A(rm) strategic choice: Custom vs off the shelf CPU cores
Looking at current offerings, we can see a key strategic decision that is driving development on hardware while impacting the software ecosystem as well. One of the biggest differences between the Ampere Altra and the Marvell ThunderX3 is their CPU core strategy. Ampere, like Amazon, decided to play it safe and fast and opted for largely off the shelf Arm-designed N1 cores.
The decision to use N1 cores also greatly simplifies software support. Two major open-source compilers, GCC and LLVM, have already built-in support for the Arm N1 (GCC v9 and LLVM v10.) For example, Ubuntu 20.04 ships by default with GCC 9.3, and the default LLVM version it proposes is v10). Marvell, for its part, is not far behind with either GCC or LLVM but has had to spend some internal resources to have these compilers properly optimized for its CPU, instead of benefitting largely from the Neoverse ecosystem.

The off the shelf strategy has another big advantage, it reduces overall risks and lowers time to market. Not only do the CPU cores require less design, but their actual implementation on TSMC’s 7nm node is simplified as well. (See our coverage of the Neoverse N1 System Development Platform for more details.) That constitutes an enormous amount of work already done by Arm, TSMC and the broader semiconductor manufacturing ecosystem. This is work that Ampere and AWS did not have to go through by themselves. Marvell, meanwhile, went for a much harder road.
Of course, each strategy has its own advantages: as each N1 core supports only one thread, Ampere can tout “predictable” per-core performance for all workloads, as there is not a second thread per core eventually fighting the first thread for the CPU core’s resources. This avoids the “noisy neighbor” effect and its negative impact on performance. It also means that other methods need to be employed in order to keep the execution pipelines filled.

In the context of Cloud Service Providers (CSPs), having only one thread per core mitigates security risks associated with having two different threads sharing one core’s resources. An example is the Foreshadow vulnerability unveiled in 2018, while limited to some Intel processors, offers a good example of the theoretical security risks associated with having two threads (potentially running two different workloads) sharing one core’s resources.
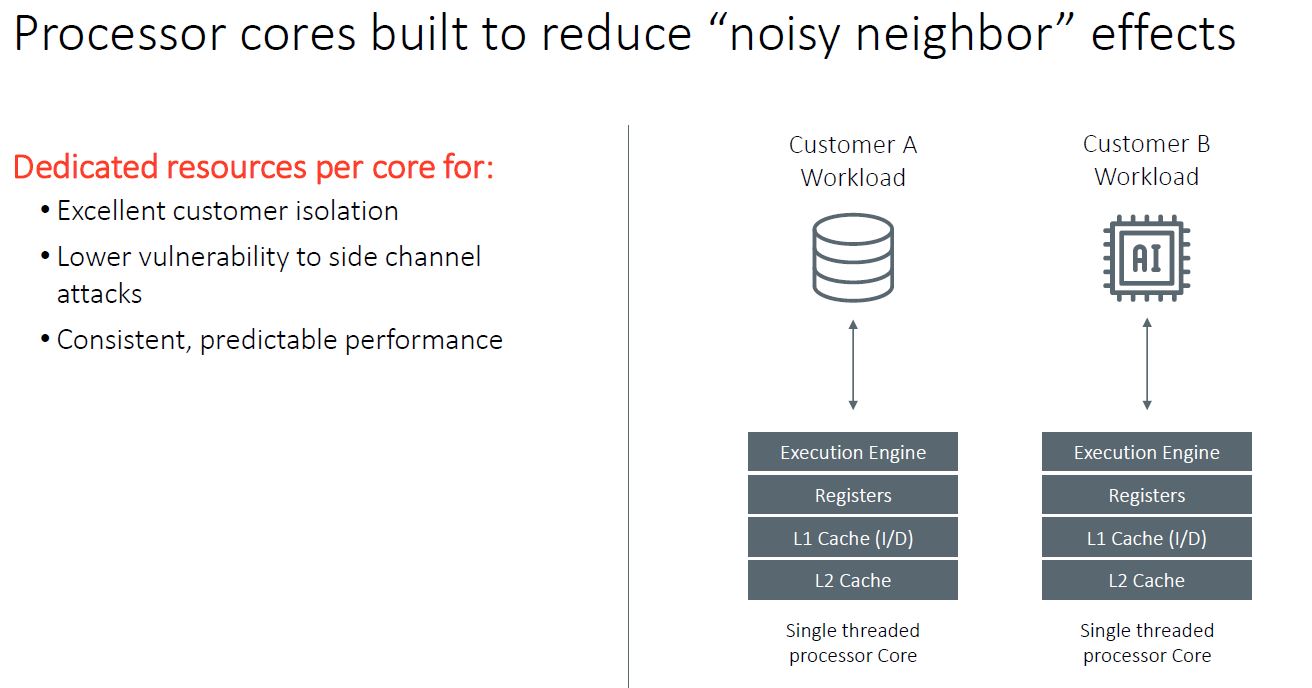
Marvell, for its part, can also tout some distinct advantages of its custom cores, capable of 4-way SMT. Namely: greatly increased performance for some highly parallel workloads. One must remember that a big part of Intel’s success years ago was offering SMT in the form of Hyper-Threading. This SMT=2 approach offered higher thread counts and performance at lower power levels than adding additional cores. In the era of 1-4 core CPUs, SMT was a game-changer and it is employed by many higher-end architectures.
