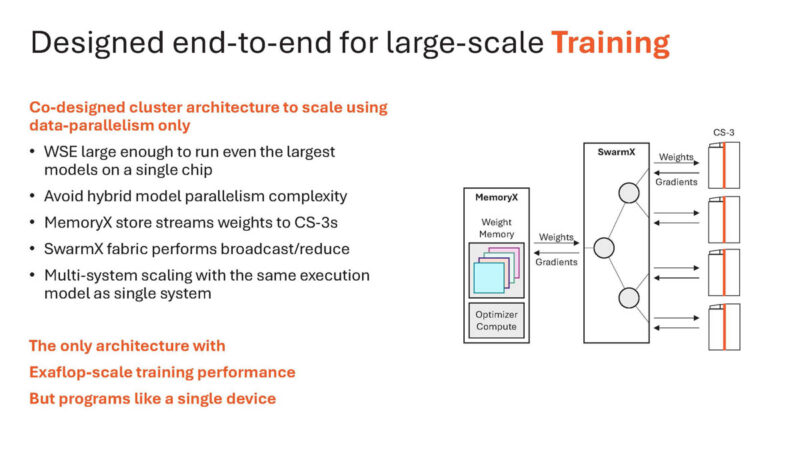
And it does os every day.

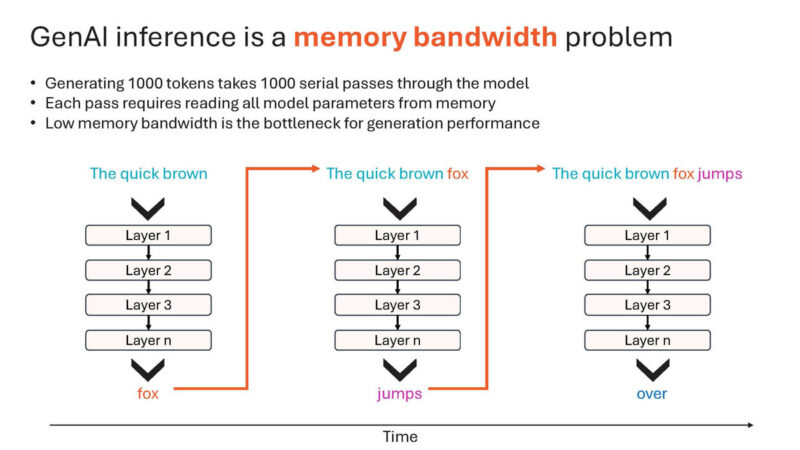
Using the SRAM instead of HBM, Cerebras can scale beyond what HBM allows.
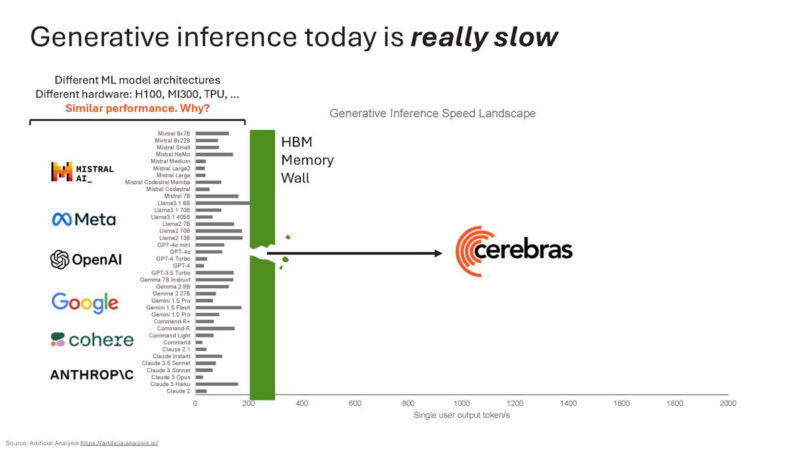
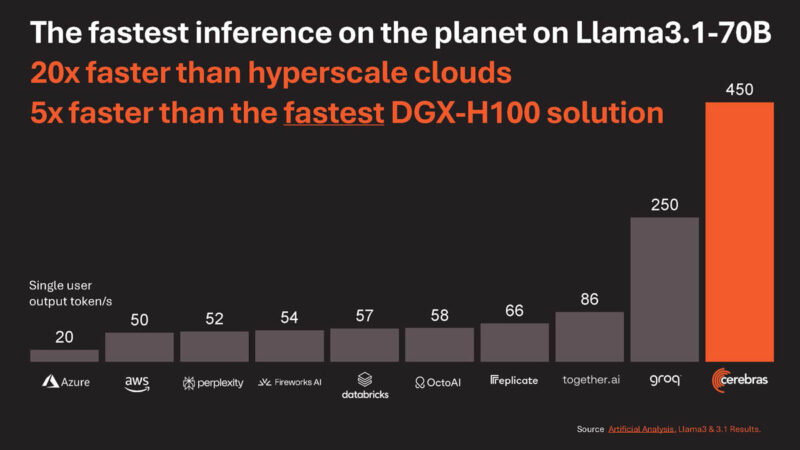
Cerebras says it is 20x faster on Llama3.1-8B versus cloud offerings using NVIDIA H100’s at places like Microsoft Azure.
Google generative AI search is slow.
So, having faster inference is important for a good user experience.

