
At Hot Chips 2023 (35) Arm showed off the Neoverse V2 cores that are known to power NVIDIA Grace CPUs. At the conference, Arm is talking about the cores. This is one of two talks that Arm has at the conference. The CSS one we will cover later today is another one.
Since these are being done live from the auditorium, please excuse typos. Hot Chips is a crazy pace.
Arm Neoverse V2 at Hot Chips 2023
The Arm Neoverse V2 is part of the current generation of Neoverse solutions. Arm is working to provide reference cores for the data center and infrastructure markets. Neoverse V2 is more of a high-performance data center CPU core while N2 is more for infrastructure.
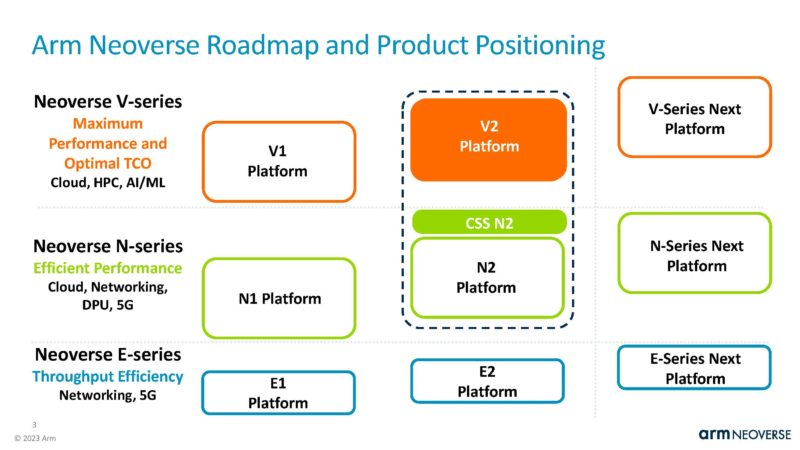
We have covered Neoverse V2 previously, but the goal was to improve performance over the Neoverse V1 design that is used by companies like AWS in the Graviton line.

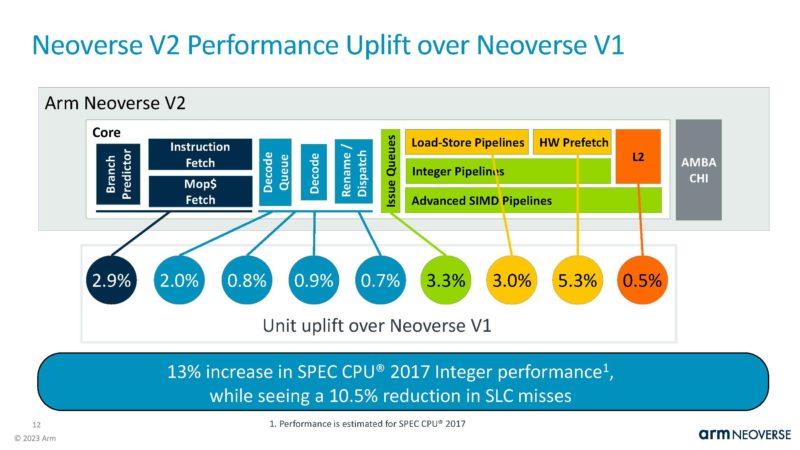
The Arm Neoverse V2 is an Armv9 architecture. This is a chart showing some of the highlights of the core.
