
Today we published William’s NVIDIA Tesla T4 AI Inferencing GPU Benchmarks and Review. While reading through the review prior to publication, I wanted to provide some thoughts and context since there is more to unpack in this one than our average GPU review. We normally put everything in our reviews, but I wanted to share some of my reflections with our readers.
At STH, we test CPUs that range from 10-15W to 225W+ and can cost under $100 to over $10000. Servers we test can cost as little as $500 and we also test 8x GPU Servers and 4x CPU servers with over $100,000 price tags. Making trade-offs between performance, power, form factor, and the price is something we see everywhere. Our Tesla T4 review struck me as something different.
NVIDIA Tesla T4 Inferencing Performance
First, let me state that NVIDIA helped us build our current inferencing tests using their containers earlier this year. When you see results like this from the review, please remember, NVIDIA had input. We requested that NVIDIA let us test the Tesla T4, but they did not facilitate the review. Independent Tesla T4 reviews are few and far between. We know another site is working on a sponsored paper and there are many sponsored case studies out there on the T4’s performance. As this is an unsanctioned review where NVIDIA had input but did not know we were doing it, we were able to broaden our comparison set which led to this:
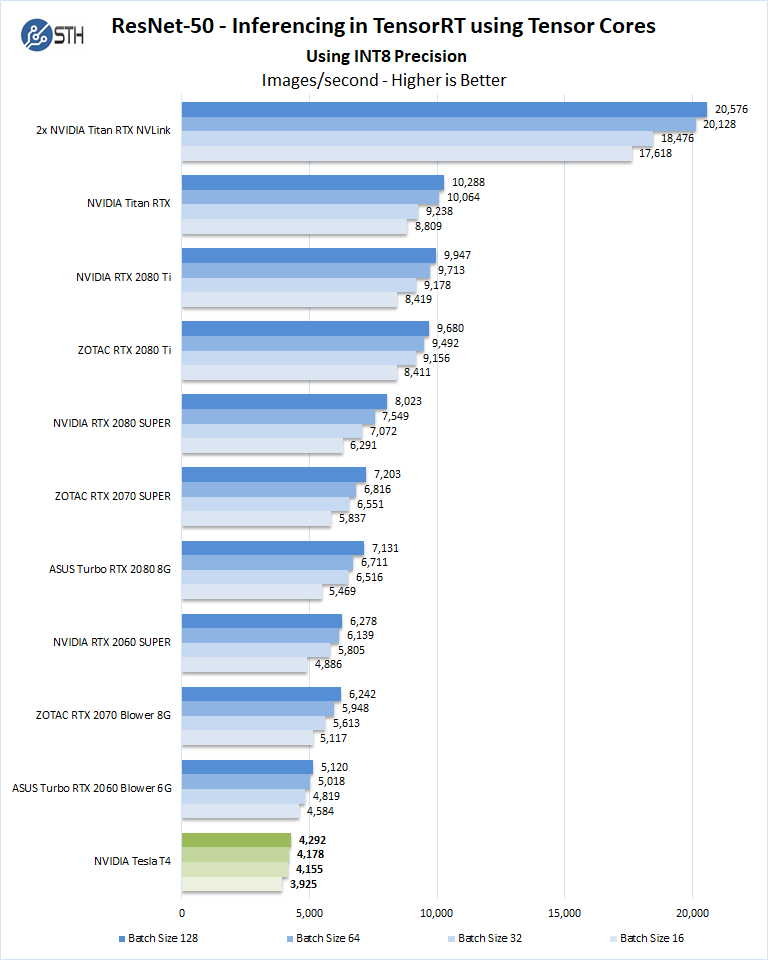
This chart, in particular, I wanted to use since INT8 inferencing is essentially the key selling workload for the NVIDIA Tesla T4. At its targeted workload, it performs below the $400 NVIDIA GeForce RTX 2060 Super. This makes sense.