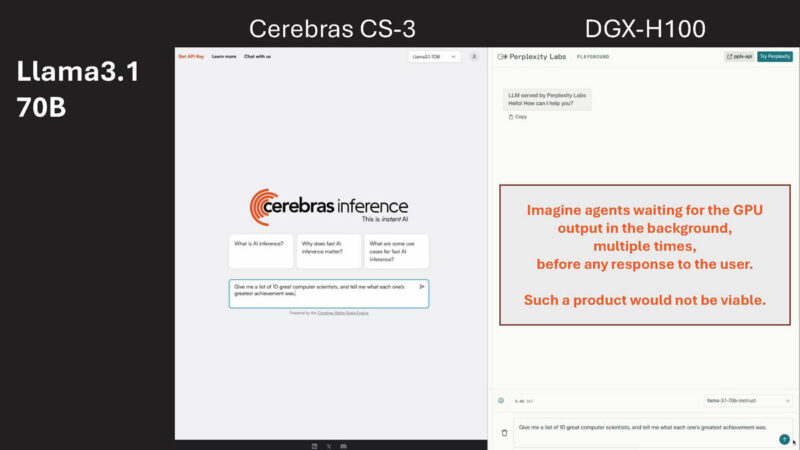
Here is a demo where using Llama3.1-70B Cerebras just dominates the DGX-H100 solution.
Here is the benchmark.
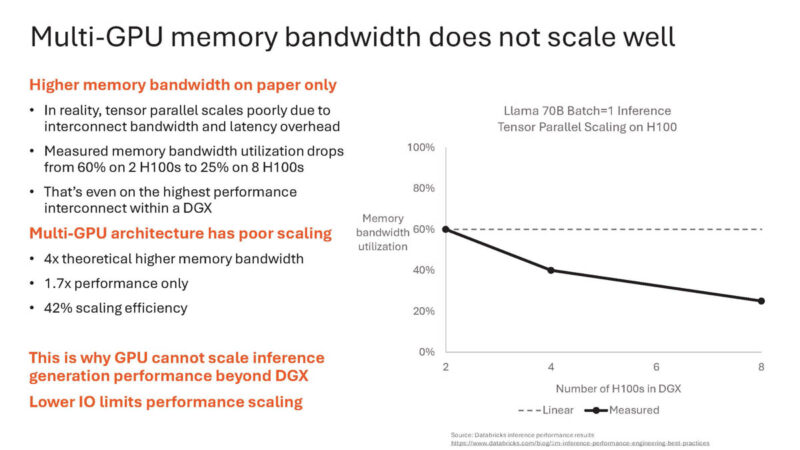
There is a difference between generating the first and subsequent tokens, which is one of the reasons that going to HBM is too slow.
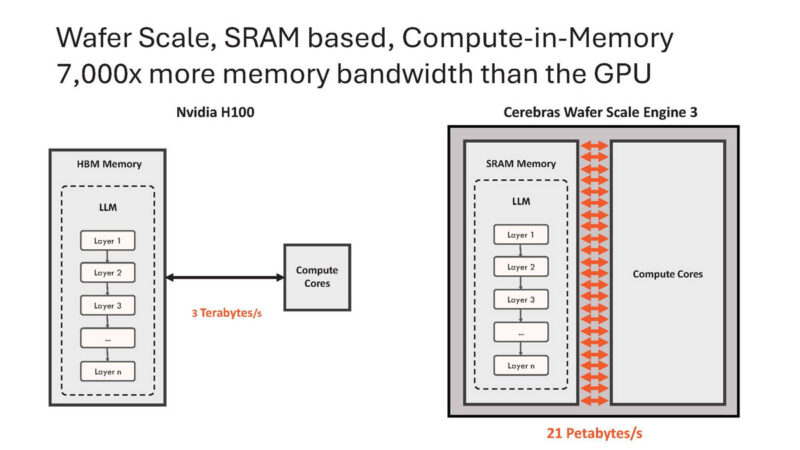
Wafer scale gives massive SRAM (44GB) and so Cerebras does not need to go to slow HBM memory.

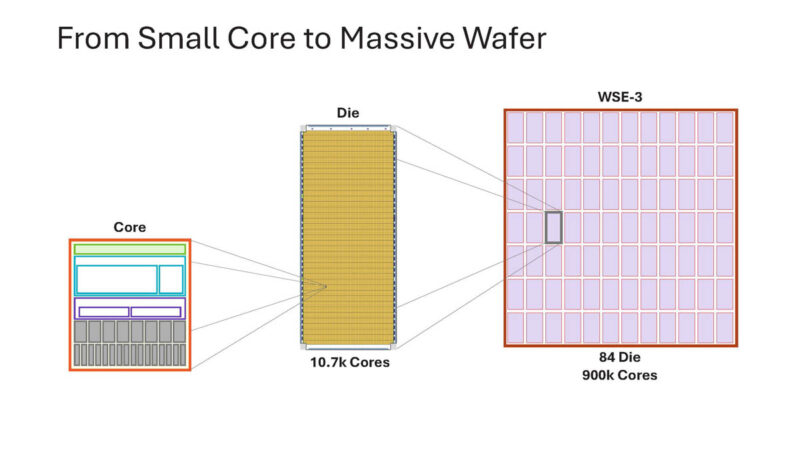
Here is a look at the WSE-3 core with SRAM.