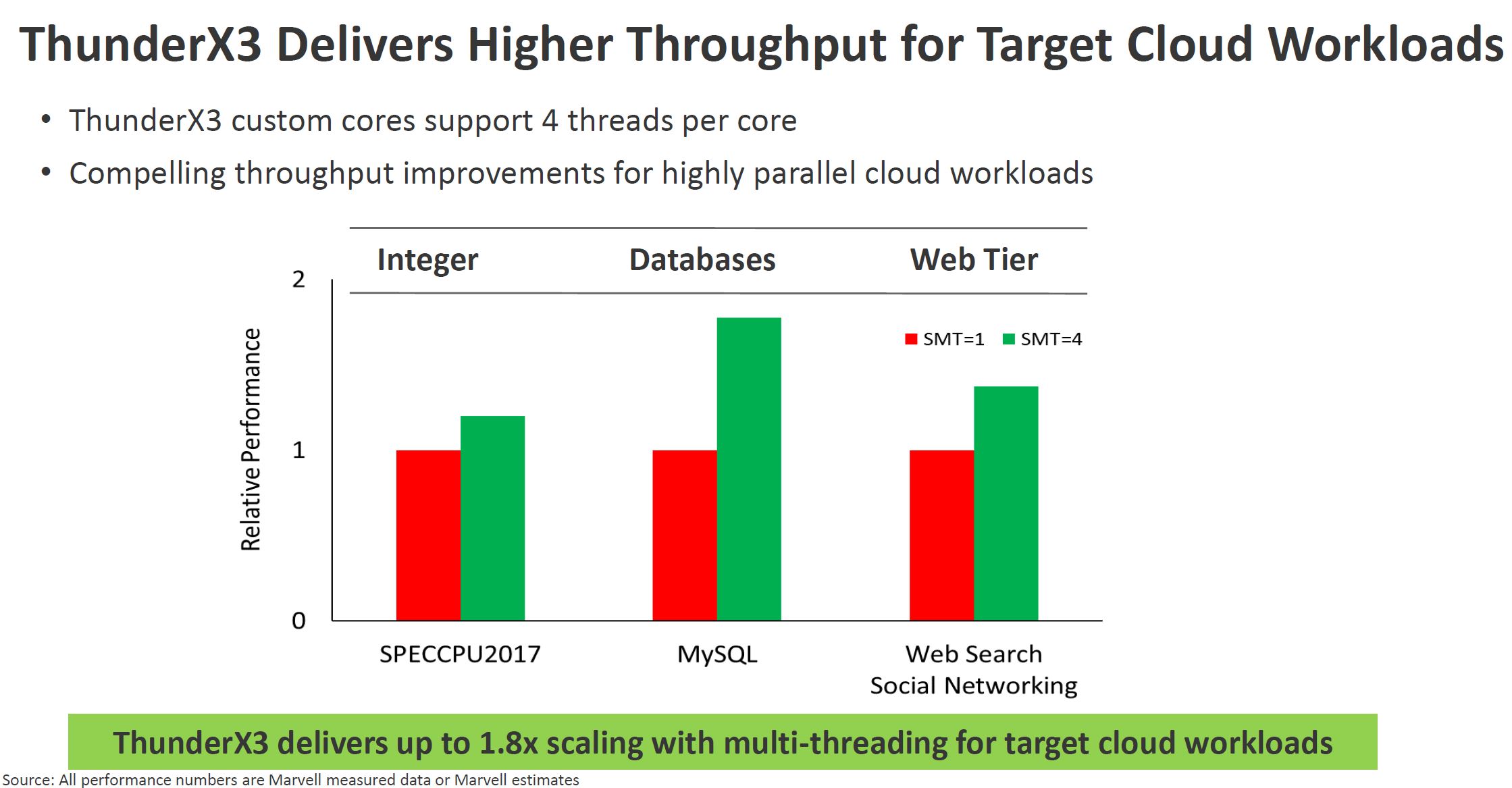
What Marvell also gains, aside from performance, is market differentiation. There is little stopping a large company or even a well-funded startup from launching a Neoverse based solution, but designing custom cores is harder which can be the foundation for competitive advantage. For AWS and large CSPs, they have a captive customer (their infrastructure division) and relatively captive second-order customers (cloud service customers.)
