
Amazon AWS recently announced a new GPU instance type, with a twist. The Amazon AWS EC2 P4d instances scale up to over 4000 NVIDIA A100 GPUs for those customers who want to run AI or HPC workloads in the cloud.
Amazon AWS EC2 P4d
Before we get to the EC2 UltraClusters, the Amazon AWS EC2 P4d instances that make up these clusters are very interesting. Here is the basic feature set and pricing of the offering:
| Instance | vCPUs | Memory (GB) | A100 | Network | Local Instance Storage | EBS Bandwidth |
|---|---|---|---|---|---|---|
| p4d.24xlarge | 96 | 1152 | 8 | 400 Gbps ENA AND EFA | 8 x 1 TB NVMe SSD | 19 Gbps |
At least slightly interesting here is that we do not have the NVIDIA MIG technology being used. Instead, the EC2 P4d instance type is focused on full GPUs which makes a lot of sense at some level. These systems do get GPUDirect RDMA and P2P.
The CPUs being used are decidedly legacy technology at this point since AWS is using the Cascade Lake generation of CPUs. These are effectively refreshes of the 2017 Intel Xeon Skylake CPUs, albeit AWS has the scale to get custom SKUs built. It is a bit interesting that AWS is launching a new instance on what is effectively 2017 era architecture given other options in the market. Rumor has it, this week STH is going to have an exclusive look at the AMD EPYC 7H12 HPC-focused CPUs to show just how AMD and Intel compare. Even NVIDIA is using AMD EPYC CPUs in its NVIDIA DGX A100 and the first 8x SXM3 NVIDIA A100 system STH will review will be AMD-based not Intel-based to take advantage of PCIe Gen4. For its part, AWS has Graviton 2 which is a key example of the NVIDIA-Arm partnership (and pending acquisition.)
One also gets up to 1152GB of memory with the 96 vCPUs. There are eight NVIDIA A100 GPUs. Given the 400Gbps figure, it seems like Amazon is building the machines behind these A100 instances around a standard NVIDIA HGX-2 baseboard with NVSwithces. We have a 2:1 GPU to NIC ratio which we have seen before. See our Inspur NF5488M5 Review A Unique 8x NVIDIA Tesla V100 Server to see a Cascade Lake system with this networking and GPU ratio.
The AWS P4d instances are powered by the NVIDIA A100 GPU, but there are a lot of similarities between what AWS is using and what you can find. Inspur, for its part, said that system will support “Volta NEXT” which is Ampere (A100) but it has also transitioned to AMD EPYC 7002 for its A100 model. That is significant because it is Inspur’s first AMD EPYC system for its cloud customers. Our sense is that a fully-configured OEM system with similar hardware specs to the P4d machines, plus data center (power/ space/ cooling/ installation/ networking) will cost around the same as the 1-year reserved instance pricing so if you plan to use these systems continuously, your payback is about a year for the hardware and operating costs exclusive of the software and capabilities that AWS brings.
| Instance | On-demand Price/hr | 1-yr Reserved Instance Effective Hourly * | 3-yr Reserved Instance Effective Hourly * |
|---|---|---|---|
| p4d.24xlarge | $32.77 | $19.22 | $11.57 |
We also get platform features such as 8x 1TB of local storage and these solutions are using AWS Nitro for management. If you have seen our DPU coverage, you can see how the rest of the industry is trying to create solutions to address the AWS Nitro model. See our: What is a DPU A Data Processing Unit Quick Primer piece about that.
While the nodes themselves are interesting, the power of what AWS is doing goes beyond the simple node.
Amazon AWS EC2 UltraClusters
Here is the quick diagram of the NVIDIA A100-based AWS EC2 UltraClusters:
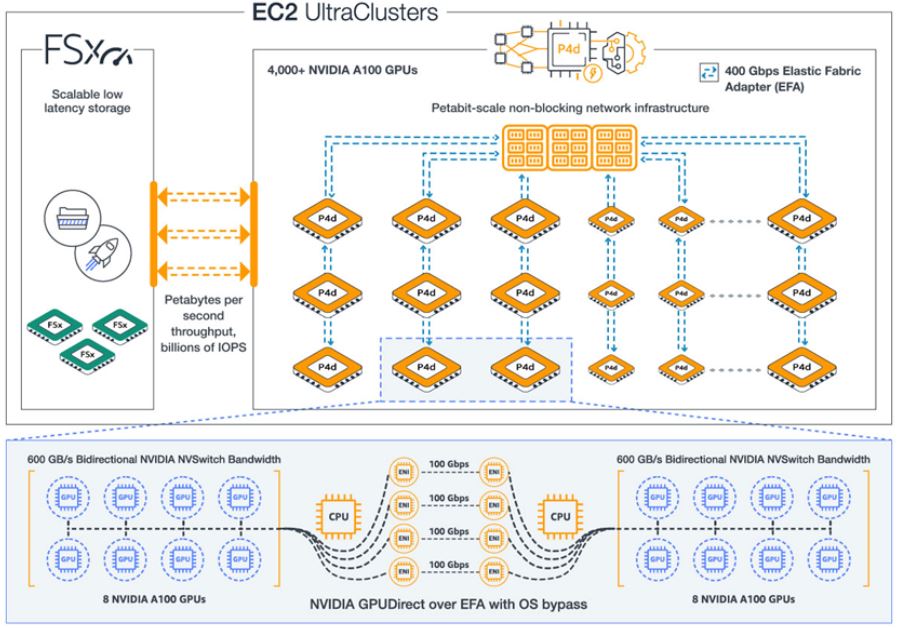
That is effectively a standard HPC style deployment that is put into AWS context. With over 4000 GPUs, that means that AWS must have at least one cluster of over 500x 8x A100 machines. In many cases, cloud providers require some sort of customer qualification to access this scale of infrastructure which makes sense.
Beyond the compute, AWS has its software stack along with FSx which can bring high performance and low latency Lustre storage to the cluster via the AWS Elastic Fabric Adapter (EFA) model.
Final Words
This is a big trend in HPC. Companies like Microsoft with Azure’s HPC as well as AWS are building HPC clusters that are consumed in a cloud model. For deep learning systems, we see some prototyping done on smaller-scale systems, but most larger solutions involve thousands of GPUs. The STH test lab is in the same Sunnyvale, California data center as the Zoox Silicon Valley training cluster. Amazon acquired Zoox as part of its self-driving car ambitions (and hello to our readers from Zoox!) Clusters for these types of heavy AI workloads use thousands of GPUs which require dedicated teams to manage the infrastructure. For many customers who are not going to need clusters at that scale, having AWS manage the solutions as EC2 UltraClusters and consuming the compute capacity as another resource managed with familiar AWS environments is very appealing.



{kind=link}