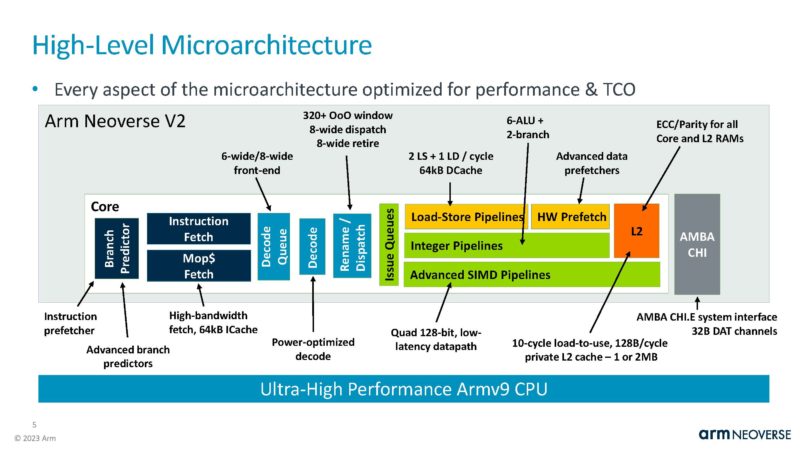
On the branch predict/fetch/ICache is partly shared with Neoverse V1 but with some major improvements. Arm is showing the performance impact of these changes in each section which is pretty cool.
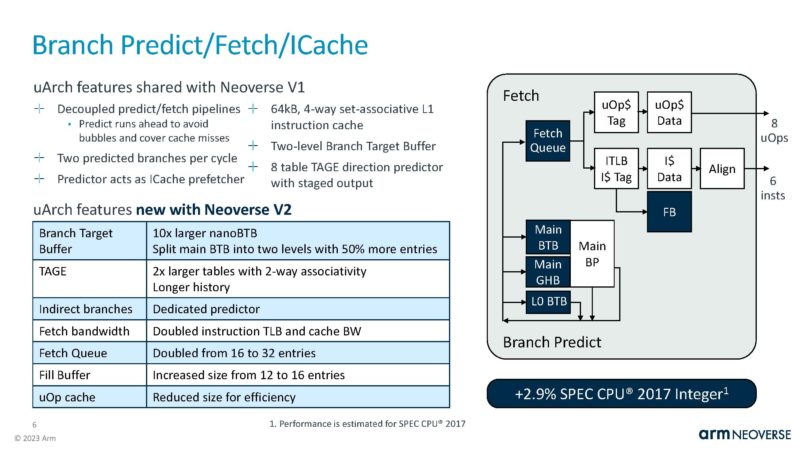
This is a theme of V2. It is largely a V1 with upgrades along the way with more resources.
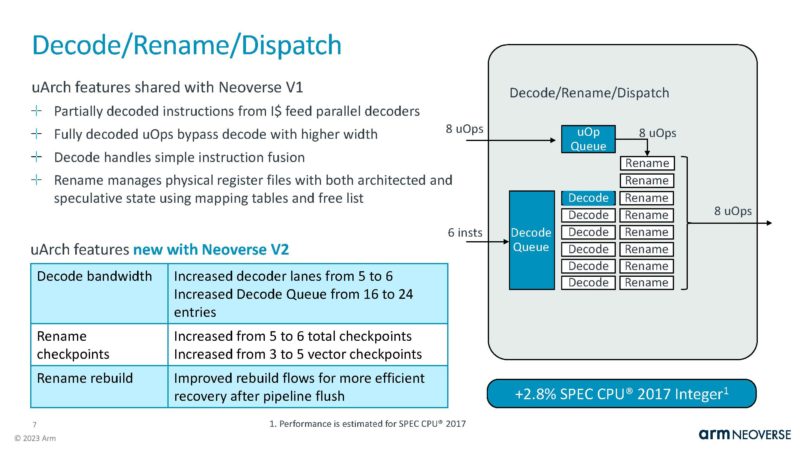
The issue/ execute side was a big change in V2.