Marvell’s Custom Path
The question of custom v. off the self cores may not be settled yet, but the off the self strategy is certainly all about reducing risks and lowering time to market. The custom cores strategy can only pay off if one is able to execute well enough and fast enough, all the while offering an obvious price or performance advantage. It necessitates a lot more resources, but if the differentiation is a win with customers, the payoff can potentially be big. We will also note here that the cores are only part of the overall server chip solution, but using a reference design removes a large engineering effort from chip design teams.

Outside the server realm, in the world of mobile phone SoCs, Apple and Samsung offer a cautionary tale for Marvell. Apple is now famous for offering top-notch single-thread performance and overall power efficiency with its custom-designed Arm cores intended for use in smartphones and tablets (and soon to be scaled up for laptops and desktops, and presumably also for workstations, by Apple’s very own CPU design teams.) Even Arm’s recently announced Cortex X1, which threw away the PPA (Power/Performance/Area, more on that further below) mantra to achieve even more performance, and which is yet to make an appearance in an actual product, almost certainly will not be enough to beat Apple’s currently available A13, let alone the A14 that will be shipping before this year ends. Apple currently reigns supreme in the world of custom Armv8 cores, beating even Arm’s own offerings. It certainly has the means to do chip design well.
Samsung, for its part, tried and failed to imitate Apple. In November of last year, it announced that it had given up on its custom line of Mongoose CPU cores. At ISCA 2020, it revealed that all along the six years of developing six successive generations of custom Armv8 cores, Samsung had been using the same RTL blueprint, simply iterating on it instead of sometimes starting from scratch for the whole design. Thanks to Andrei Frumusanu’s excellent coverage of this matter, we now know the following: at this conference, it was explicitly stated that the main difficulty facing the design team was a lack of resources to redesign some blocks from the ground up. In other words, Samsung failed at least partly because it never gave itself the means to be successful. The lesson here is that to design a custom Arm core that is clearly better than Arm’s own offerings, a company needs resources.
Arm SVE and a customized #1 spot in the Top500
Beyond the debate around custom general-purpose cores, the Arm server ecosystem is as credible as ever. Reinforcing this credibility is the new system taking the #1 spot in the Top500 June 2020 list. The Fugaku supercomputer, an Armv8 based design built by Fujitsu is now the world’s fastest supercomputer. While many focus on this being the fastest (public) supercomputer, it also means that x86 and Arm no longer occupy the top 4 spots. This is set to change next year, but it is something important to remember.
Unlike many recent entries in the Top500, Fugaku is not GPU-accelerated. Instead, it is based on the A64FX, also designed by Fujitsu. As this chip is for now clearly outside the realm of CSPs and built for HPC and nothing else, we will skip the details and simply note that the A64FX can be thought of as a hybrid between a CPU and a GPU. It has 48 Armv8 cores like a CPU, but it has the typical memory subsystem of a high-end GPU (namely, a 4096-bit HBM2 memory bus.) Also like a GPU, it excels at highly parallel calculations, thanks in part to the use of Arm Scalable Vector Extensions (SVE.)

