
After coming back from OCP Summit 2021 and then SC21 over the last two weeks, something that a number of folks told me at the shows is that while the 3rd generation Intel Xeon “Ice Lake” may not have a core count advantage anymore, some of the accelerators are actually a big deal. The folks telling me this were either large hyper-scalers or vendors that sell to the hyper-scalers. Something I realized is that we typically do not do a great job of getting that acceleration story out. As a result, I wanted to show this a bit. Specifically, since AWS re:Invent is coming up soon, I thought it might be a good idea to look at the current m6 offerings and just do a comparison.
Some Background
When AWS shows benchmarks, a lot of what they show are fairly simple use cases and they are usually assuming that one has taken advantage of their Graviton/ Graviton 2 parts more than what it assumes for its suppliers/ competitors parts. We know that in the Ice Lake generation Intel has features like VNNI and INT8 support for inferencing. Intel has had generations of crypto acceleration. We even showed a slide on this acceleration with our Intel Xeon Ice Lake Edition launch piece, but this acceleration does not show up in our normal testing.

As part of that effort, I went to Intel and asked for support for this one so we are calling this a sponsored article. This is something that basically I got the go-ahead on a Friday morning call and I wanted out this week before re:Invent. As examples, Intel helped with making sure the acceleration libraries would be called properly (usually it is an extra step to call these) and Intel is paying for the AWS EC2 instances being used. As always with STH, this is being done editorially independently and this article was not shared with Intel before going live, but I just wanted to call this out. STH has a lot of resources but sometimes calling someone helps. Before folks get too excited here, AWS instances specifically because: 1) they have the next event coming, and 2) AWS wins no matter which instance you choose.
For “hardware” these are all running in AWS and the 4xlarge instances are being used. So for Intel Ice Lake, that is the m6i.4xlarge, and for Graviton 2 that is the m6g.4xlarge. Of course, the underlying the m6i is an x86 Xeon and the m6g is an Arm-based Neoverse N1 part that is exclusive to AWS.
Both of the instance types provide 16 vCPUs and 64GB of memory. The m6i.4xlarge is $0.768/ hr on demand while the m6g.4xlarge is $0.616/ hr on demand. We are not going to get into the fact that the m6i has a 25% higher potential network bandwidth or scaling to other instance types or anything like that. We are just using 4xlarge instances.
As a quick note here, a lot of folks will look at the CPUs and say that Arm is cheaper and that is driving the 19.8% delta. Realistically, AWS does not price its offerings like “something costs $1 so we are going to mark it up 10%.” AWS prices its instances, as it should, based on the fact they are in the AWS infrastructure with all of the AWS offerings around the instances. AWS and other cloud providers pay a small fraction of what a small/ medium business would for similar hardware. Graviton 2 is a way for AWS to transition its customers onto its platform and get more vendor lock-in so it prices this at a discount. Companies have to do porting work to Arm and basically build/ tune applications based on the AWS CPU profile. It is a similar lock-in mechanism to what AWS does with bandwidth where ingress bandwidth is free, but egress bandwidth is extremely expensive. That is another topic, but suffice to say, we are not comparing Intel Xeon Ice Lake to Graviton 2 as chips, we are comparing the m6i.4xlarge to the m6g.4xlarge instances. That is a big difference.
We also have a video version of this that you can find here:
As always, we suggest opening this in its own browser, tab, or app for the best viewing experience. With that, let us move on.
AWS Intel Ice Lake (with Acceleration) v. AWS Graviton 2 Two Examples
For the two examples here, I wanted to specifically show some of the Intel acceleration points. These do take additional steps to tell the environments to use the acceleration. Some folks will not use it. If you are doing the least common denominator benchmarking, and that is very common with some of the marketing we see, then it is easy to just not use them. Indeed, normally when we do least common denominator benchmarking, we skip these accelerators. In the future, these accelerators are going to be a bigger part of the story, so for 2022, we are going to have to lean into them. We are going to use two basic cases: WordPress hosting and Tensorflow inference performance.