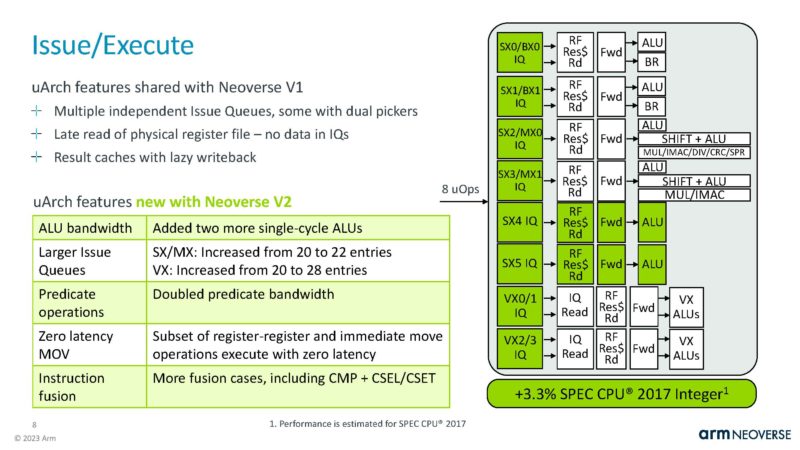
The Load/Store and DCache saw changes like the TLB increase by 20%.
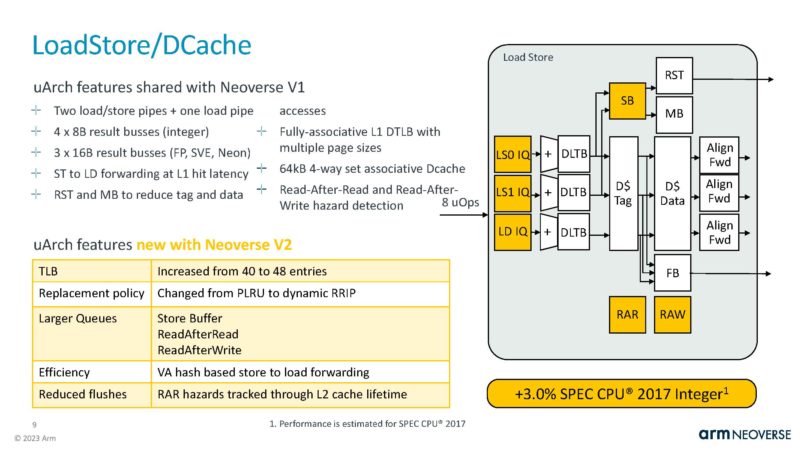
That also means that Arm needed to improve the hardware prefetching of the cores to keep the execution units and caches fed.
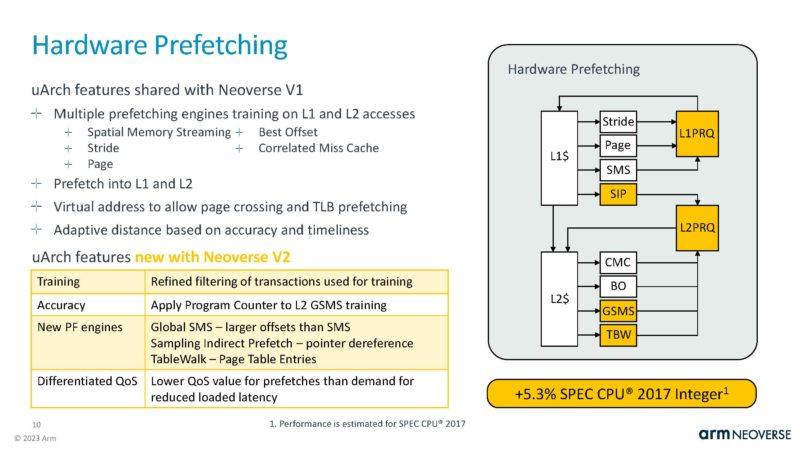
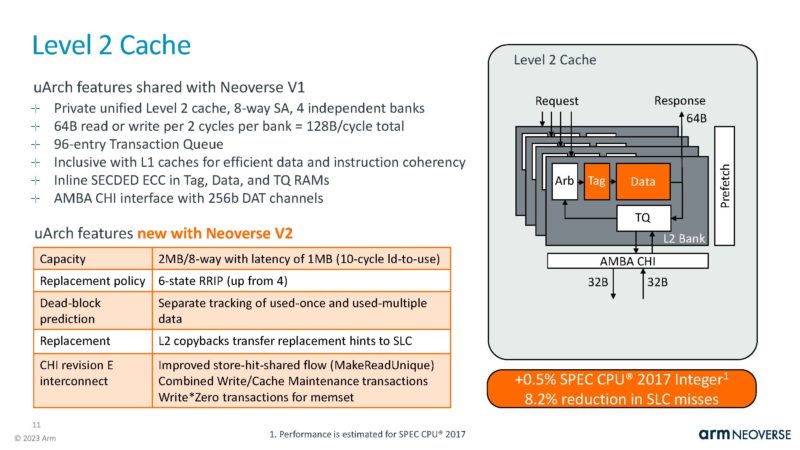
The L2 cache is private to each core, and important characteristic in the data center. This was a smaller SPEC Int gain area.