These SIMD extensions can be thought of as similar in some ways to Intel’s AVX: they are extensions to the instruction set, and implementing them in silicon is somehow akin to building a small accelerator engine inside the CPU core itself. Arm SVE is remarkable in that it is flexible in the choice of vector length: from 128 bits to 2048 bits. Note that Intel AVX tops out at 512 bits currently and that Fujitsu also opted for a 512 bits length SVE implementation in the A64FX.
The Armv8 architecture has more than just the integer toolset to compete with x86, and Arm SVE – as an optional, high performance, variable bit-length SIMD implementation – has been a solid basis for SVE2 and its merging with NEON. In the future, that may allow Arm to improve high bit length SIMD support in its standard Cortex A, Cortex X, and Neoverse N CPU lines. And in any case, Fujitsu used Arm SVE to build a blend between a CPU and GPU, and a very successful one at that, claiming – for now – the #1 spot in the Top500 list.
Today the Arm processors for HPC and the cloud are different. Intel is currently designing Xeon to cater to both markets, one floating-point heavy and one integer heavy. The question is whether Arm needs to directly challenge this versatility, or if they can succeed in building highly specialized parts. With the Arm model, perhaps the market is large enough. We are already seeing Arm dominate categories such as the SmartNIC and computational storage that are taking classic main-socket CPU compute functions and moving the work onto Arm-based accelerators.
Next, we are going to look at what is driving companies to use the off-the-shelf solutions, and design their own around Arm, and what it means for the ecosystem.
When PPA meets TCO
Perhaps the biggest question is “why?” Why would a CSP want to change from x86 to Arm? There was a time when Intel had an effective monopoly on the mainstream server market. With AMD’s re-emergence as not just a credible threat, but as a performance leader, the question becomes why is there a need to go through the switching effort at all.
To answer that question, two notions here are key: PPA and TCO. PPA stands for Power/Performance/Area, and is a somewhat vague metric to measure the efficiency of a CPU design in two ways: by estimating its power efficiency (the performance/power ratio), and by estimating its ‘transistor efficiency’ (the performance/area ratio.) The idea for the latter is to avoid comparing apples and oranges. Thus, the performance/area ratio is to be used to compare designs using the same transistor density (so basically on the same manufacturing node.) This way, we are only comparing the merits of two different designs, not the merits of two different manufacturing nodes.
