Ansys with AMD Milan X
Ansys is very well known in the space, and we have run Ansys benchmarks on older 4-socket systems in the past. Ansys has been working on using AMD’s optimized math libraries and is getting gains based on that. One will notice that the 16-core AMD EPYC 73F3 is being used. A lot of Ansys’s licensing is per-core so typically this is a market we see a lot of frequency optimized SKUs being used.
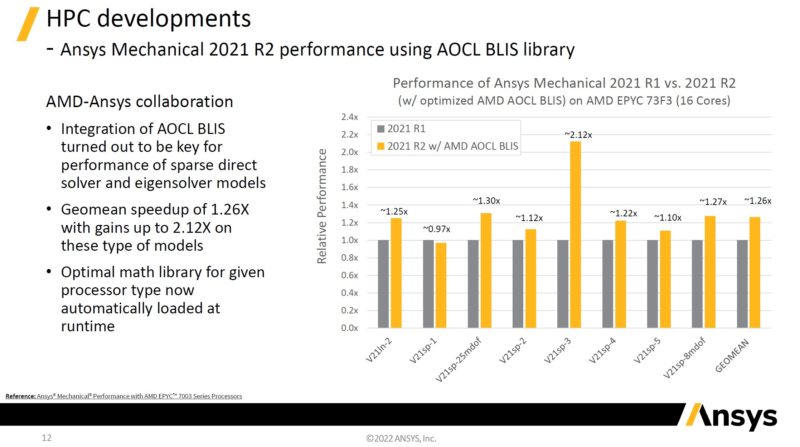
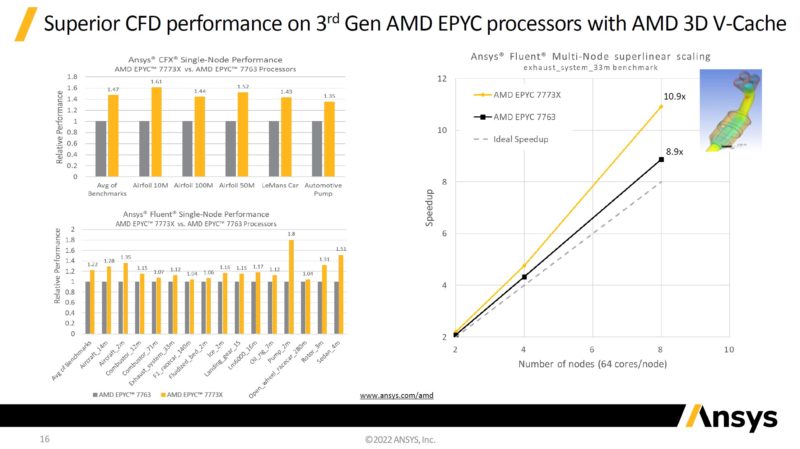
On the computational fluid dynamics front, Here is ANSYS’s scaling. The chart on the left uses an Intel Xeon Gold 6258R which is a 2020 era Cascade Lake part as a baseline. The right side of this chart is showing many workloads getting some super linear scaling. The f1_racecar_140m we discussed earlier in this section makes two more appearances here.
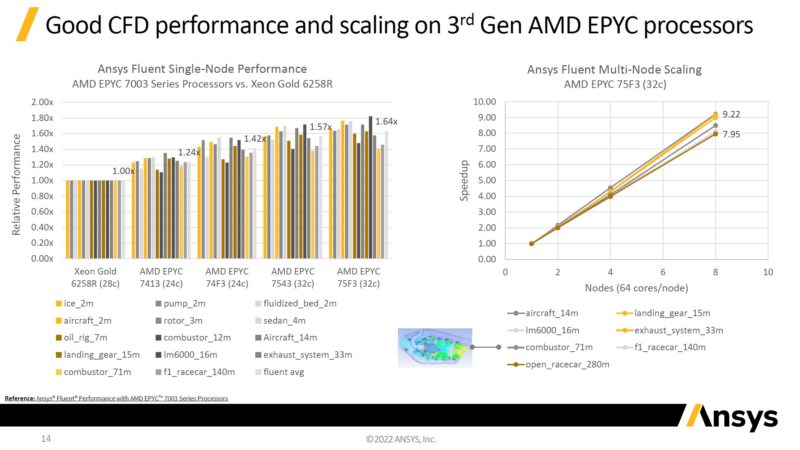
That same f1_racecar_140m is shown in the Ansys Fluent EPYC 7763 v. EPYC 7773X scaling chart.
