AMD Ryzen Threadripper 3970X AIDA64 CPU Benchmarks
Benchmark pages of AIDA64 Extreme provide several methods to measure system performance. These benchmarks are synthetic, so their results show only the theoretical (maximum) performance of the system.
CPU and FPU benchmarks of AIDA64 Extreme are built on the multi-threaded AIDA64 Benchmark Engine that supports up to 1280 simultaneous processing threads. It also supports multi-processor, multi-core and SMT (Hyper-Threading) enabled systems. More information about these benchmarks can be found here.
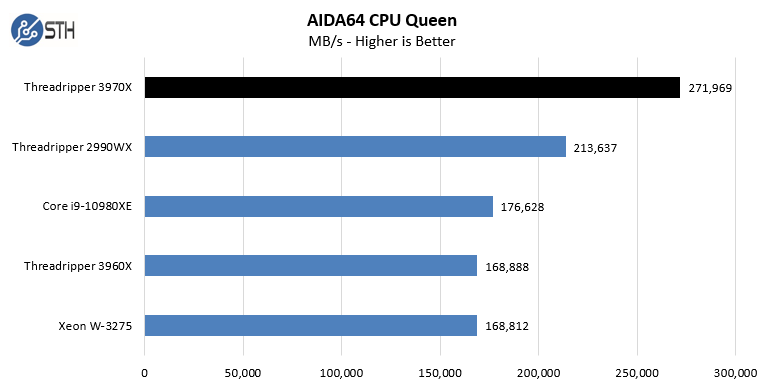
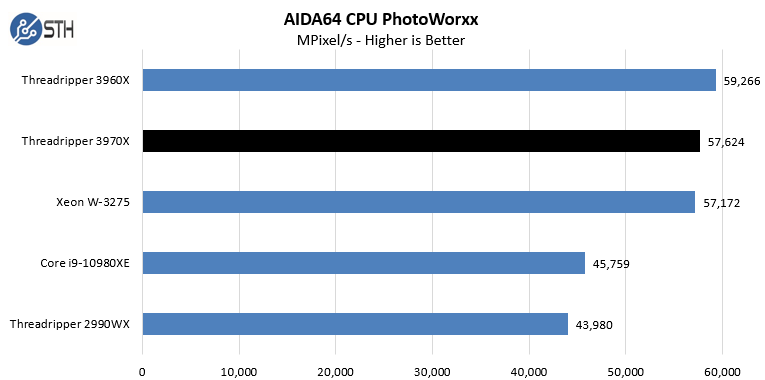
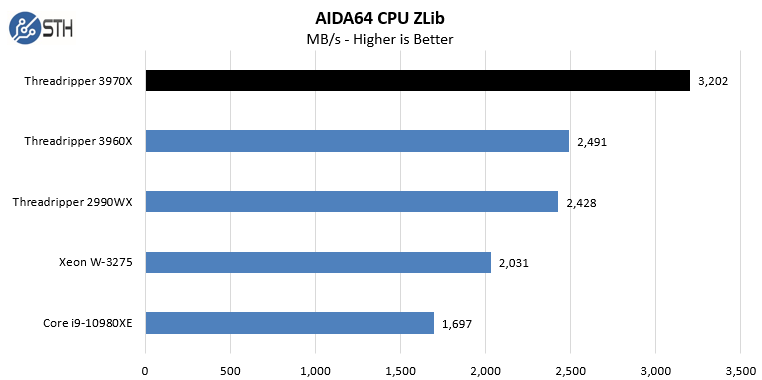
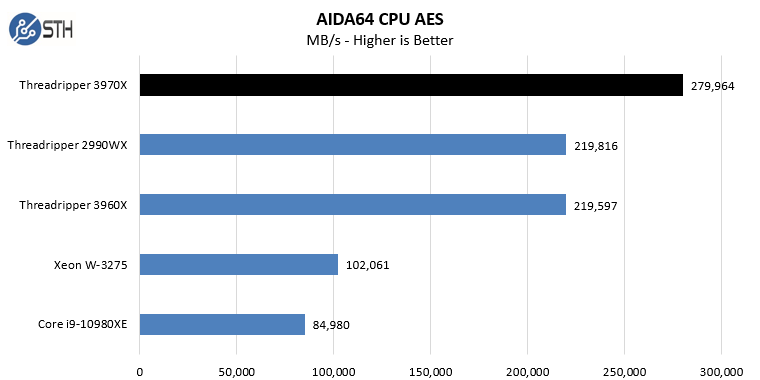
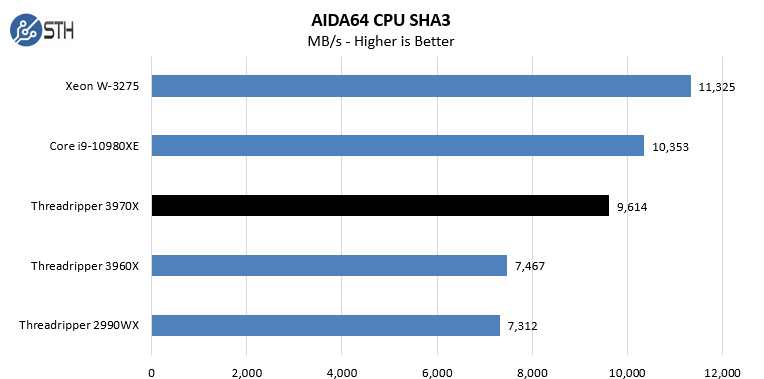
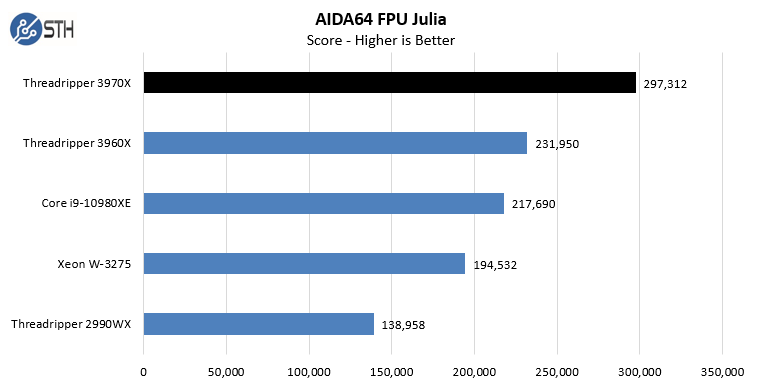
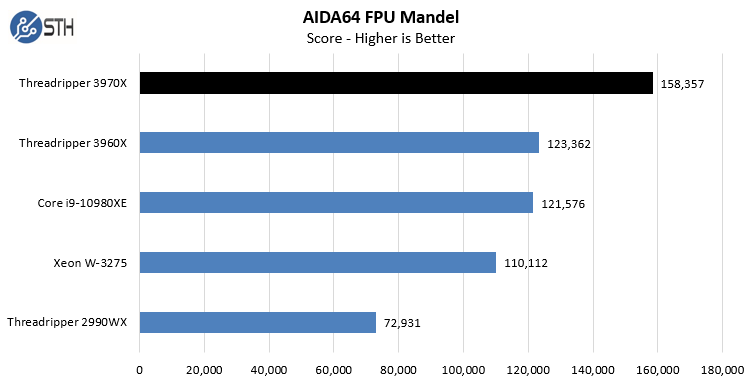
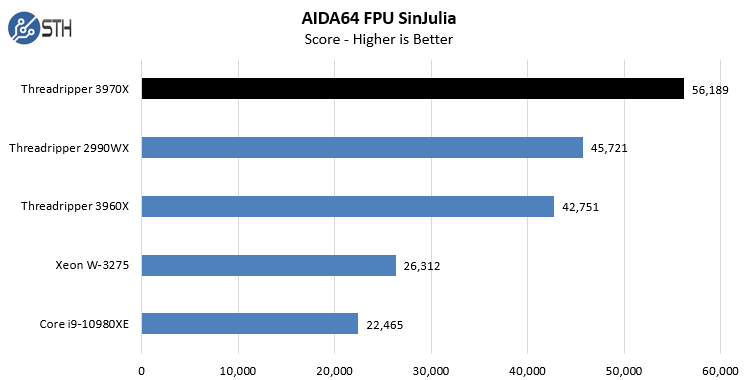
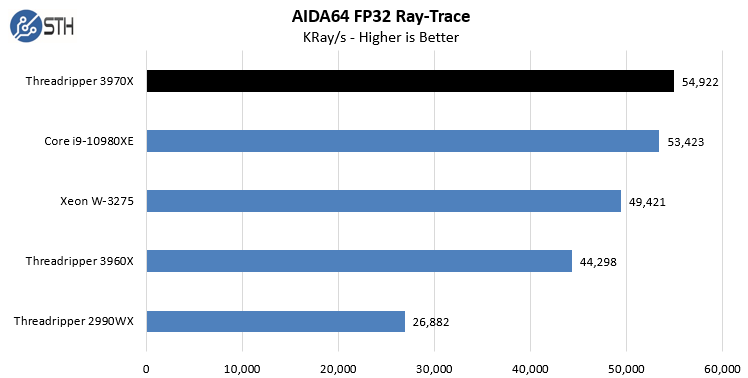
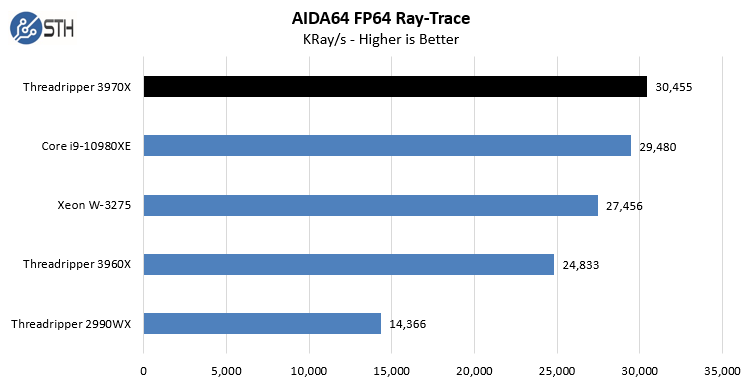
In the SHA3 test, we see Intel CPUs, particularly the Intel Xeon W-3275 perform extremely well. Otherwise, the AMD Ryzen Threadripper 3970X performs at or near the top of every chart. While we did not do the longest and most exhaustive test suite on the new Threadripper in Windows, we wanted to at least get some sense of