So the performance/area ratio helps understand how many transistors are needed to reach a given level of performance. Since we are treating transistor density as a constant, this is just another way of asking how big does a chip has to be. Bigger often means more expensive to manufacture, so this is focused on the cost side of the equation. Since a CPU requires electricity to run, the performance/power ratio helps understand the operational costs of running a processor. PPA is the addition of these two different notions and seen in this light, it looks a lot like the basis for TCO. CSPs focus on TCO when they choose the hardware that will run their customers’ workloads, along with the value hardware can deliver.
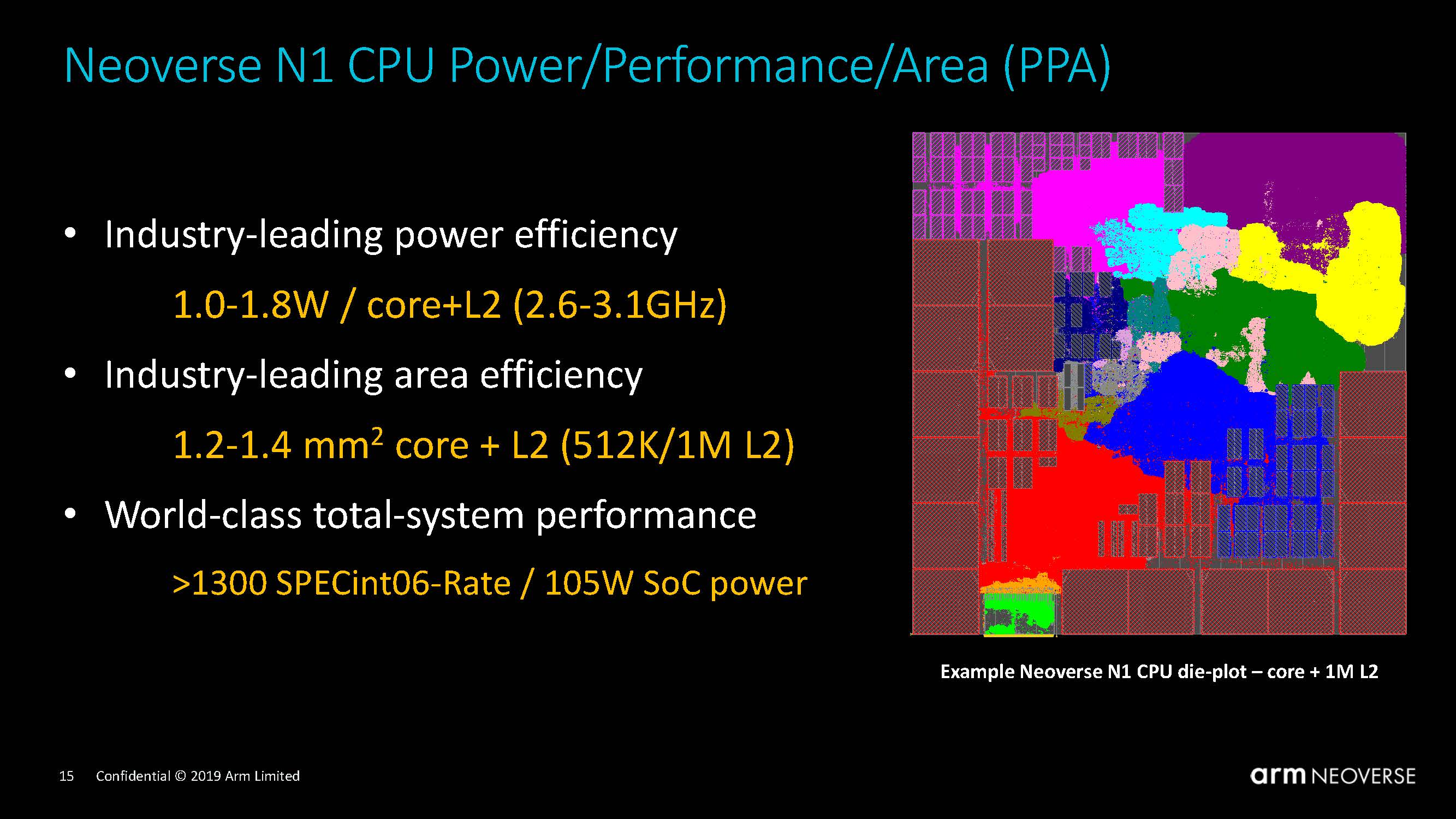
In the world of CPU design, Arm is well-known for excellent PPA. Its CPU designs are both power-efficient (the performance/power ratio) and ‘transistor efficient’ (the performance/area ratio.) This is one of the reasons why Arm has historically been the architecture of choice for smartphones and tablets. Even though it is now clearly entering server territory, Arm has been able to maintain its focus – and its leadership – on the PPA metric, and its latest client-side offering, the Cortex A78, is a perfect example of this relentless focus.
By Arm’s own account, the Neoverse N1 is based on the Cortex A76, with a modified un-core (the un-core comprises, grossly speaking, the mesh linking all the cores together and the memory subsystem. It is of paramount importance in a server CPU, but clearly much less relevant in a mobile phone SoC.) It makes sense to expect Arm to continue on this streak and announce sooner or later a successor to the N1.
The importance of TSMC’s manufacturing roadmap
What is more, one must not underestimate the paramount importance of TSMC’s manufacturing roadmap for the whole fabless industry, and that now includes AMD. Looking at the slides, the roadmaps of Arm and AMD look a lot like they have completely internalized TSMC’s manufacturing roadmap, and this is not by accident.
If ever many big Cloud Service Providers do indeed switch to a much higher mix of Armv8 metal in their vast hardware fleets, it will take time, and it will be a slow process. In this hypothetical future, the advent of TSMC’s 5nm manufacturing node may mark an important inflection point in the 2022-2023 time frame.

Intel’s manufacturing delays have negated a major competitive advantage. Years ago when Intel and x86 last faced a threat from Arm chips and when we saw companies such as Calxeda fail and Applied Micro (after a few business sales this is now Ampere) falter, Intel had a manufacturing process edge. That is no longer the case so Arm server options (and AMD) are able to benefit from more efficient architectures.