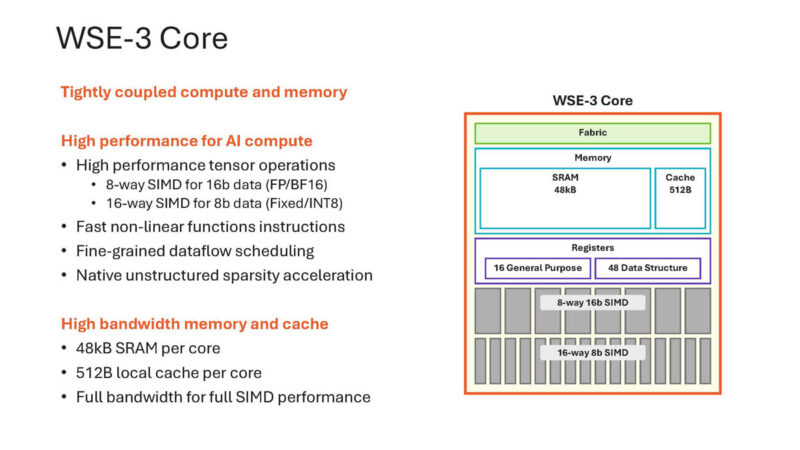
That small core is replicated across dies and the entire wafer.
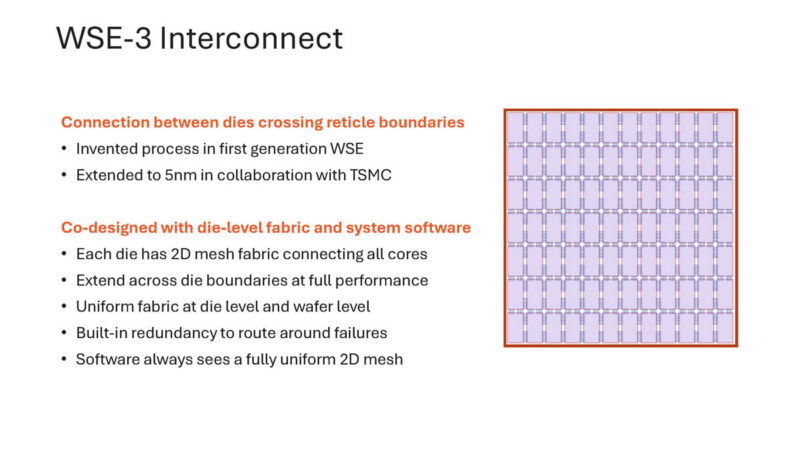
From an interconnect perspective, this is all on-chip, there is no need to go off the chip to another package.
Instead of having to go over the HBM memory interface, with Cerebras everything is on chip.
Aggregating memory bandwidth across H100’s is possible.

But even within a DGX H100 8x NVIDIA H100 GPU solution, it requires a lot of serial interfaces that sock power.

By not going off-die, Cerebras can get more memory bandwidth at lower power.
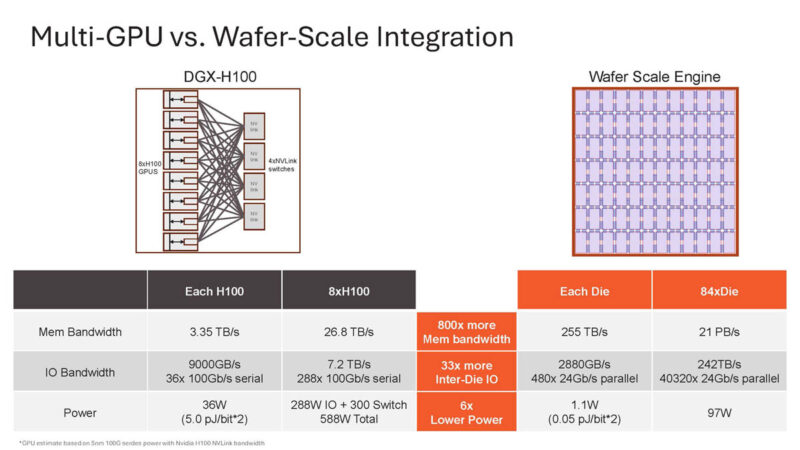
By not going off-die, Cerebras does not need to go through high-speed serial links, PCBs, switch chips, and so forth. Instead, it just moves data through the silicon.
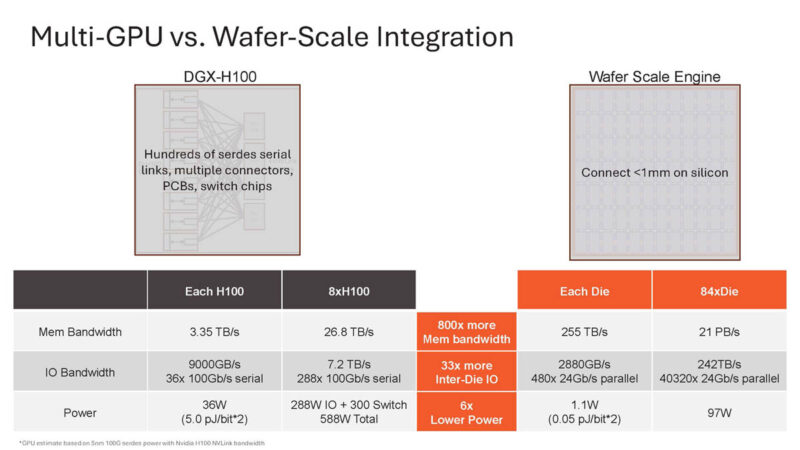
We will let you read this one on why DGX H100 scaling is a challenge.