Looking at WordPress
Commonly when folks do web server testing, the webserver testing folks do is often nginx with relatively simple pages. Often we see HTTP benchmarks while the web has moved to HTTPS. So here we have a bit of a longer chain. We have nginx as the webserver. Since we are running WordPress, we are using PHP 7.3. If you have ever run nginx, you will know this actually means we are using php7.3-fpm. MariaDB is used for the database. Personally, I have used this quite a bit. Seige is being used to generate the load from the instance since I did not want network jitter to be an issue. For those wondering, this is basically the WordPress setup for the old Facebook oss-performance.
Intel likes to show its crypto benchmarks showing an acceleration of the raw crypto performance (see above.) My stance is basically that while things like SSL are a foundational technology, there are not many servers out there doing solely these workloads 24×7. So WordPress gives us a bit of a web front end, with crypto, and database. WordPress is ultra-popular and most that use WP these days will also have HTTPS sites so it seems like this is a fairly common VM workload (albeit a 4xlarge is probably too big for most WP sites.) Cypher wise we are using TLS_AES_256_GCM_SHA384. Since STH is a Ubuntu shop, we are using Ubuntu 20.04.3 LTS.
Here is the basic results chart:
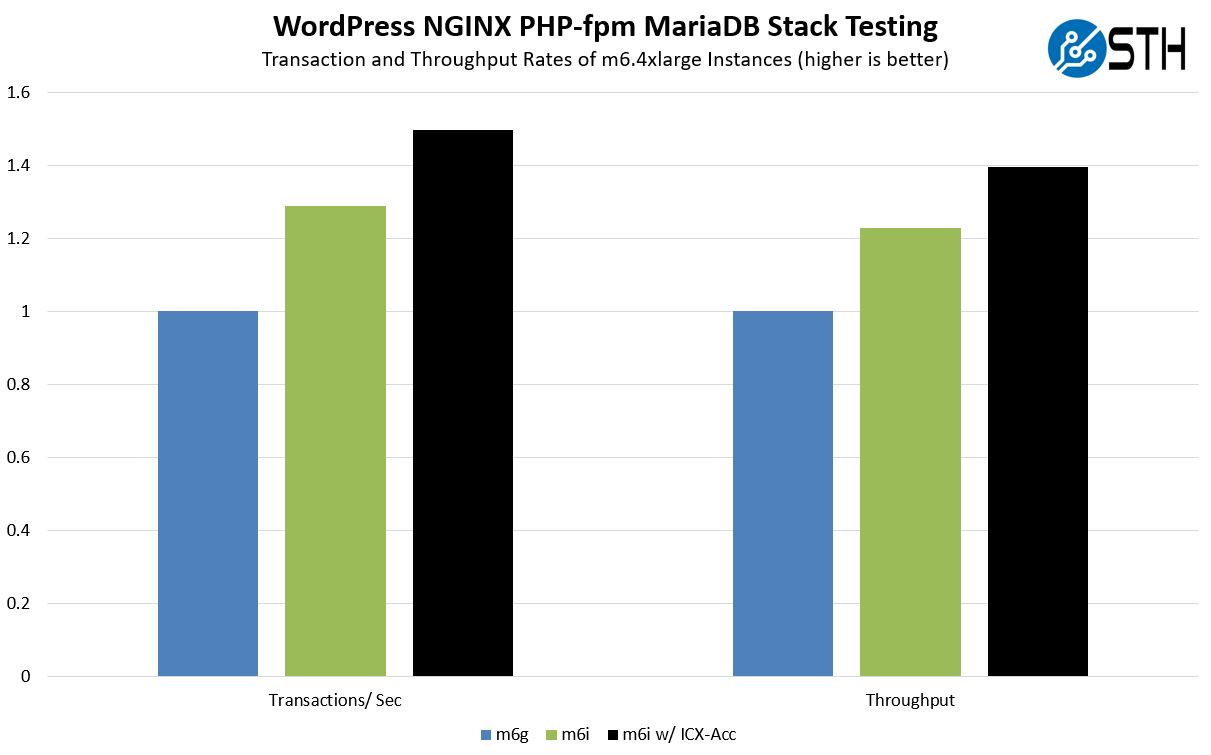
There are three sets of results. The m6g is the Graviton instance, the m6i is the unoptimized Ice Lake platform. Intel usually does not show this one, but I thought it was relevant. Finally, we have the Ice Lake accelerated solution. Without the Ice Lake-specific crypto acceleration, the m6i is roughly 29% faster. With the Ice Lake-specific crypto acceleration, it is roughly 50% faster than the Graviton 2 instance.