performance. We also wanted to calibrate what we were seeing in Linux with what we saw in Windows. With the previous generation, the Windows scheduler had a harder time with the 2990WX‘s unique NUMA topology. Here, we are seeing the impact of the single I/O die as the result is top tier performance in Windows.
Next, we are going to look at our Linux benchmark results.



{kind=link}
I believe the header of the Power Load Test should read 12V, not 120V.
With regard to PCIe I/O has an interesting note on EPYCs. Some thing called “Preferred IO Device”:
https://www.dell.com/support/article/dk/da/dkbsdt1/sln319015/amd-rome-is-it-for-real-architecture-and-initial-hpc-performance?lang=en
I haven’t been able to figure what that is about or wether it’s only a Mellanox thing. Wonder if Threadripper has the same.
Really a shame about those RDIMMs. For this reason I’m going to have to get an EPYC at lower clocks for a workstation I’ll be getting next year instead of a TR. It’s a shame, really.
Totally agree about the platform thing. I’m not switching out CPUs in $6000+ computers.
How were the CPU temps with the noctua-nh-u14s-tr4-sp3? I am surprised that an air cooler could handle this monster!
Any tests that showcase performance for single threaded math heavy operations? I had to dump a previous threadripper built because it hugely lagged behind Intel CPUs mostly due to the absence of AVX2. Since then I have never touched AMD ever again. Am happy to revisit but I would like to see how it performs in single threads that require matrix computations and many millions of mathematical operations per second, ideally vectorized. Any such tests?
@John Lee Could you please make the textual output from lscpu available? I don’t want to be typing all these abbreviations by hand yet I want to see how many different features does it have compared to my trusty TR1920X. Thanks!
By the way, does anyone know what is the situation with encrypted memory main and encrypted memory for virtual machine with this generation of threadripper? The first generation showed support in the cpu flags but was missing something else from BIOS so it didn’t (wasn’t supposed to) work. It’s dick move by AMD to not support them on ThreadRipper, IMO, and I wonder if they kept it.
Thank you for a great review as always. I appreciate the inclusion of SPECworkstation, lots of programs there I use in the HPC world. I need to do some digging on my own to figure out how they build their tests though. Some of those programs are a mess of potential different libraries, MPI,BLAS,LAPACK,FFTW, etc.