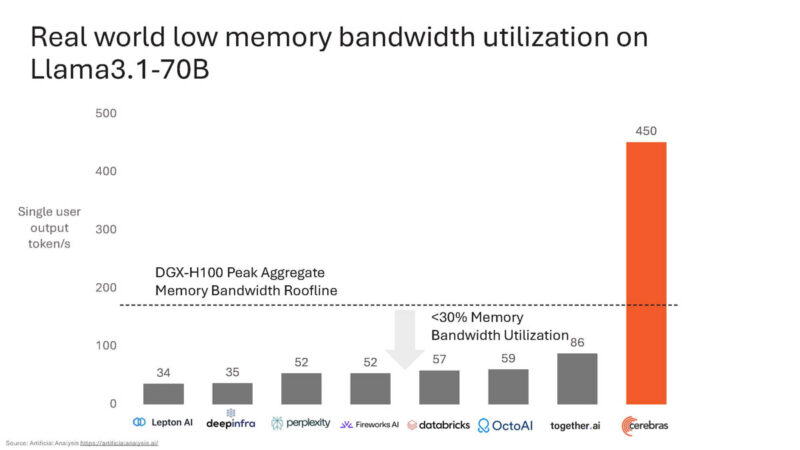
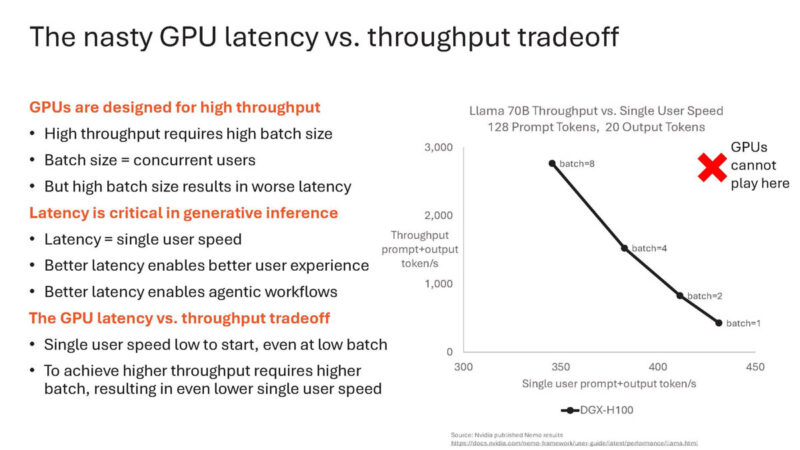
Cerebras put a peak memory bandwidth utilization on the NVIDIA DGX H100 on a chart with how much cloud providers are really getting on Llama3.1-70B inference.
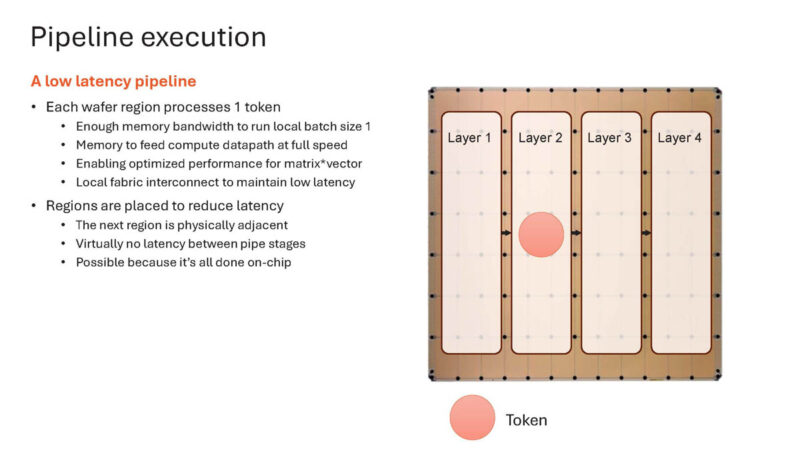
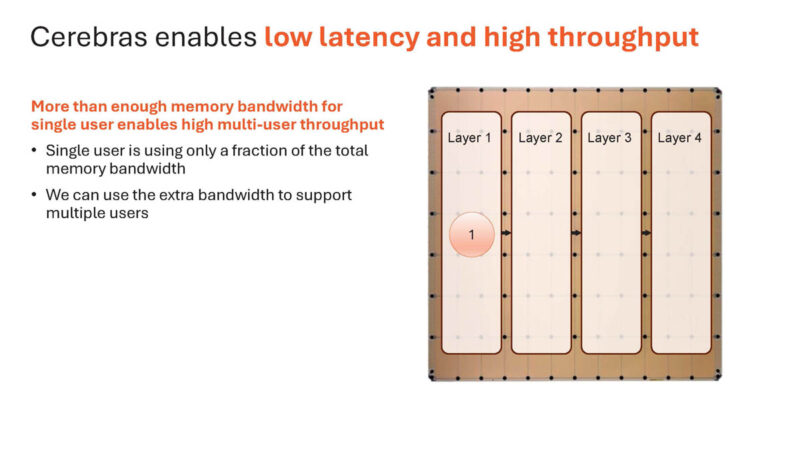
Here is how Cerebras does it on a single chip.