Arm says these V2 changes combine for around a 13% increase in performance per core over V1. The numbers for each of the sections do not equal a 13% increase if added. That is because some changes impact others so the total is smaller than adding each individual area of improvement.
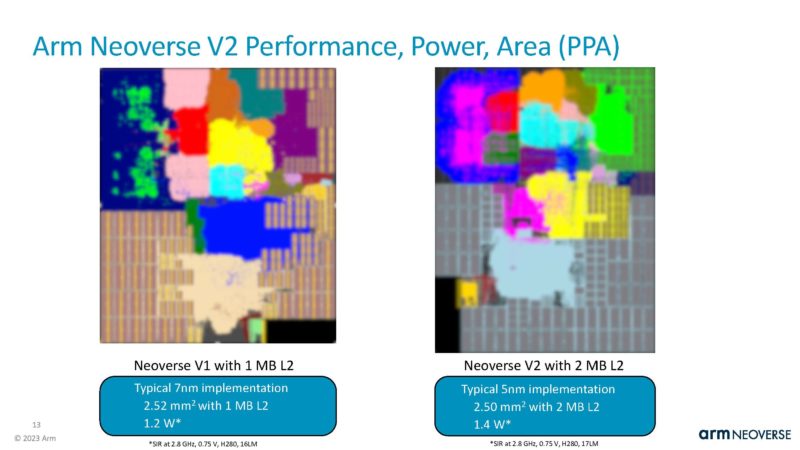
Arm says that shrinking from TSMC 7nm to 5nm the new cores only use around 17% more power and are roughly the same area, despite doubling the L2 cache. It is interesting that Arm on the above slide says V2 is 13% faster but below uses 16.666% more power.
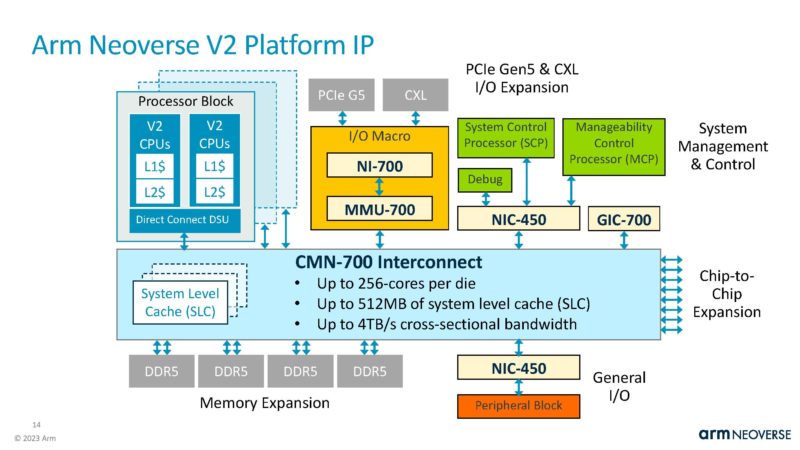
Beyond the V2 cores themselves, the platform has features like the CMN-700 interconnect for more cache and increasing core counts. For Arm Neoverse cores, that is the core, not the entire chip so items like PCIe Gen5 IP need to be sourced.