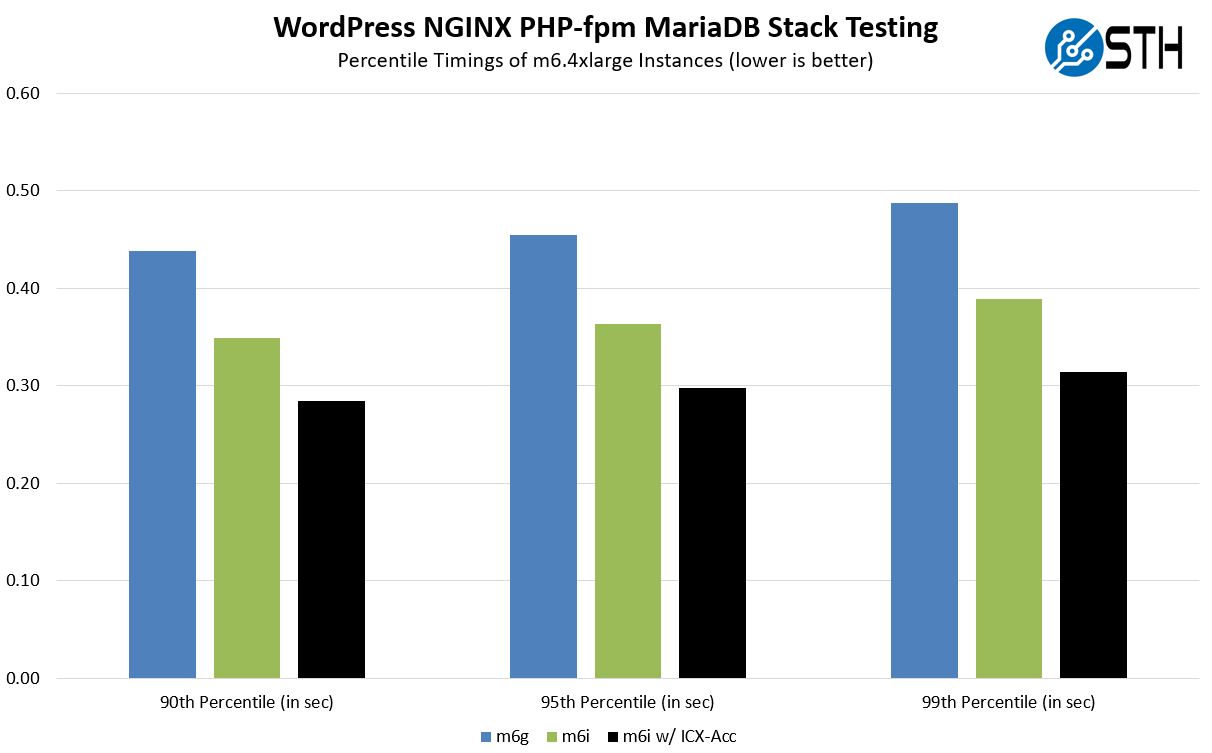
We also get better tail latencies. The one area that we do need to point out is that the fully accelerated platform is running at a higher CPU utilization rate in order to achieve this.
This is certainly nowhere near what the solution would look like if we were to look at a standard like 100% crypto acceleration, but also shows the value of the acceleration.
