
This is one of those odd AMD talks. The company often goes into detail on products that have been shipping for some time and that we have already covered on STH during Hot Chips. That is just a corporate decision by the company on when to present new architectures. For Hot Chips 2024, that is the AMD Instinct MI300X. We know the MI325X refresh is soon-ish. Still, this is one of the only (public) GPUs outside of NVIDIA GPUs that is running at a multi-billion dollar a year run rate for the AI industry. AMD just bought ZT Systems that makes the Microsoft Azure MI300X platform last week.
Please note that we are doing these live at Hot Chips 2024 this week, so please excuse typos.
AMD Instinct MI300X Architecture at Hot Chips 2024
Since it is getting late in the day, and AMD has good looking slides, we are going to let folks read them and just add some color as we go. We covered the AMD Instinct MI300X GPU and MI300A APUs in December 2023.

The MI300A has mostly found its way into supercomputers like HPE’s El Capitan. It seems like the MI300X is driving most of the $4B+ of revenue this year for the line.
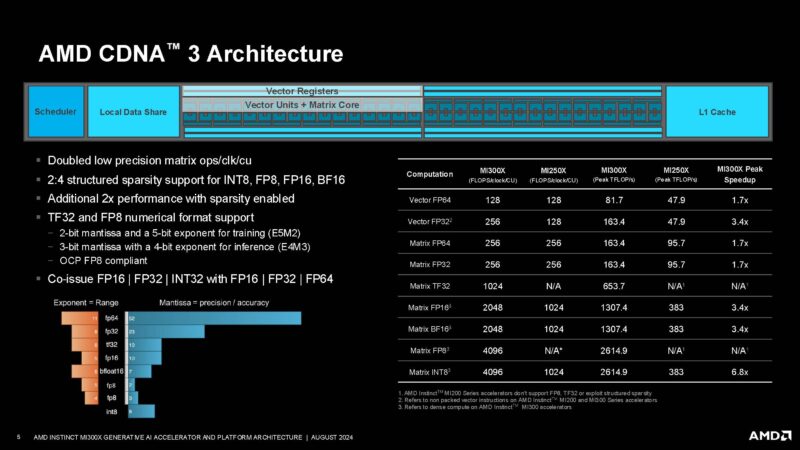
AMD has a fairly complex chip with 192MB of HBM3, chiplets for compute, and more.