Again, being licensed on a per-core basis means that significant gains from hardware either mean faster engineering cycles or lower costs. I asked all of the vendors presenting whether they would charge more for Milan-X cores versus Milan cores, and I was told no.
Synopsys VCS Simulator and AMD’s Internal EDA Data
When it comes to making chips, Synopsys makes tools to allow chip designers to design and test designs without having to fab test parts.
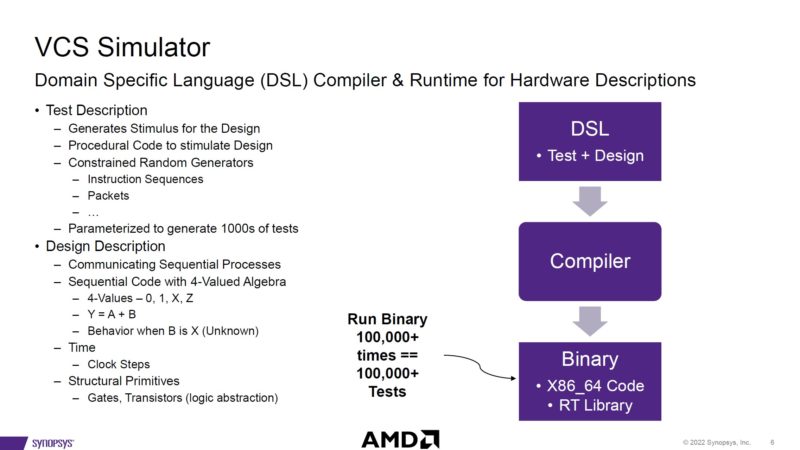
Interesting here is that AMD, naturally, is a customer of Synopsys tools. It also has a large number of machines doing EDA work constantly for its engineering teams to make chips, like the Milan-X.
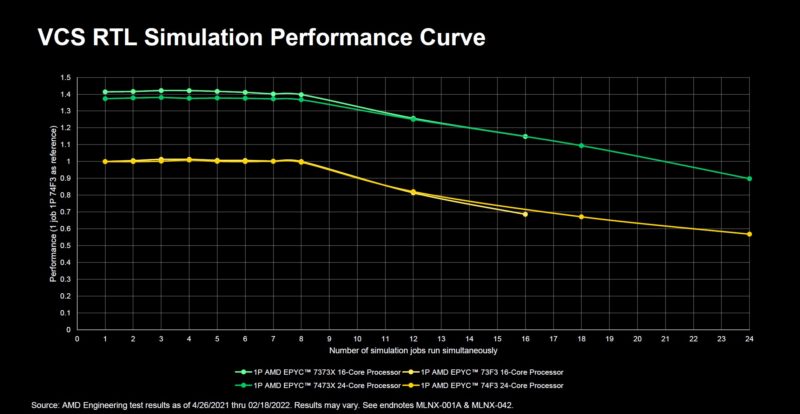
For this, instead of Synopsys sharing data, AMD used actual jobs and ran them in Azure to see the 3D V-Cache impact on its own EDA workloads.
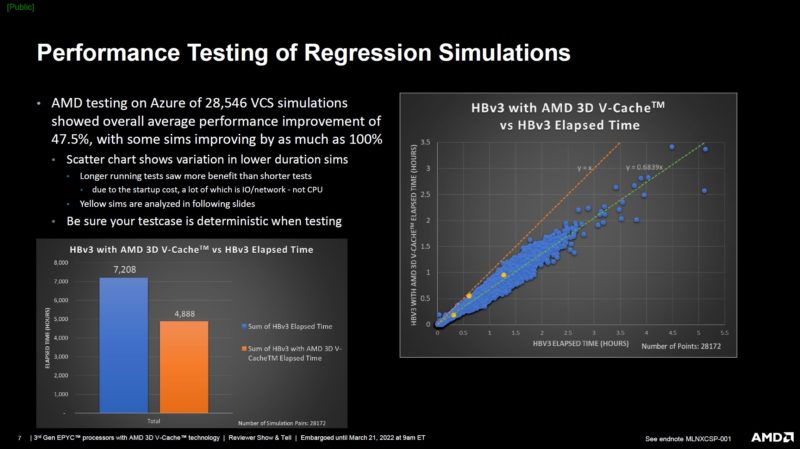
The key here is that not all workloads were necessarily faster with the new chips, again Milan-X has a frequency trade-off that if your workload cannot offset through cache hits, it will be slower than standard parts. Still, on balance, AMD is seeing the overall basket of jobs complete significantly faster.
