
It is time for the piece many have been waiting for, the Ampere AmpereOne A192-32X review. In this review, we are going to go into the performance, power consumption, and perhaps most importantly, what it is like using platforms like the Supermicro MegaDC ARS-211M-NR and what it means for the industry. We have a lot here, so let us get to it.
Ampere AmpereOne A192-32X Overview
The AmpereOne A192-32X is important to keep in context. It is a 192-core 3.2GHz (hence A192-32X) part, which seems mundane by 2024 standards. Allegedly, it was first sold in 2022-2023, mainly on the Oracle Cloud. That initial volume going to cloud providers means that it took quite some time to get into the hands of other customers. In 2024, that has changed, and now we have servers like the Supermicro MegaDC ARS-211M-NR.

That may not seem like a big deal, but it is the difference between AmpereOne hitting the enterprise market with 192 cores when that was a lot versus today when Intel is at 144 E cores at 250W and next quarter and 128 P-cores (256 threads) in Q3 2024. AMD, for its part in early Q4, is now at 192 cores/ 384 threads per socket. Or let us put it this way. In 2022-2023, a 192 core Arm CPU was otherworldly. In 2024, the x86 crew has largely caught up.
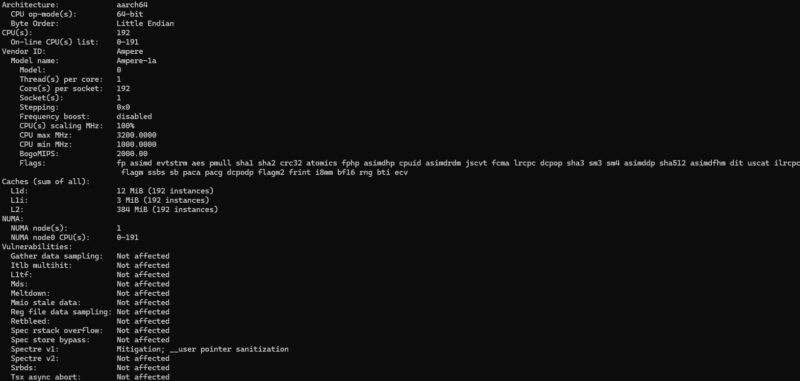 AmpereOne A192 32X Lscpu Output
AmpereOne A192 32X Lscpu Output
Ampere is focused on providing a chip that can be partitioned via containers or VMs for multiple customers at once. For all of its performance claims, let us get real for a moment. Ampere is not trying to build a HPC CPU. This is a cloud-native chip.

One area in which Ampere moved up the stack with AmpereOne is pricing. AmpereOne pricing is higher than Altra Max but with more performance. Still, Intel, AMD, and NVIDIA do not consider a $10K list price for their chips a ceiling in any way.
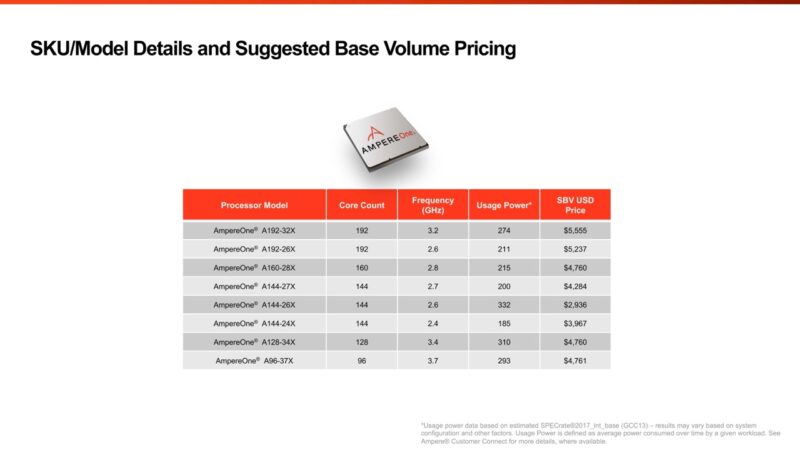
The other big one between AmpereOne and Altra Max is that the feature set saw a huge revision. This is the original 2022 slide, the A192-32X is a 400W part. Still, things like nested virtualization are new with AmpereOne. We also get PCIe Gen5 and DDR5 support.