In both cases, we have 2560 CUDA cores and 320 Turing Tensor cores. The NVIDIA Tesla T4 has more memory and ECC memory, but less memory bandwidth. Base clock speeds are also much lower for the Tesla T4 than the GeForce RTX 2060 Super. All of these are perfectly reasonable trade-offs to lower power consumption and maintain a compact form factor.
Moving beyond that, the Tesla T4 utilizes 16x PCIe lanes. If a server is physically limited, having more Tesla T4’s is better. If the server is electrically limited, then using larger PCIe cards is more efficient. The Tesla T4 uses less power and has a significantly better low profile single slot form factor, but it also costs $2000-$2500 in many servers. We also looked at the power consumption to see the TCO impact, not just the initial purchase price impact.
NVIDIA Tesla T4 Power Consumption TCO Benefits
Taking some data points here. We have heard some hyperscalers use $6/ watt for their TCO calculations over the lives of servers including power and cooling. In that case, here are the incremental power consumption costs at 100% load for these cards versus the Tesla T4:
- GeForce RTX 2060: $534
- GeForce RTX 2060 Super: $630
- GeForce RTX 2070 Super: $876
- GeForce RTX 2080 Super: $1056
- GeForce RTX 2080 Ti: $1152
- Titan RTX: $1284
The maximum delta at idle, using the Titan RTX, is only around $48. From a TCO basis, one of the biggest benefits is that the NVIDIA Tesla T4 uses less power and that can have significant power and cost savings over time.
The numbers above, however, assume that one is using a synthetic workload to keep the GPU using as much power as possible for the server’s lifetime. That is, unrealistic. It is probably better to assume somewhere in the range of say $48-$1284 for a Titan RTX operating costs over the Tesla T4.
Does the NVIDIA Tesla T4 Make Sense for Edge Inferencing
With our independent data, we can then go back to the question of edge inferencing with the NVIDIA Tesla T4.
There are a few clear-cut winning deployment scenarios for the Tesla T4. For lower-power applications where a single GPU is used, the Tesla T4 makes a lot of sense. There are deployment scenarios where the GeForce RTX series simply cannot play from a power and form factor perspective.

If one has, for example, a 2U server, then things get considerably hazier. In a server that has physical slots open, and needs say three GPUs, the math looks like:
- 3x Tesla T4’s = $6000 to $7500 + $0 baseline TCO power consumption
- 3x NVIDIA GeForce RTX 2060 Super = $1200 + $18 to $1890 in incremental power and cooling costs
The delta is then between $2910 (100% utilization, low price T4s)and $6282 (idle, higher price T4s.) In percentage terms, the GeForce RTX 2060 Super inferencing solution is around 50% to 84% less expensive on a TCO basis. There is a caveat here as the RTX 2060 Super solution is also faster due to higher clock speeds and more memory bandwidth.
Pivoting to the performance perspective, using three NVIDIA Titan RTX‘s which is fairly easy to power and cool in a modern 2U server, one can get about fourteen times the performance of a single NVIDIA Tesla T4. That means we have:
- 14x Tesla T4’s = $28000 to $35000 + $516 to $1032 in incremental power and cooling costs
- 3x Titan RTX’s = $7500 + $0 in baseline TCO power consumption
Here, the Titan RTX’s have more performance but also offer a 73% to 79% lower TCO than the Tesla T4’s. There is a caveat, of course. While modern 2U servers can handle 3x Titan RTXs, they cannot handle 14x Tesla T4’s. Those cards require 14x PCIe 3.0 x16 slots for a total of 224 PCIe lanes just for the cards to run at full PCIe bandwidth, or more than four Quad Intel Xeon Platinum 8276L CPUs can provide. One can use PCIe switches, but the form factor advantage goes away.
Again, at a single and perhaps up to three cards in a 1U server, the T4 will not have GeForce competition. Once one moves to a 2U form factor, it is extraordinarily more expensive. That TCO delta is plenty to offer swapping to passive GeForce coolers and add power cables for example. Those become rounding errors in the sea of TCO delta. That shows the less exciting side of this industry.