Here are the assumptions for the performance results:

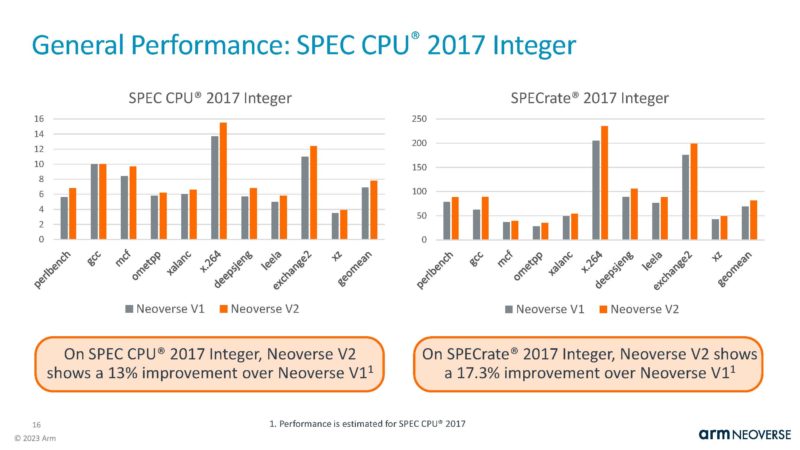
Arm is showing its integer performance. On a pre-briefing call, our Chief Analyst, Patrick, asked about the difference between the two estimates results as the right chart is labeled “SPECrate” but neither are labeled as base or peak. Arm was not able to confirm this. Our best guess is that the left chart is base and the right chart is peak but that is just a guess since Arm was not able to confirm what they were showing.
These results are estimated only, but here is how the real submitted results look where results are labeled with base and peak. It is amazing that a CPU company was unable to answer this.
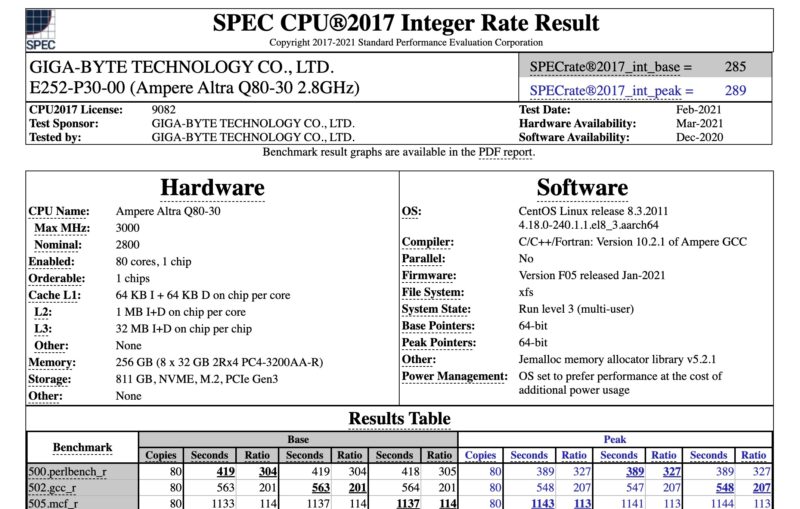
Here is Memcached which is usually less CPU bound and more memory/ cache bound. It is another integer not a floating-point workload. As a result it typically does well on Arm CPUs.
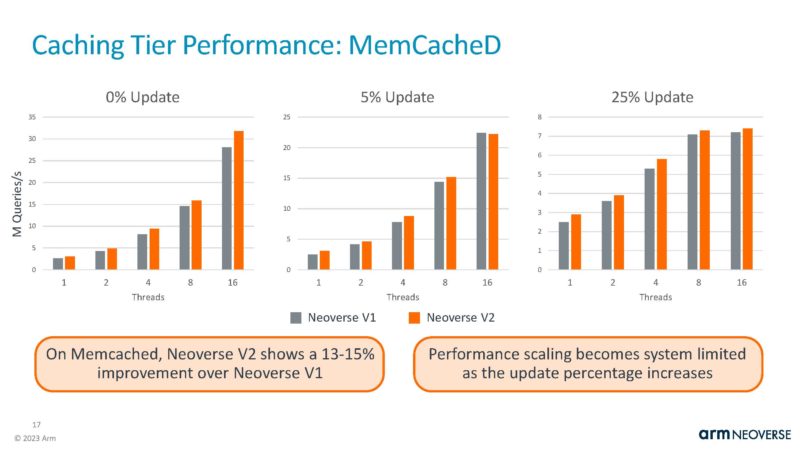
Nginx is a popular web server. This is another one that is integer dominated and therefore has been a mainstay of showing Arm server performance.