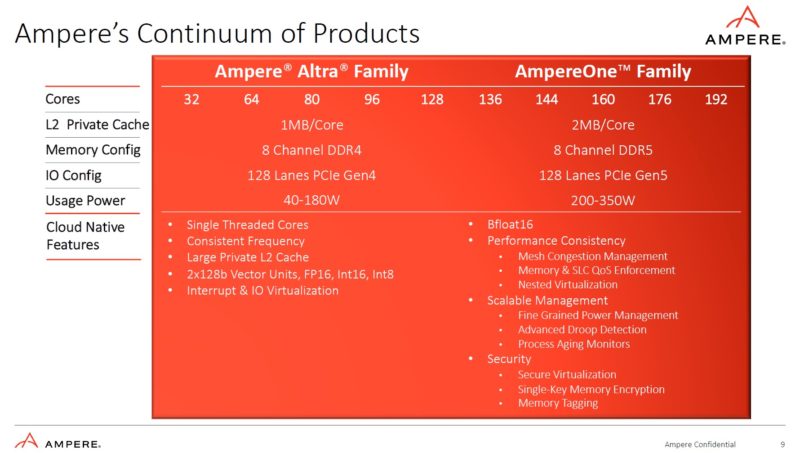
We went into more details during the Ampere AmpereOne Architecture at Hot Chips 2024 but Ampere also changed how it is making chips. The center chip that you see has the cores and caches on TSMC 5nm. Around that main chip are smaller chips that handle PCIe and DDR5 connectivity. Eventually, with AmpereOne M, Ampere will add two more DDR5 chips and get to 12 channel DDR5 matching AMD and Intel. For now, we are looking at the 8-channel DDR5 machine.
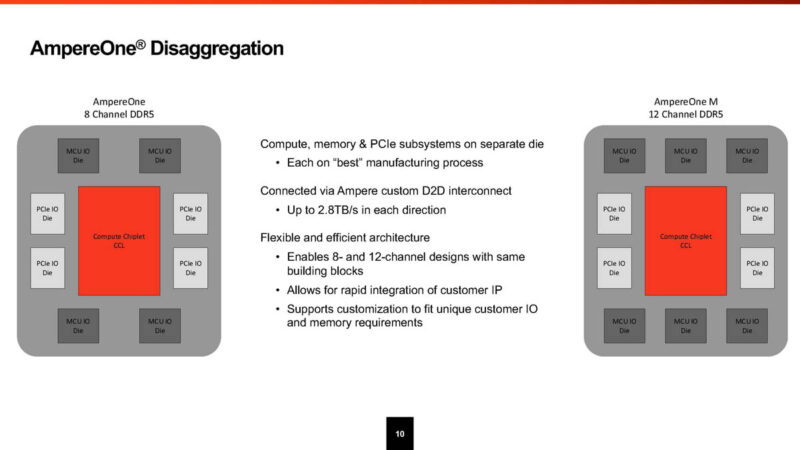
Some of the other impacts of the cloud-native design are when it comes to cores and caches. The center compute tile is a sea of 192 cores in 24 8-core clusters. Each core gets its own 2MB L2 cache and does not utilize SMT. So one core is one thread. For an organization worried about a future Spectre/ Meltdown vulnerability, one core/ one thread protects against that. It is telling that Intel and NVIDIA have taken this approach as well.
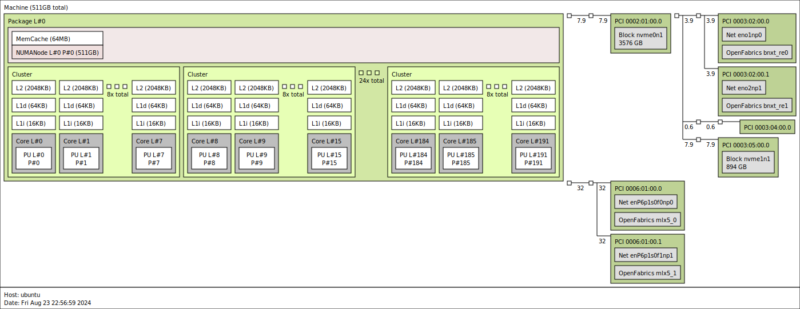
Something very different with this chip versus an Intel Xeon 6 Granite Rapids-AP (or even Sapphire Rapids/ Emerald Rapids) or an AMD EPYC 9005 “Turin” is that there is a tiny shared L3 cache at 64MB. That is much smaller than even the 144-core Intel Xeon 6700E and minuscule compared to AMD’s L3 caches. Again, this is designed to be partitioned off and sold to multiple customers, so having a large shared L3 cache conceptually can be challenging in that model. Plus, a large L3 cache takes up a lot of die area.
Still, one benefit of this approach is that the core-to-core latency can be better than Intel and AMD because there is a single compute tile.

Next, let us get to the performance.