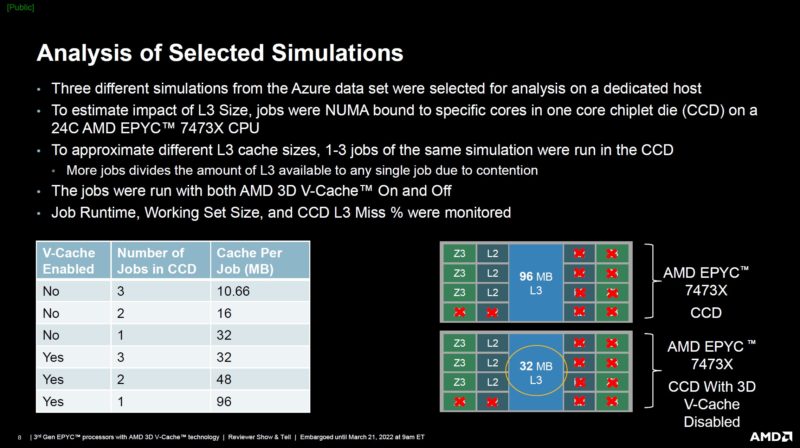
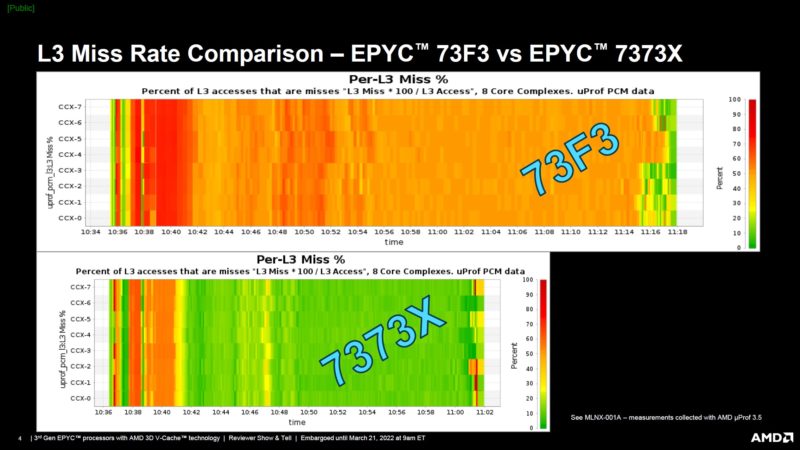
AMD picked three of these workloads, and it did not sound like at random, to show potential impacts of working set size (WSS) and L3 cache misses on performance.
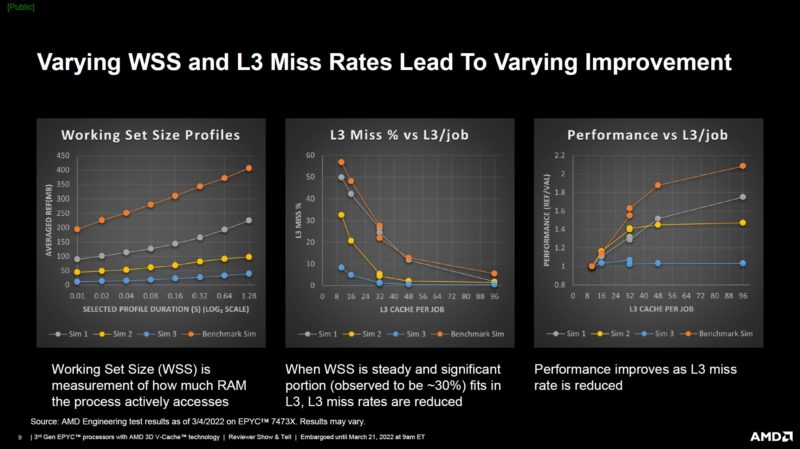
Here is an example of the cache misses over time for a frequency optimized part versus a Milan-X AMD EPYC 7373X 16-core part. One can see that the EPYC 73F3 had a lot of cache misses due to the smaller cache and that meant more trips to main memory.
Here is an IPC view. One can see that the AMD EPYC 7373X cores are being more efficient executing more by not having to wait for DDR4 access. Also, one can see at the very start of these charts that there is some initial work that looks fairly similar from an IPC perspective.