It can place an entire layer on a portion of the wafer. Placing the layers adjacent means, again, means minimal data movement.

As a result of the memory bandwidth, it can run at batch size 1 instead of larger batch sizes.
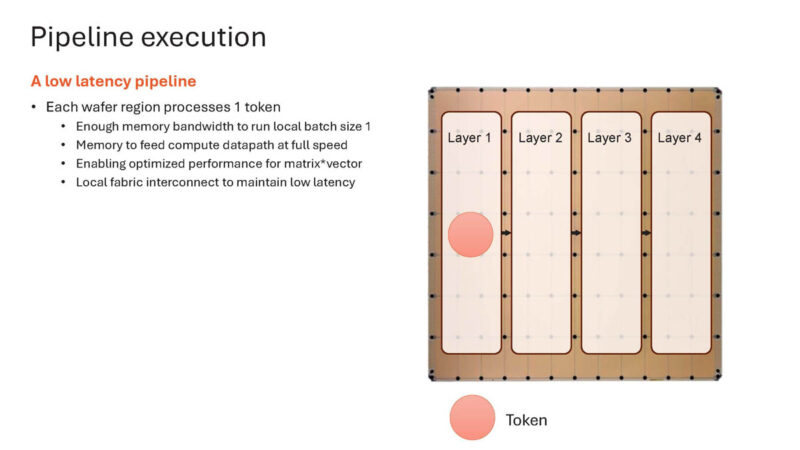
Here is the idea of token generation happening across layers.
Here it is moving again.
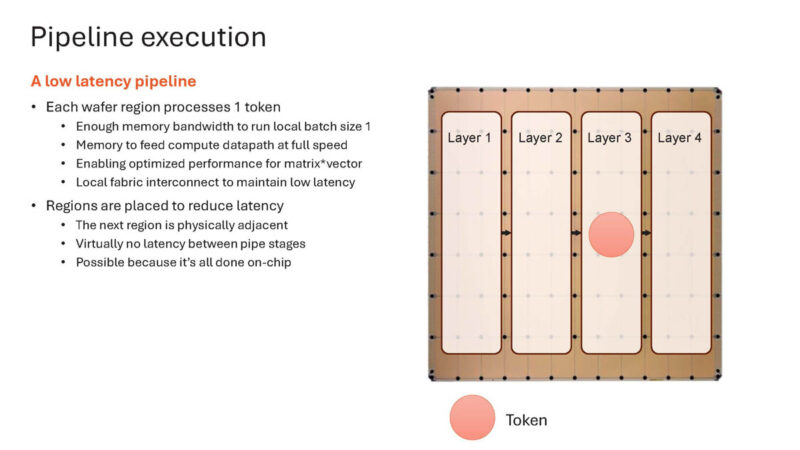
And again (sorry doing this live.)

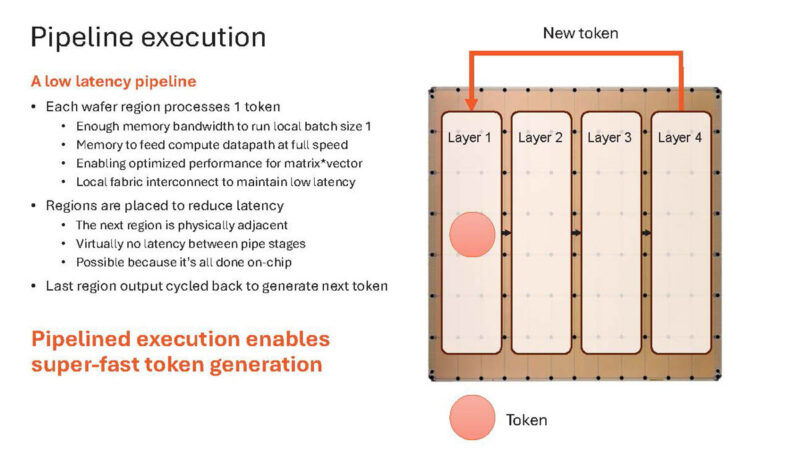
Once it is done, it can move to the next token.
While Llama3.1-8B runs on a single WSE-3 chip.

For larger models like Llama3.1-70B it needs to scale across four wafers.
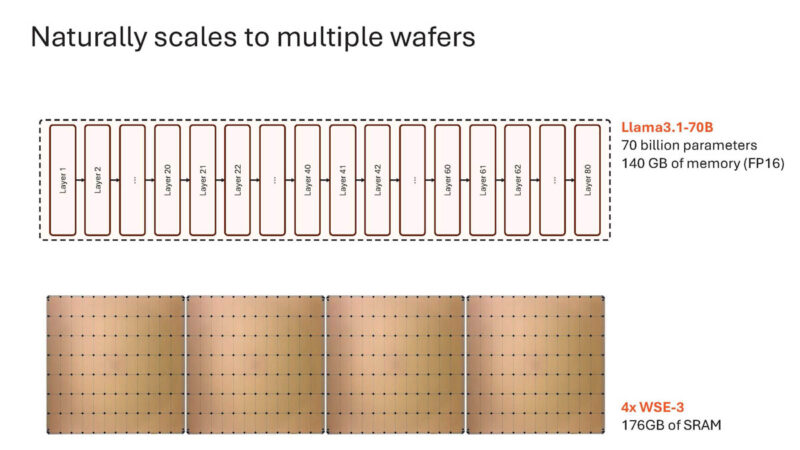
The hops only involve activations between wafers meaning this is not a huge loss of performance.