For a cloud service provider, they have access to capital, off-the-shelf cores as well as custom-designed cores from third parties, leading process technology, improved software support, and a captive customer base. In an environment where a lot needs to go right, this is a lot going in the Arm ecosystem’s direction.
Final Words
Ultimately, there will be a place for both Arm and x86 in the CSPs’ hardware fleets. For some workloads, it will be for compatibility reasons, and for others, it will simply be for the sheer high performance offered by some x86 hardware options. This leads us to the following question: Will the two x86 players, Intel and AMD, let Arm keep its PPA crown and focus instead on high performance at a higher relative cost? AMD seems to have de-emphasized its low power/low-performance line of cores (called Jaguar, and found in the current generation of consoles from Sony and Microsoft) to focus on its GPUs and its high-performance Zen CPU cores. This focus has certainly lead to great results for AMD. AMD also had originally planned an Arm processor to go in its EPYC platform, although that project was scrapped as it focused on x86 and Zen.
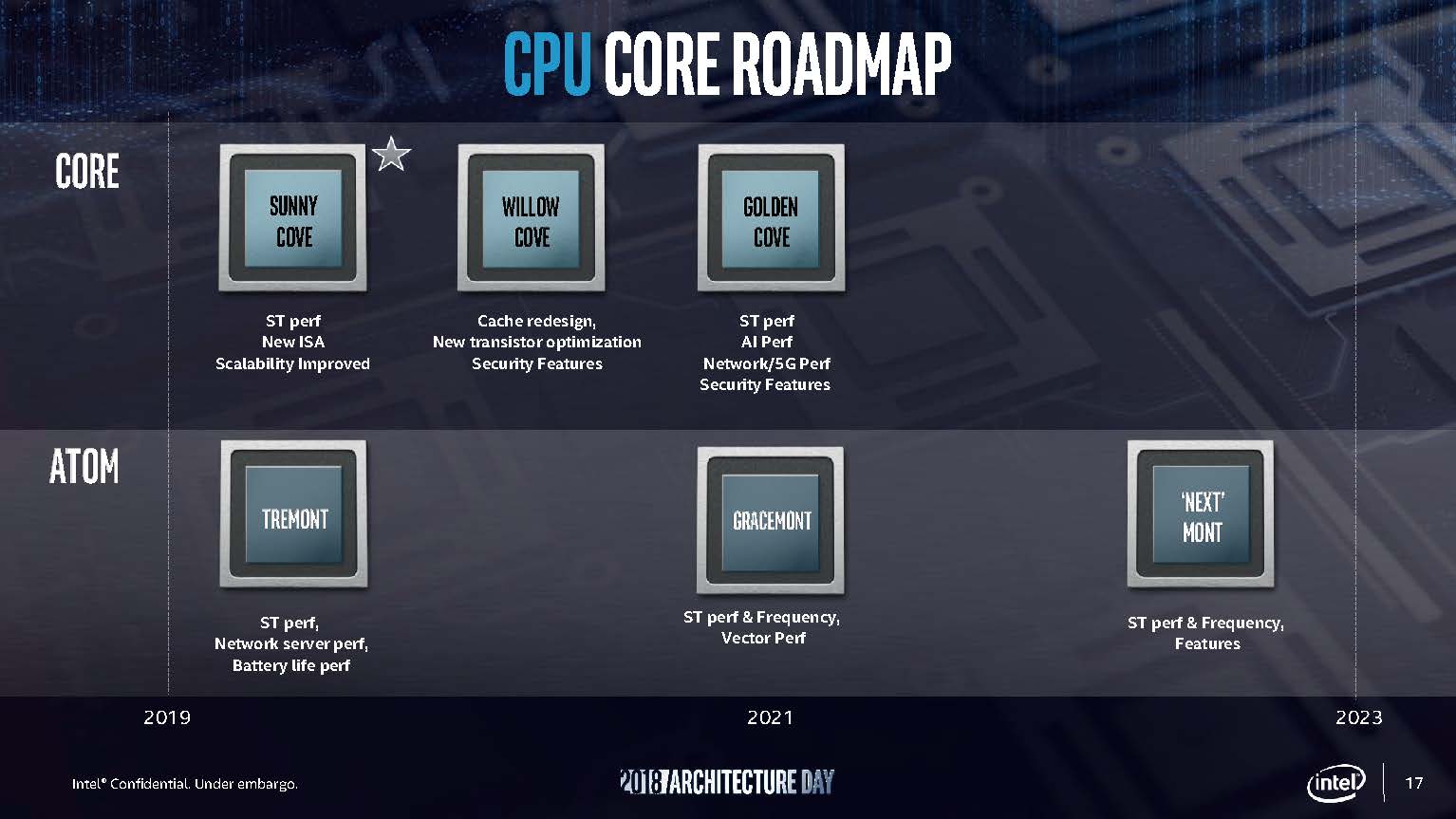
Intel, for its part, remains committed to among other things – both its line of low power Atom cores and its line of high-performance cores. In the past used its Atom line to, quite successfully, counter Arm’s advances in the microserver and embedded markets. With the Atom C2000 and C3000 lines, Intel was able to launch competitive offerings and use its manufacturing and financial advantage to take the market from upstart Arm players at the lower-end. Now, Arm is moving into the higher performance space.