Tensorflow Inference
This is a really interesting one for folks. There is a lot of wisdom in simply stating that if you are doing AI inference, it is time to get a GPU. NVIDIA has been a big beneficiary of this and one can spin up instances with GPUs for usually a bit of a premium over standard instances. Something that I hear pretty consistently is that there are a lot of applications out there where AI inference is used, but it is only a small portion of the overall workload. So having on-CPU AI inference is useful because it saves you the cost of needing a GPU accelerated instance. That is especially true if you are going to have low utilization of that GPU.
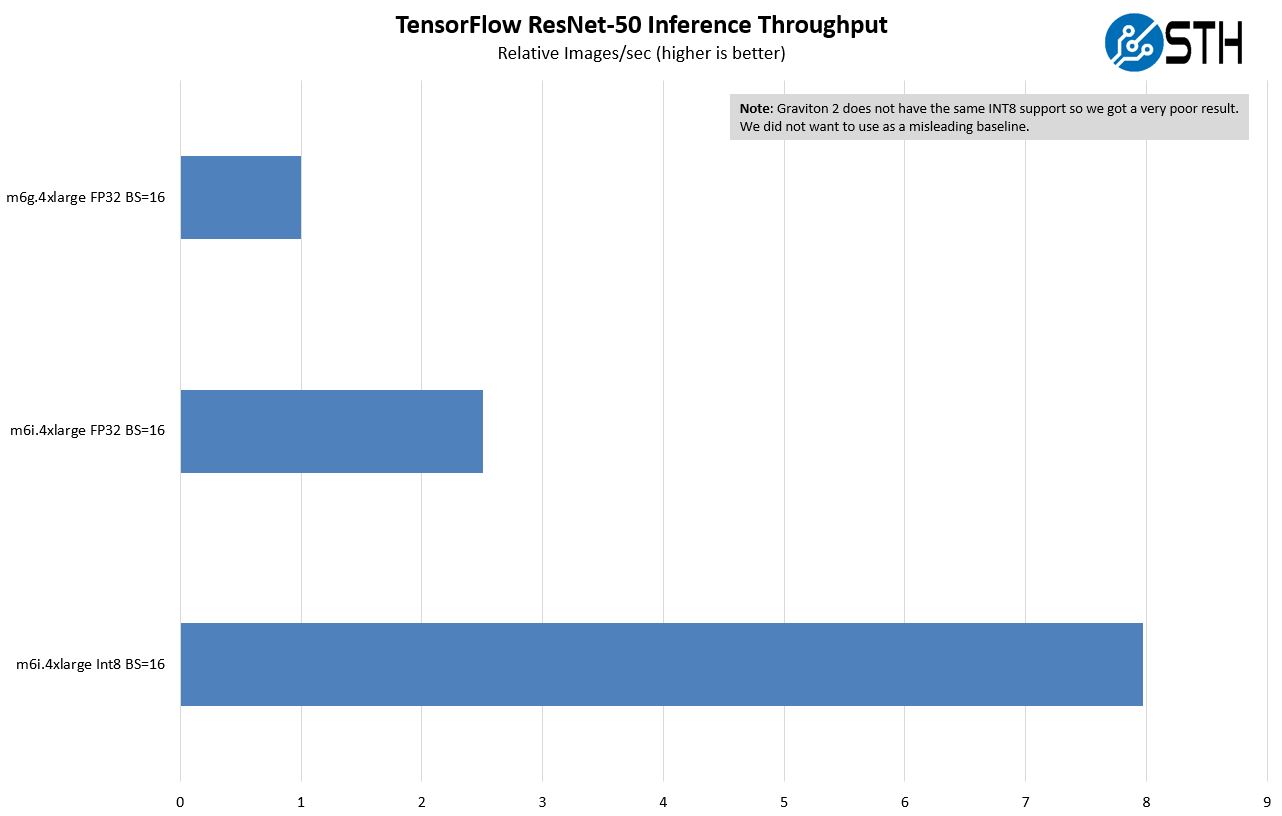
For this one, this is a case where Intel has an accelerator and Graviton 2 does not. Being up front about this, this is one where we would expect Intel to perform much better. Here we are using a ResNet-50 inference via Tensorflow. We are showing both FP32 and INT8 and then doing throughput using a batch size of 16 and latency using a batch size of 1. Two items we have to note here. First, we are basically using physical cores here. So we are using the Graviton as a 16 core instance and the Ice Lake system as an 8-core instance. Somewhat ignoring hyper-threading. That was the best case for both AWS instances. Second, we are using the oneAPI oneDNN here. I needed help from Intel to get this to work so I am going to call that out. I could have read all of the documentation, but sometimes it is faster to just phone a friend.