Here is the evolution of the AMD CDNA 3 architecture.
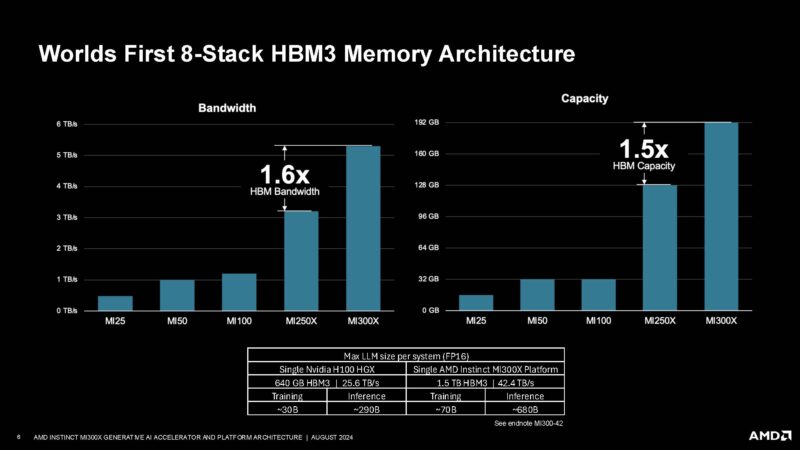
AMD has an 8-stack HBM3 memory array that was huge at the time at 192GB.
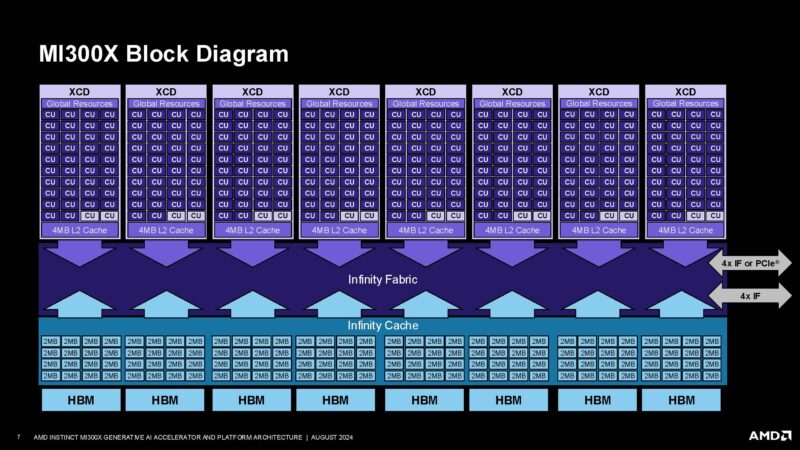
Here is the block diagram with the XCDs for compute as well as the Infinity Cache, Infinity Fabric, and the eight HBM packages.
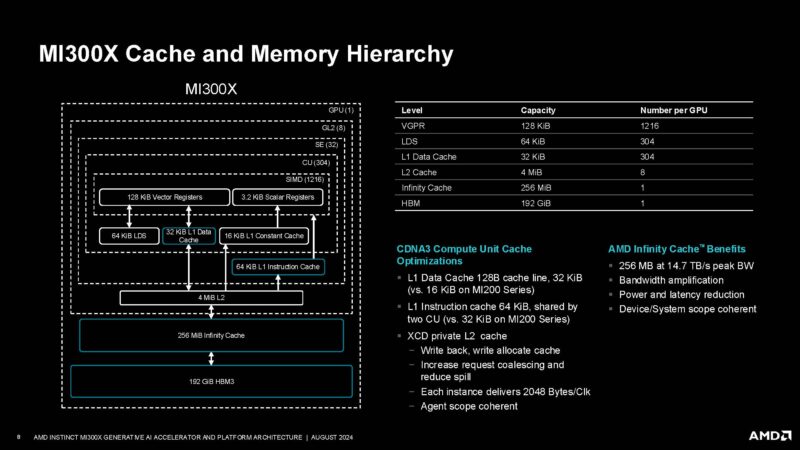
Here is a look at the cache and memory hierarchy. We can see not just the 192GB of HBM3, but also the 256MB of Infinity cache, 8x 4MB of L2 caches, and so forth.
The MI300X can be run as a single partition or in different memory and compute partitions.

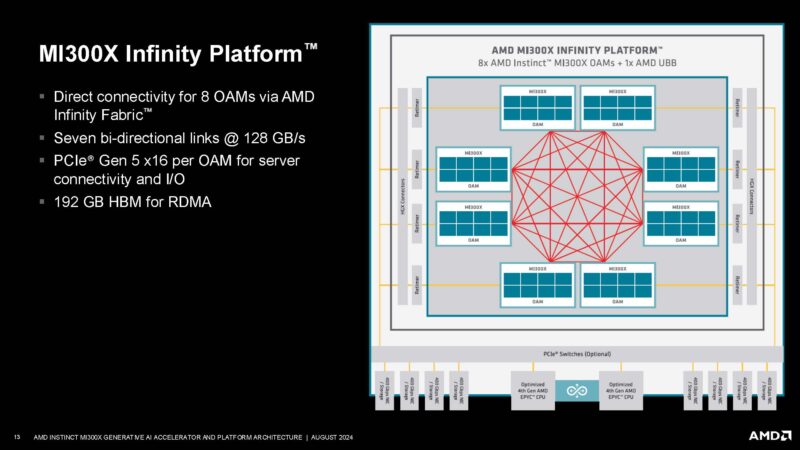
AMD’s big platform is currently the 8-way MI300X OAM platform.

Here is the Instinct system journey. The MI200 saw in an OAM board as well but it is shown as a single GPU here.

Here is AMD’s answer to the NVIDIA HGX platform.