With this generation, the Arm players, as well as AMD are preying on weaker innovation cycles on the data center market from Intel-based largely on 10nm, and now 7nm Intel process delays. The competitors are not just smaller semiconductor companies and startups. Instead, Arm is building a portfolio of silicon providers who do not have x86 cores such as Marvell, NXP, and NVIDIA. There is a startup ecosystem with Ampere, Nuvia, several others. Now, unlike in 2013, it is not just third party providers that are trying to compete with Intel. Even Intel’s well-funded customers such as Amazon and Google are turning to foundries to introduce their own Arm server chips.
The opportunity for Arm in the data center has become real. The software side has matured. Building competitive hardware is getting easier. There are now significant customers for Arm servers. Arm is already eating function-by-function into the server through the accelerator supply chains. We are now asking when does the change start manifesting in a reasonable market shift.



{kind=link}
And then comes RISC-V. Or venerable POWER. Both open architectures now.
I believe that when ARM/POWER/whichever else architecture releases true PC class machines for developers to use, then x86 will clearly see the most major threat that it has ever encountered. At the moment, real developer machines for these kind of architectures either do not exist or are hard (or very expensive) to buy. Raspberry Pi – style of computing can go only this far. But two major things are coming, the first from Apple and the second from AWS or other cloud providers. For the former, I am not really sure how big the impact will be because of the quite closed nature of said machines – however if Linux can be loaded to an ARM-based Macbook or Mac Pro then it is going to be a very serious step forward. For the latter, I believe that it is a half-step, however an important one as it creates a market demand for ARM-software solutions and provides incentives to developers.
@Andreas
Yeah, Apple going ARM isn’t going to move the needle much since MacOS doesn’t really show up in the datacenter, and Linux doesn’t support Apple hardware very well.
I agree, desktop ARM boards are an important evolutionary step. x86 and Linux snuck into the datacenter via cheap, good enough desktop boards. Operations folks got comfortable running x86 Linux servers for their own personal stuff.
It still remains to be seen if ARM will create a solid, modular platform like x86.
X86 is x86 is x86. The x86 ecosystem is all fairly symmetric, and x86 is built for horizontal integration.
The ARM ecosystem on the other hand has been an asymmetric mess, which is kind of it’s strength, and the ARM ISA is designed for vertical integration.
If the ARM vendors can’t deliver an x86 like experience, the ARM platform is only viable for customers willing to burn money on vendor locked hardware, or CSPs like Amazon, Microsoft, or Google who have custom technology stacks they rent to people.
KarelG
RISC V is a novelty – that’s all and no one outside of an already IBM shop will even consider POWER.
World will be X86_64 for the foreseeable future – ARM will remain niche.
Perhaps the shift to ARM with MacBooks helps, if enough developers use them. I think it will be a major problem for developers when for example their containers stop working or just run awful slow due to emulation.
Without a good ARM laptop running Linux (or Windows even), I think ARM is facing an uphill battle.
In the early ’80s, PC was a novelty (touted by DEC, Wang, IBM themselves). In the early ’90s, Linux was just a hobby (according to Linus himself). At the turn of the century, Amazon and cloud computing were novelties and social media was a novelty for teenagers to have a little fun. I wonder if RISC V a novelty, then would it repeat a similar history?