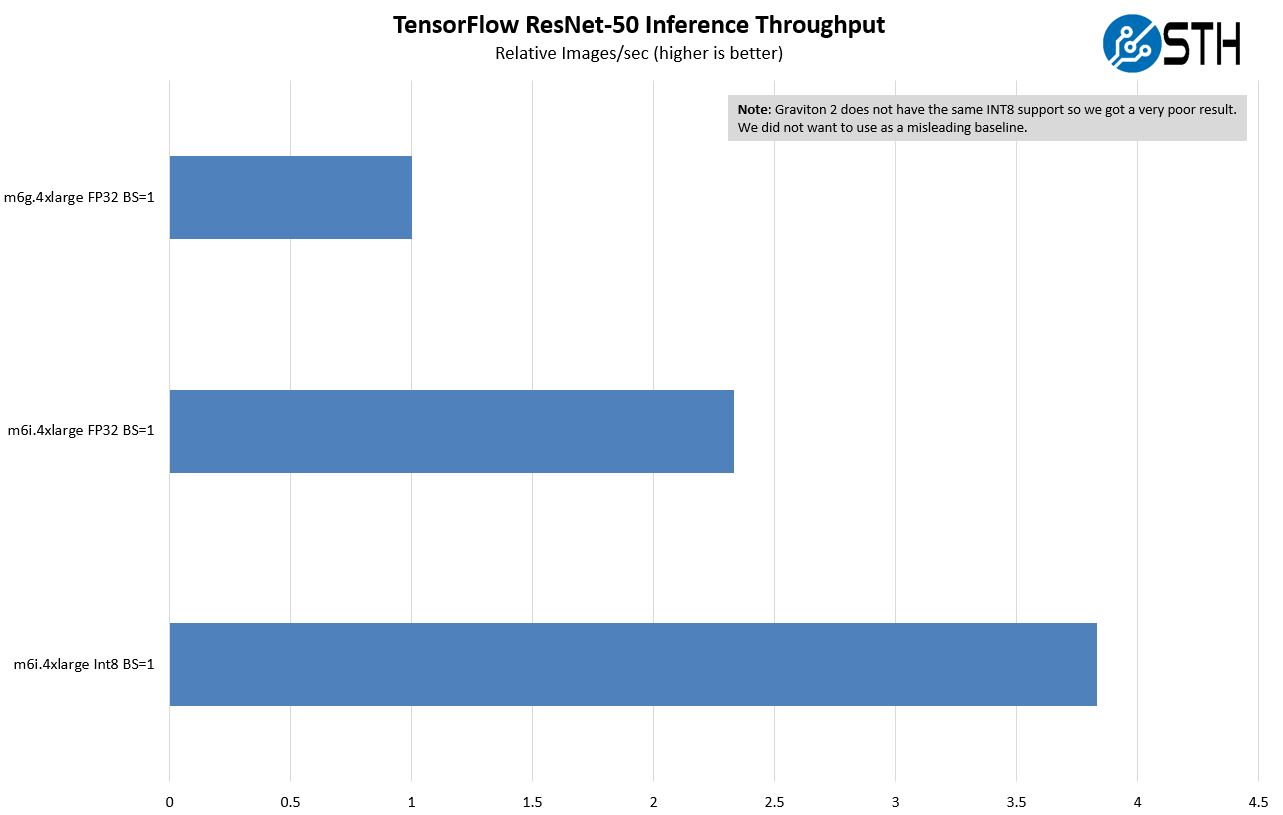
The results are fairly stark, and what we would expect. The AI acceleration (part hardware part oneDNN), especially with INT8 is a big difference. Again, this is completely an expected result. We are not putting the m6g.4xlarge instance on these charts because the performance was poor. Again, that makes sense since it is not something that Graviton 2 was designed to handle.