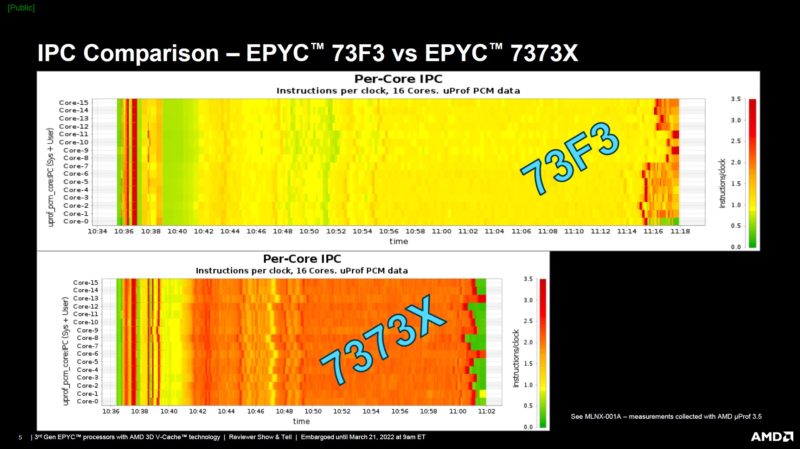
Some readers are going to take this as an awesome real-world use case. Some are going to dismiss it because AMD makes the products and is picking the sample set. Still, it is fairly interesting. We wish we could make those cache hit and IPC charts with an off-the-shelf tool, but it is using an AMD internal visualization tool.

We also wanted to see how Milan-X would perform on our workloads that are not design-specific so we put our AMD EPYC 7773X’s to use.



{kind=link}
This is excellent. I’m excited to get a r7525 with these and try them out. I sent this to my boss this morning and he OK’d ordering one so we can do profiling on our VMware servers
@cedric – make sure you order it with all the connectivity you’ll ever want. Dell has been a bunch of [censored] when we’ve opened cases about bog-standard Intel X710 NICs not working correctly in our 7525s. So much for being an open platform.
Not that I’m bitter.
Why the 7373X with 16c is more expensive than the 7473X with 24c ?
flo it’s because it has fewer cores so its cheaper to license.
Now that the 7003x “shipping”, perhaps they can get around to shipping the 7003 in bulk. I’ve got orders nearly 9 months old.
While per-core licensing costs seem to be a consideration for some people, I think this kind of optimisation is only possible because certain proprietary licensing models need updating to account for modern computer hardware. Given the nonlinear scaling between frequency and power consumption, it appears environmentally backwards to base hardware choices on weird software licensing costs rather than performance per watt or something similar that neglects arbitrary licensing constraints.
On another note, NOAA open sourced their weather forecasting codes a few years ago and WRF (based on models developed by NCAR) has been open source for much longer. I think the benchmark problems associated with these applications would make for an interesting journalistic comparison between new server CPUs with larger cache sizes.
@Eric – Environmentally backwards, possibly, but so often the hardware platform is the cheapest part of the solution – at least in terms of capital costs. I don’t think it’s necessarily unreasonable to optimize for licensing costs when the software can easily dwarf the hardware costs–sometimes by multiple orders of magnitude. To your point though, yes, the long-term operational expense, including power consumption, should be considered as well.
The move to core-based licensing was largely a response to increasing core counts – per-socket licensing was far more common before cores started reaching the dozen+ level. Hopefully you’re not advocating for a performance/benchmark based licensing model…it’s certainly been done (Oracle).
Lilu Dallas multipass :)
ok, so Taylor Swift has a Cache of 768Mbytes? I never woulda guessed :).
I find the speedups in compilation a bit underwhelming. My hunch is that the tests are performed the usual way – each file as a separate compilation unit. I work on projects with tens of thousands of C++ files and the build system generates files that contain includes for the several hundred cpp files each and then compiles those.
When you have a complicated set of header files, just parsing and analyzing the headers takes most of the compilation time. When you bunch lots of source files together you amortize this cost. I guess in such scenario the huge L3 cache would help more than for a regular file-by-file build.
Dell submitted SAP standard application benchmark, comparing 2 x AMD EPYC 7773X with 2 x AMD EPYC 7763 processor. Milan-x is able to show 14% increased in benchmark while serving 11,000 more users.
https://www.sap.com/dmc/exp/2018-benchmark-directory/#/sd?filters=v:4a9e824336e2837bf9081e423d579859;v:4a9e824336e2837bf9081e423d58f740;v:4a9e824336e2837bf9081e423d5a63e6
What happened to the Stockfish Chess Benchmark?