How the NVIDIA Tesla T4 Sells Well
The NVIDIA Tesla T4 is a very successful product. It sells very well even despite the above. There are a few reasons for that.
First, if you want to run CUDA in the data center, using GeForce is not acceptable via the EULA. We would note that if you are running inferencing at the edge, for example running video analytics in a supermarket, that is not running in a “data center.” Still, NVIDIA is aggressive with its server OEM partners so they will not sell GeForce in servers. There are very few instances where one can see a 50-84% TCO benefit, while also getting more performance, and OEMs do not offer the solution. This is NVIDIA’s power in the market, and that is due to its position.
Second, NVIDIA has little competition. The NVIDIA Tesla T4 does not have a direct competitor. A Tesla P4 is an older, less desirable architecture. The Tesla V100 single-slot 150W card is hard to get, expensive, and full-height. Quadro cards with graphics outputs are not performance competitive. Looking outside of the NVIDIA portfolio, our AMD Radeon RX 5700 XT and RX 5700 reviews are still awaiting a software update to be able to complete our test suite. The new Xilinx Vitis platform and the Xilinx Alveo U50 may be compelling for some in early November. Habana Labs is in good standing at Facebook and has a T4 competitor inferencing part. Still, NVIDIA CUDA is the 800lb gorilla in the industry and moving off it makes life difficult.
Having CUDA as a powerful lock-in mechanism, low direct competition inside NVIDIA’s data center portfolio and externally, and putting pressure on OEMs means that Tesla T4’s sell well in a market where NVIDIA has another solution that offers more performance at a massive TCO discount.
Final Words and the Future
We know that there are now AI startups with silicon such as Graphcore and Habana Labs. Intel has the NNP-I 1000, is adding DL Boost to its entire CPU range, and has FPGAs as well as future GPUs attacking the Tesla T4 market. Xilinx announced its competitor based on UltraScale+ with a Versal AI part coming. AMD may eventually decide to get serious in the segment as well. Competitors clearly see how NVIDIA is using CUDA to maintain high margins in this segment. Customers we talk to are happy for the ease of use of NVIDIA’s ecosystem but are aware of the high pricing. OEMs and hyper-scalers we speak to cite NVIDIA’s pricing as difficult for their business.
If you look at the CPU side for an analogy, the market is essentially where Intel found itself this year. If the AI inferencing side gets its version of the AMD EPYC 7002 series and NVIDIA continues with its current segmentation strategy, this is a market showing the telltale signs of being ready for disruption.



{kind=link}
This is why STH is the best. I’ve never seen a major tech site cover this. Not even the “analysts” paid by Nvidia. It’s a pretty balanced look but it’s also damning.
The Patrick is tough but fair. It’s how I remember my father.
I’ve never seen a TCO on this v GeForce. We buy T4s because that’s all we are offered. I didn’t even know GeForce was OK for inference.
Stellar analyses. I’ve never seen anyone talk about this before.
Shhhh don’t tell anyone the secret STH
NVIDIA is as usual milking like crazy ignorance of enterprises. how they can sell for so high a card that peform less than a 500$ card? people should wake up and break this stupid lock-in… since years.
hopping that the upcoming competition will crush that attitude, as has done AMD to Intel.
14x Tesla T4 are similar in performance to 6 (not 3 ! ) Titan RTX.
And there are 2u servers that can hold either set.
Well, lot of people here in the comment seems to forgot the difference in VRAM. It doesn’t warrant 2000$ difference but it’s still a huge gain when training or even inference.
if you use tensorflow serving for example you can load multiple models on the cards, that’s where having more VRAM is interesting even for inference
Any comparisons for VDI rather than inference?
T4’s really are for VDI. High memory to Cuda ratio lets you put 16 1GB vGPU profiles with a 160 core slice. That gives an experience similar to an Intel iGPU. That’s the reason so many are sold.