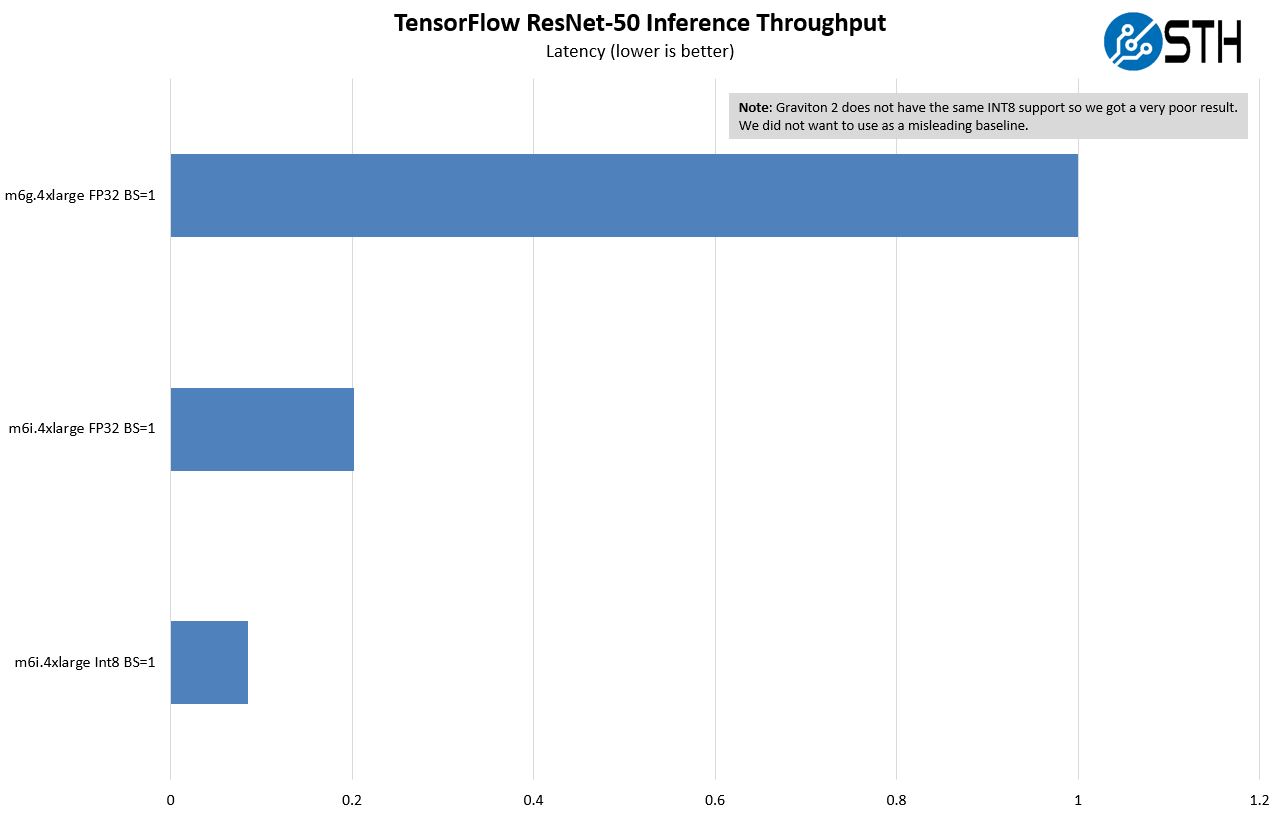
All of the major chipmakers are looking at adding their flavor of AI inference acceleration in future designs, and this is why. This is a case where Intel just did something a bit earlier. This may not be enough performance to stop one from using a GPU for everything, but for many it may be enough to avoid the extra step and extra cost of spinning up GPU instances.
