
At the AMD AI event where we featured the EPYC 9005 Turin CPU, AMD also launched a new AI GPU, the AMD Instinct MI325X. This accelerator is an upgrade over the MI300X, but it is also one that has changed a bit from when we have seen it previously. AMD also talked about its mid-2025 accelerator, the AMD Instinct MI355X.
AMD Instinct MI355X Announced and MI325X Launched
First off, here is the OAM packaged MI325X with its air-cooled heatsink.

It is wild to think that STH was showing similar giant OAM heatsinks back in March 2019 and now they are commonplace.

Underneath, we can see that the OAM module is labeled as the MI326X IFX OAM. We can also see this is using HBM3E memory.

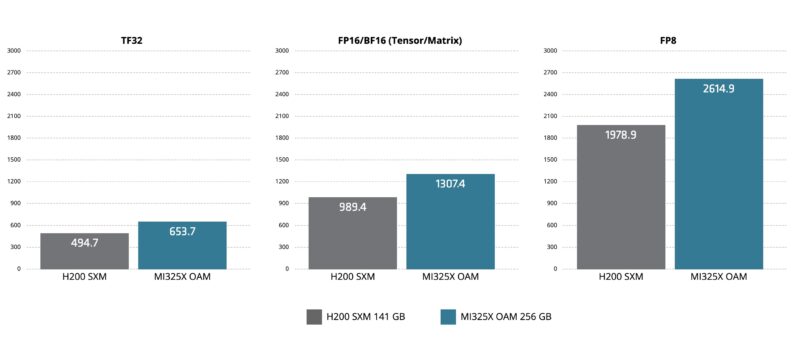
In terms of specs, we heard that AMD is getting some benefit from tuning core frequencies, but that swap to HBM3E is giving it more memory. AMD now has 256GB of HBM3E onboard which is simply much more than the NVIDIA H200’s 141GB. AMD also gets a bit more memory bandwidth.

Packaged in the OAM module, the GPUs are not really meant to be deployed one at a time. Instead, they are designed to be installed in the Universal Baseboard or UBB platform with eight of the accelerators.

This quarter, NVIDIA’s key competitor is the NVIDIA H200. AMD is showing it can compete here. Of course, NVIDIA is also working to ramp Blackwell.
Next year, AMD plans to launch the AMD Instinct MI350 series with FP4 and FP6 support and also on 3nm.

AMD plans to use CDNA 4 architecture to achieve a speedup on the 2025 parts.

Between all of the advancements, AMD is saying a 35x performance increase on its next-generation.

In 2026, AMD will have a next-gen architecture with the MI400 series.

Our sense is that NVIDIA will have an update in 2026 as well.
Final Words
Looking forward to 2026, the AMD Instinct MI400 will be the big architectural overhaul. What is cool is that we are in a full-scale GPU arms race in the industry. AMD’s AI accelerator sales are significantly behind NVIDIA but also significantly ahead of Intel and many AI startups. AMD seems to be focusing on selling its GPUs with a focus on high memory capacity at the moment. With around 80% more memory capacity than the NVIDIA H200, AMD can fit larger models in single GPUs and single systems. Staying on a package has many performance, power, and cost implications for inference at scale.



{kind=link}
Does it run PyTorch with ROCm?
to Yamamoto-san: Yes, AMD Instinct GPUs provide GPU acceleration support through the ROCm stack, supporting deep learning frameworks such as PyTorch, TensorFlow, and JAX.
to Yamamoto-san: Yes, AMD Instinct GPUs provide GPU acceleration support through the ROCm stack, supporting deep learning frameworks such as PyTorch, TensorFlow.
Jake-san, thank you, the competitor product is too expensive therefore I’m interested in AMD solution, but the information about actual usage is scarce.
@Yamamoto – no, that info is not scarce, you & the likes of you are just taken by the wave of hype, being swept away from everything else – also known as echo-chambers – suffices to poke around a bit (like STH + other journals do) to realise, there exists whole different/similar worlds, where things are equally or more eventful & joyful (including TCO too)
I’m just crying into my now useless PCIe slots.
@Yamamoto, it runs Pytorch on ROCm on Linux only. Pytorch on ROCm on Windows is not supported.
@lejeczek – yes the AMD info is out there but it is fragmentary and not very well search optimized, as well as being pooy organized. If one searches for a ROCm topic one is as likely to get info from years ago, from obsolete versions of ROCm as one is to get current info. And there are an alarming number of dead links in ROCm docs. Which leads to confusion. nVidia by contrast exercises Stalinesque control over it’s online documentation for CUDA and it is difficult to find confusing CUDA info.
Do you think MI400 will be CDNA5, or will they go straight to UDNA1?