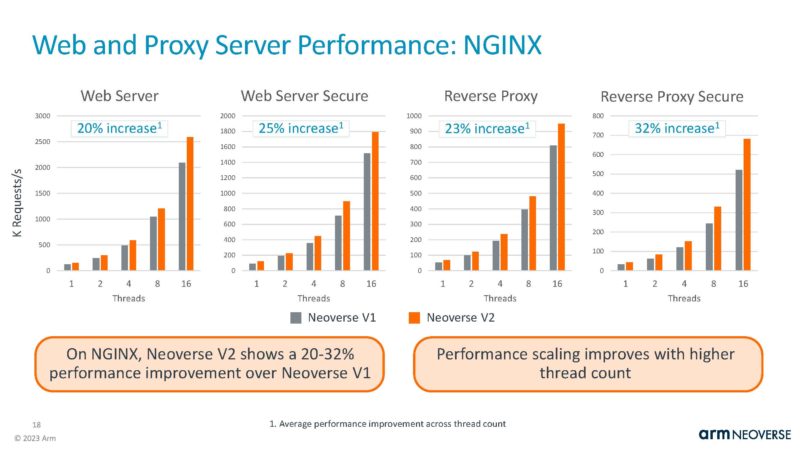
Here is another in the integer workload benchmarking trend. This one gets a bigger boost.
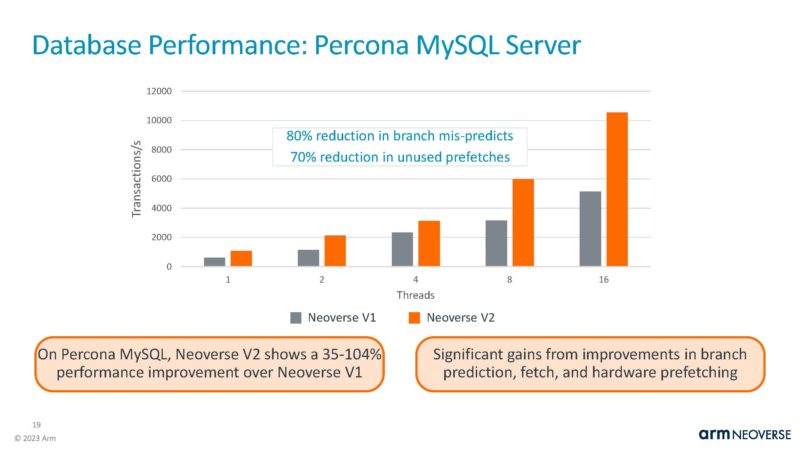
Here is the XGBoost performance.
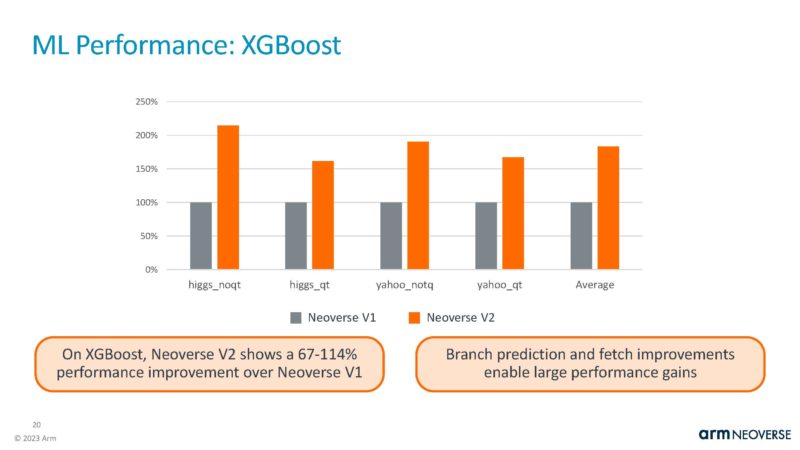
This is being used in the NVIDIA Grace Superchip and Grace Hopper. These are largely memory bandwidth-sensitive workloads. The correct comparisons for the Grace Superchip would have been Intel Xeon Max and Genoa-X. STH has had both Xeon Max and Genoa-X for months, so these should have been included.