Also I’d love to see some RandomX benchmarks like you did for Epyc. The 3970X should be perfect for it, I expect 25-30kh/s. While I’m asking, a deep dive on the cache would be interesting too, I’ve been seeing some results around online indicating there may be architectural differences in Zen2 Threadripper’s cache access vs Zen2 Ryzen.
Threadripper comes with an ECC caveat that’s if the Motherboard maker chooses to support it and then that ECC support is somewhat lacking compared to AMD’s Epyc branded SKUs. And the single socket Epyc P series of 7002 SKUs are still affordable with the MBs offering up more memory channels(8) and more PCIe lanes with the full vetting/certification for ECC memory types compared to any consumer Zen-2/MB based variants currently.
There are a few Benchmarks where the 3960X is performing on par or a little better than the 3970X and could that be the result of the 3 out of 4 enabled CPU cores on the 3960X’s CCX units still getting access to the same amount of L3 cache as the 4 enabled cores on the 3970’s CCX units where the 4 enabled cores have effectively less total L3 per CCX core to share among the enabled CPU cores than on the 3960X. I hope there will be more testing of the Cache subsystems on Zen-2 going forward for any SKUs that may have the full complement of L3 cache made available even though there is one, or more, core/cores pre CCX unit disabled and what workloads may benefit from having more total L3 Cache per enabled core on the CCX.
I’m really interested on seeing any testing done to confirm that for Zen-2 but Zen-3 will see AMD getting rid of the CCX construct altogether and making the CCD die/chiplet have its full Complement of L3 available to the full 8 cores instead of partitioning the CCD into 2 CCX Units. The big question for 8 cores per CCD and no CCX units besides less Infinity Fabric traffic needed to get at that larger shared pool of L3 cache on Zen-3’s CCD die/chiplet is will AMD switch to a Ring Bus configuration on the 8 core CCD or some more complicated topology for 8 cores versus the 4 cores/CCX construct that’s used currently.
Both AMD and Intel appear to be going wider order superscalar with their respective core designs in order to get more IPC in the face of getting less in performance advantages with the newer smaller process nodes not able to yield as much generational clock frequency increases as in the past. So Zen-3 will have to go wider order superscalar and maybe have some AVX512 options as well. I’d love to see AMD Bring some L4 cache to the I/O die at some point in time for any workloads that really can benefit but that’s maybe something that will have to wait for Zen-4 with hopefully Zen-3 getting some larger shared per CCD Die/Chiplet L3 cache over what Zen-2 offers.
Really the Epyc/SP3 motherboard warranty/support periods are much longer than any Consumer/Threadripper offerings and that has to factor in to TCO for any professional end users that can really also deduct Epyc’s higher up front costs as a business expense. And really as far as ECC CPU/MB partner support goes Epyc CPU/MBs are vetted/certified on all the professional software packages whereas Threadripper CPUs/MBs will have less testing/certification guarantees and less product support should that be needed from AMD and the SP3 Motherboard makers .
Threadripper may be sufficient for some if they absolutely need the higher clocks and are not dependent on ECC for certain workloads and maybe that’s good enough for some but folks need to do some more in depth cost/benefit analysis that also factors in the CPU’s cost/per memory channel and cost/per PCIe lane as well as the MB’s cost/memory channel and cost/PCIe lane. And that can make Epyc/SP3 the better deal on a cost/feature basis.
@Matt: You should check if it’s a fundamental issue or just Intel’s dirty tricks / lazy developers: https://old.reddit.com/r/matlab/comments/dxn38s/howto_force_matlab_to_use_a_fast_codepath_on_amd/
@Fabian,what has this to do with dirty tricks? Fact is that my math/linear algebra heavy programs on Intel CPUs ran circles around both the previous gen Threadripper and Epyc CPUs at otherwise identical frequencies and memory speeds. I could not care less what “games” anyone is playing when my back tests and other heavy math procedures finish in half the time on one CPU vs the other. I have been a very heavy amd critic for math heavy applications and voice such on this website multiple times. Am always happy to revisit to test new amd products but so far neither Epyc nor Threadripper came even close in performance to Intel’s cpu for math heavy applications.
@matt what fabian pointed to is that if you simply force matlab to properly recognize the math abilities of the AMD CPU it will run many more circles around the intel chips… the amd cups are faster on anything except a few avx512 special cases, so if you dont see that good chance it’s your math library that is heavily under utilizing the AMD chip. Nothing to criticize amd for, they cant fix your code for you.