{kind=link}
How significant do you think the 8 vs. 12 channel memory controller will be for the target audience?
Lots of vCPUs for cloud-scale virtualization is all well and good as long as you aren’t ending up limited by running out of RAM before you run out of vCPUs or needing to offer really awkward ‘salvage’ configs that either give people more vCPUs than they actually need because you’ve still got more to allocate after you’ve run out of RAM or compute-only VMs with barely any RAM and whatever extra cores you have on hand; or just paying a premium for the densest DIMMs going.
Is actual customer demand in terms of VM configuration/best per-GB DIMM pricing reasonably well aligned for 192 core/8 channel; or is this a case where potentially a lot of otherwise interested customers are going to go with Intel or AMD for many-cores parts just because their memory controllers are bigger?
You’ve gotta love the STH review. It’s very fair and balanced taking into account real market forces. I’m so sick of consumer sites just saying moar cores fast brrr brrr. Thank you STH team for knowing it isn’t just about core counts.
I’m curious what real pricing is on AMD and Intel now. I don’t think their published lists are useful
We might finally pick up an Arm server with one of these. You’re right they’re much cheaper than a $50K GH200 to get into.
“We are using the official results here so that means optimized compilers. Ampere would suggest using all gcc and shows its numbers for de-rating AMD and Intel to gcc figures for this benchmark. That discussion is like debating religion.”
Question to ask is “Do any real server chip customers actually use AOCC or ICC compilers for production software?”
Also, to use CUDA in the argument is suspect, IMO, given it’s GPU, not CPU, centric optimizations.
It’s a great review.
JayBEE I don’t see it that way. It’s like you’ve got a race with rules. They’re showing the results based on the race and the rules of the race.
I’d argue it hurts Ampere and other ARM CPUs that they’re constantly having to say well we’re going to use not official numbers and handicap our competition. It’s like listening to sniveling reasons why they can’t compete according to race rules. I’d rather just see them say this is what we’ve got. This whole message of we can’t use ICC or AOCC just makes customers also think if they can’t use ICC or AOCC what else can’t these chips do? I can’t just spin up my x86 VM’s as is to ARM, forget any hope of live migration. Arm’s marketing message just falls flat because it’s re-enforcing what they can’t do. For the cloud providers that own software stacks they don’t care. It’s also why the HPE RL300 G11 failed so hard they don’t have AmpereOne.
That’s something I think STH could have harped on more. If you’re migrating x86 instances, even if it isn’t a live migration, it is turn off, then on to go between AMD and Intel. You’re rebuilding for ARM. Even if the software works great, there’s extra steps.
I can tell you that my company does not use specialized compilers, namely AOCC or ICC, when evaluating AMD, Intel, and Ampere products. We want as best “apples to apples” comparisons as possible when evaluating performance across different server offerings. Results generated by special compilers, compilers my company will never use, are of no interest to our performance evaluations.
And let’s not forget that some of the specialty compiler optimizations were deemed invalid by SPEC.
https://www.servethehome.com/impact-of-intel-compiler-optimizations-on-spec-cpu2017-example-hpe-dell/
I don’t think most enterprises run their own apples to apples on this kind of thing. How do they know they’ve tuned properly for each? The server vendor tells them? In this case, that isn’t Dell Lenovo or HPE. That’s why most orgs just have the SPEC CPU2017 in their RFP’s.
SJones that was 3 generations ago, and stopped being relevant with emerald, right? It’s only Intel not AMD too, right?
xander1977
SPEC ruled an AOCC and ICC optimization for 505.mcf_r as a violation, but there had been so many scores already published with it, they withdrew it. Can’t find the link at the moment. This was an optimization that GCC did not implement. With 505.mcf_r being one of the lower resulting tests, this huge improvement from the optimization had a large impact on the overall SIR score since the overall is the geomean of the 10 individual tests.
While “apples to apples” is difficult to achieve, a critical part of that work for us is in fact using common GCC versions across architectures. This also helps us identify areas of potential code/compiler improvements to pursue.
JayBEE asked “Do any real server chip customers actually use AOCC or ICC compilers for production software?”
From my perspective the kind of customers who run the kind of software focused on by SPEC CPU are likely to employ experts whose main job is helping others tune the compiler and application to the hardware. If you are not that customer, then making a hardware decision based on SPEC is similar to choosing the family car based on the success of a racing team sponsored by the same manufacturer.
On the other hand Intel had been donating much of their proprietary compiler technology to GCC and LLVM. The result allows Intel to focus on x86 performance optimisations while language standards and conformance are handled by others. Something similar needs to happen for ARM and I suspect it does.