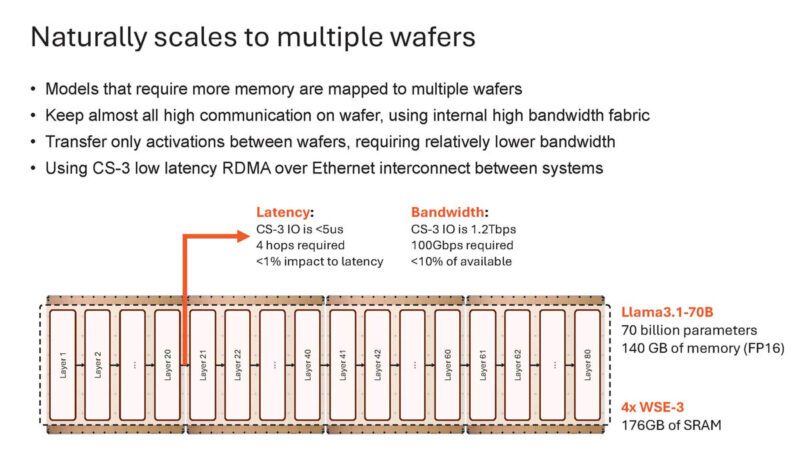
With this scale-out methodology, Cerebras can scale to the latency/ throughput area that GPUs cannot play.
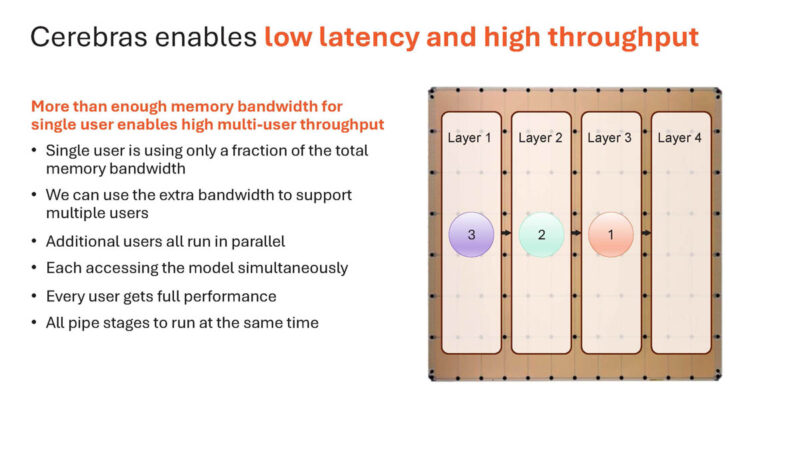
Here is why this works on Cerebras. A single user is only using a portion of the bandwidth of a chip.
As a result, multiple users can be run on the same chip concurrently.
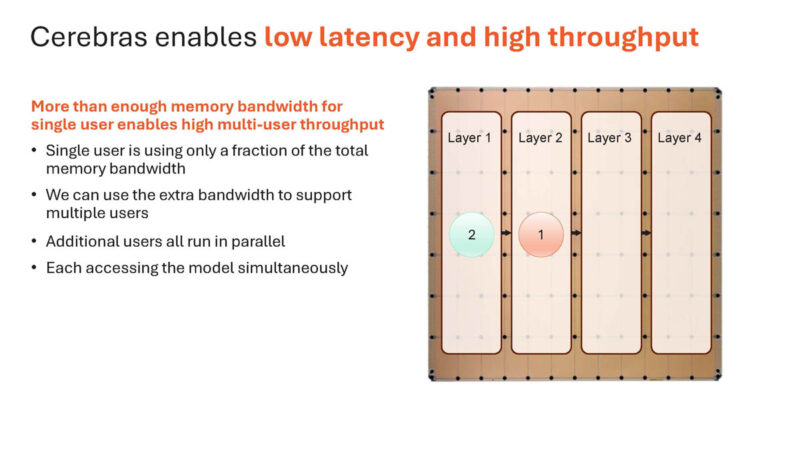
Here is an image with 3.
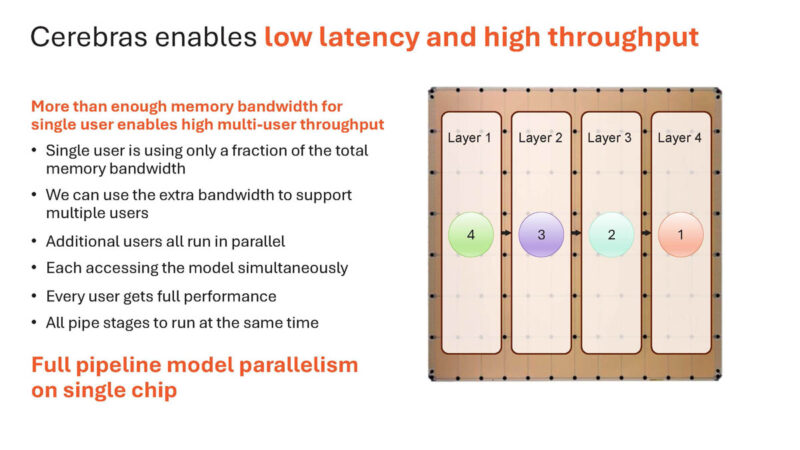
Here is four users on here.