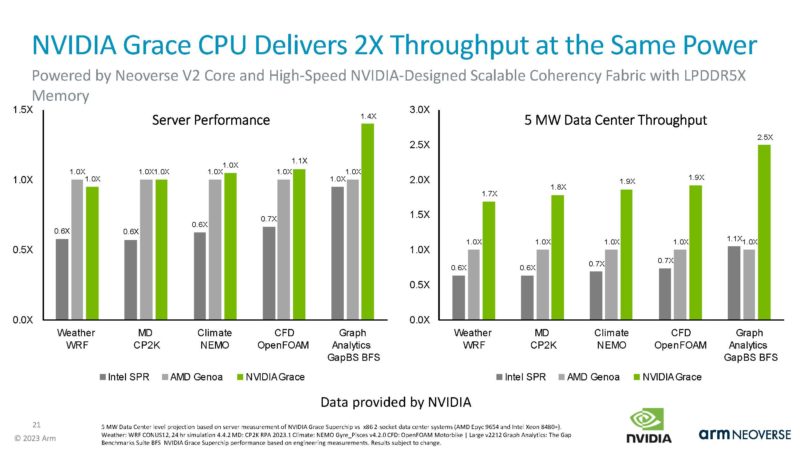
Here is the platform summary.

The NVIDIA Grace Superchip is the poster design win for the core.
Final Words
The Arm Neoverse V2 cores are very cool indeed. We are excited to get to use the Grace Superchip in the near future. Stay tuned for the Neoverse N2 CSS coverage in a later session today.



 and its performance gains over Neoverse V1 processors){kind=link}
I don’t know how you can buy a server proc from a company that doesn’t even know what the #1 bench used is. That spec is ALL #facepalm
That’s the worst benchmark slide since the last Ampere one. It’s actually worse since a least Ampere had bad testing in its footnotes.
I’m curious, is this the norm for Arm? Are all Arm servers bogus undocumented benches?
Is it possible that a company about to have massive IPO is incompetent at understanding what SpecIntRate scores means? I didn’t think so until today but that chart’s awful.
They’ve got bogus NVIDIA comparisons to AMD.
They’ve also got Bogus benchmarks for CPU 2017
It’s hard to trust. All I know is that every time I’ve used a cloud instance with Neoverse N1 I’ve seen Arm’s benchmarks saying they’re great, but the cores are really weak unless the workload is really simple. I don’t think Arm’s CPU cores are any good and they’re just lying with NVIDIA about the perf
I’m ten scared for the next 5 years. Nvidia’s got everyone over a barrel and they’re using junk benchmark comparisons and making Arm show them off on their behalf.
Those are really bad results for Grace Superchip, they’re just using irrelevant comparison chips from AMD and Intel. You can’t tell me available today SPR HBM or Genoa-x are less mainstream than a Grace Superchip that isn’t really out.
We’re f$$$ed as an industry if these jokers are running around.
I don’t know why Arm server chips are always presented like they’re being slung by some chichi brotha selling fake Rolex and Philippe Patek out of the back of their 1997 Crown Vic.
With how much we’re all looking at Intel and AMD’s numbers, Arm and NVIDIA are like toddlers taking a PhD class.
The SPEC graphs are for 1 core on the left and for 32 cores on the right. All the details are in the slide above it. They use unoptimized GCC10, so the results are neither base or peak. One can beat these scores easily by using a newer compiler, more optimized options, special memory allocators, huge pages etc.