What is very interesting here, and I heard folks talk about this at the recent shows is that NVIDIA focuses on maximum GPU inference acceleration. Intel is focused on providing a base level of inference acceleration without an accelerator (but actually sells a lot of products for inference.) That shows in the MLPerf Inference results. This is really a sign of things to come in the future.
Final Words
One of the big reasons that I wanted to do this article specifically is that the world of CPU performance is changing. We used to be able to simply know the rough IPC of an architecture, multiply by cores and clock speed, and have some sense of what it can do. In 2022, that is going to start changing more and more. We did not do a great job showing this acceleration at the initial Ice Lake launch so I wanted to circle back to it.
Perhaps the big takeaway for our readers is that deciphering CPU performance going forward is going to be a lot more personal and will require a lot more thought. Often when vendors talk about accelerators they show workloads that are 95%+ utilizing the accelerators showing outsized gains. Realistically, many real-world workloads are going to have more like muted responses to accelerators, but they can still have a big impact.
One of the big challenges for STH, and our readers, especially as we get into 2022 and beyond, is how to describe the differences we see using these accelerators. For this, we tried to show some broader application usage. We are going to have to get there for the next generation of servers. If we do not, then even simple use cases like looking at AWS m6 instances will miss a big part of the story. Beyond that, with cloud providers, like AWS, making their own chips, for the implicit purpose of locking-in users to a cloud, that becomes another discussion on how portable workloads become if you cannot buy a server from other vendors with the accelerator. Customers should demand portability. For Intel’s case, one can buy an Ice Lake system and put it in colocation, but that is not possible for Graviton 2. That adds another layer of complexity to how we dod reviews. For 2022, we are going to have a lot of new ground to cover that is going to be a lot different than just a decade ago.



{kind=link}
Great idea to spot a light on AI acceleration with (Intel) CPUs. Do you have plans for a piece on avx-512 computing on dedicated platforms like the 8-cpus Supermicro Big/Fat twins, either with Ice Lake or with the upcoming Intel/EPYC chips?
Nice piece. I’ve always wondered when you’re saying AI acceleration in Ice Lake if Intel had frameworks. I just looked up oneDNN because of this.
Other sites are so hostile towards x86 and don’t even do basic optimizations. Like someone spending tens of thousands per year on a few instances won’t spend $3k on an Intel compiler license to save $30k.
It’s gonna be hard to show this as we get more chips, but you’re right you’ve got to.
It’s curious how AWS didn’t show this Ice and Graviton when they released M6i’s
Many companies do not use GPUs for inference and even training for the reasons you mentioned, glad to read it. Especially for some applications where there is continuous training on small training batches, then using CPUs is actually better.
For the mention of sponsoring: if there was monetary compensation for this article, it would be great to have it stated in the title; if there was not, then calling it a collaboration seems better.
Really, TLS termination performance is irrelevant because for the vast majority of the use cases TLS termination should be done at the edge, not on the server*.
Also, many of the AWS workloads are script-based (python, node, etc) so there’s basically no work to transition away from x86_64 platforms. As an example, WP on AWS/ARM runs just fine for substantially less than AWS/x86.
* unless for regulatory reasons you need end-to-end encryption
Whoa. So you’re doing unencrypted inside the infrastructure with edge termination mannyv? How quaint. Troll somewhere else.
I would be interested in *how* you made use of the acceleration. Is it just preloading some Intel libraries in place of the ones provided by the distributions?
You’re brave. You’re going to upset the AWS and Arm fanboi’s with this. You’re also correct, we’ve got a setup, in production, that isn’t too far off from what you’re testing and we get like 45% better performance with i over g so you’re close to what we really see across 100’s of instances on that app.
I like that STH can present both sides. AT’s gone full Arm fanboi these days.