Also, one can process prompt tokens in parallel.
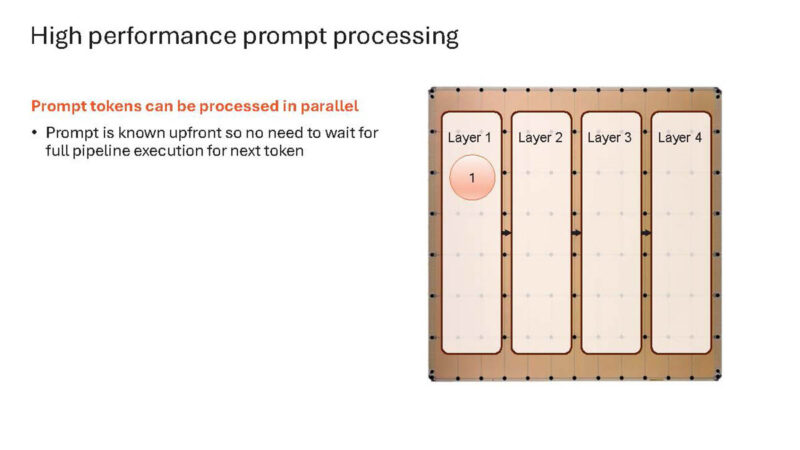
Here is a slide showing this.
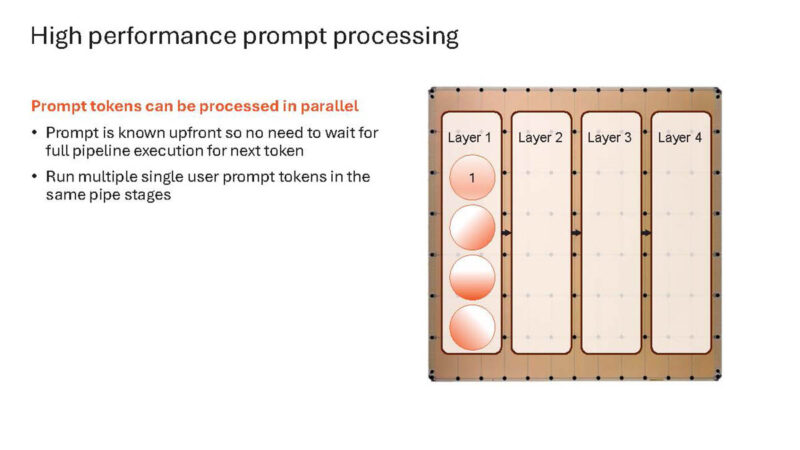
Here is a single user doing more than one operation.
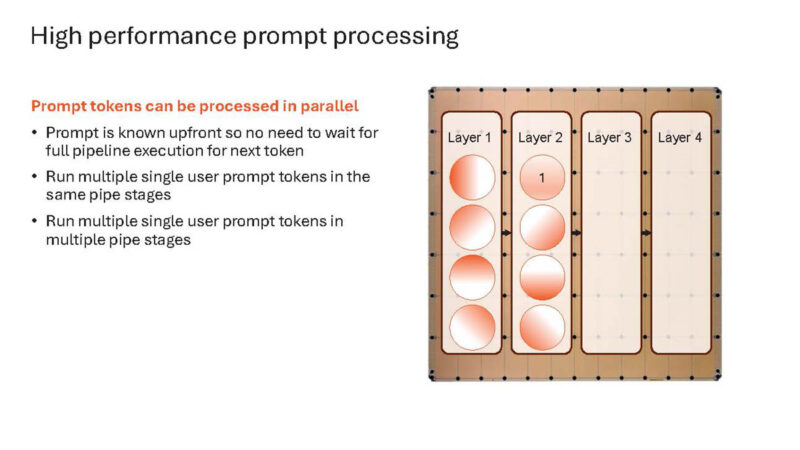
And these build slides continue.
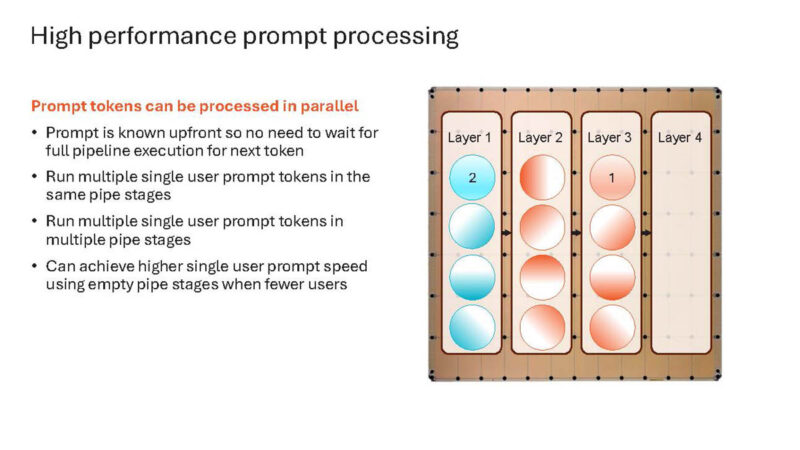
Here are three users working on multiple prompts with different layers on a single chip at the same time.