Each GPU has seven links for direct connectivity plus host links.
After the OpenAI talk today, RAS is a big deal in large-scale AI clusters.
Here are AMD’s servers. The Microsoft/ ZT System’s MI300 platform is not called out here. It is a bit of a bummer that Dell is still not offering EPYC in its AI platforms. Also notably missing is the Wiwynn platform.

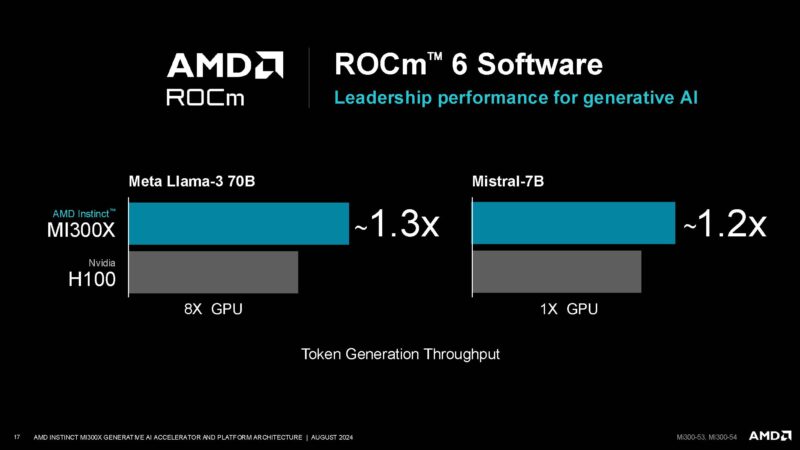
AMD is talking about ROCm which is getting much better.

In some cases, AMD can beat the NVIDIA H100. Of course, we expect folks to start deploying NVIDIA H200 more frequently, especially if they can go liquid-cooled and the B100/B200 are coming. On the AMD side, AMD committed to the MI325X as well. So this needs to be taken into the context of timing.
Here is MPT fine-tuning where AMD says it equals the H100.
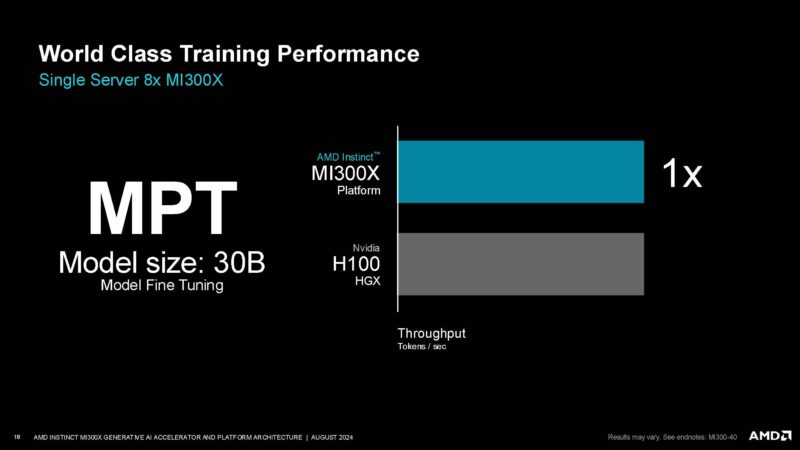
x
Final Words
Putting this into some context when this talk is happening, almost three months ago we learned about the 2025 AMD Instinct MI350 288GB GPU and the MI325X for 2024.

So the MI300X was the company’s 2023 design and it is now going head-to-head with the H100, when we expect both will be displaced in the not-too-distant future with higher memory versions.
Still, AMD has solidified itself as a #2 behind NVIDIA for AI GPUs with a multi-billion dollar product line. That is awesome. Now, we just want to see more about what is next, but it might be until Q4 until that happens.



{kind=link}
Is it known what batch size AMD is using for their MI300X performance claims? Last time AMD claimed these numbers, Nvidia posted this blog post basically showing how AMD cherrypicked useless numbers (batch size 1) that are irrelevant to real world application
https://developer.nvidia.com/blog/achieving-top-inference-performance-with-the-nvidia-h100-tensor-core-gpu-and-nvidia-tensorrt-llm/
OK, now put it on a PCIe card so us mere mortals can make use of it!