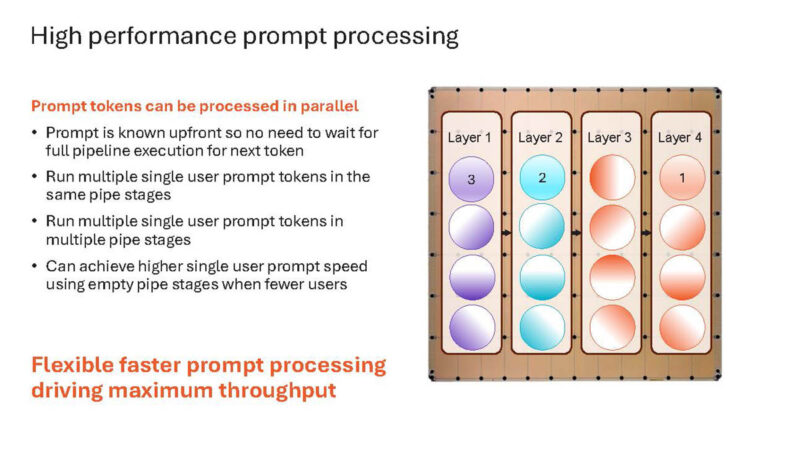
Going back to the chart.
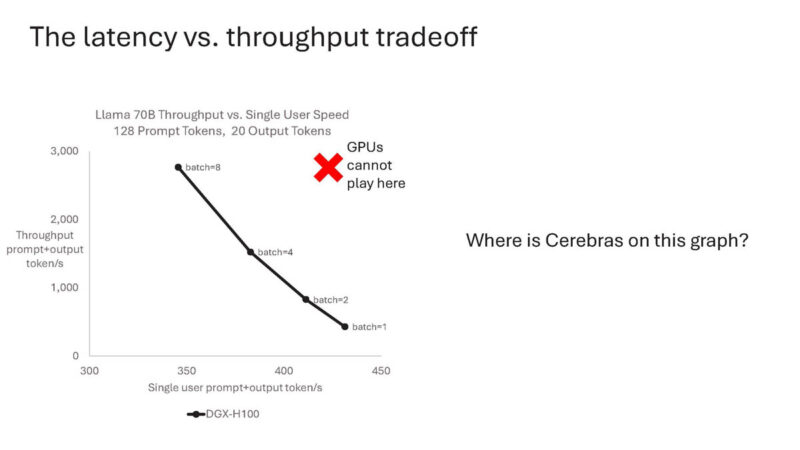
You need to zoom out 10x to see where Cerebras is.
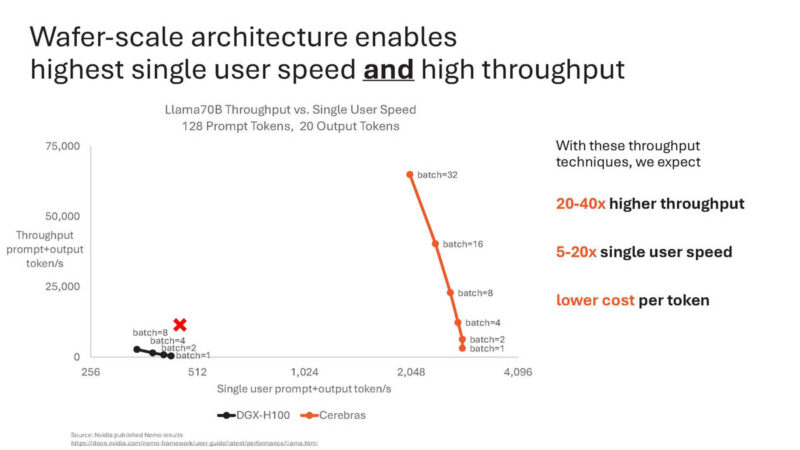
Cerebras says this is just the beginning. The company things it can get more speed and more throughput.

You can use this today using the Cerebras Inference Service.
Here is how to try this. We do not control the QR code so, of course, be cautious there. Something exciting is that Llama-405B is coming as well as other large models.

That is really cool.
Final Words
I had the opportunity to sit with Andrew Feldman (CEO of Cerebras) before the talk and he showed me the demos live. It is obscenely fast.
The reason this matters is not just for human to prompt interaction. Instead, in a world of agents where computer AI agents talk to several other computer AI agents. Imagine if it takes seconds for each agent to come out with output, and there are multiple steps in that pipeline. If you think about automated AI agent pipelines, then you need fast inferencing to reduce the time for the entire chain.



{kind=link}
Their Llama3.1-8B is insanely fast. It’s just wild.
Wafers seem to kick ass. With all happening on-chip, it just eliminates all distant copies (even with the latest NVLink fabric there’s performance hit, it’s power hungry, etc). But how does this work economically (i.e yield, does this wafer cost $$$ millions)? Calling wafer experts.
Yeah… Calling partial BS on that one. They report results here only for small batch sizes (did they even report just batch size 1?) from what I understand. But for any cloud service with users (case that is desirable, it means you have customers), then batch size 1 is not relevant. Pretty sure their advantage disappears for high batch sizes (~128 or more). Same as groq.
The IPO is coming as soon as October! First things first. Then worry about yield rate. If this tech were to exist and could be packaged and sold like Nvidia sells GPUs, it would make a fortune. No need, no reason to be service provider.