
At Computex 2019, we had some fun controversy in the server space. During the AMD Keynote, AMD showed off the upcoming 64-core AMD EPYC “Rome” generation performance in NAMD versus dual 28-core Intel Xeon Platinum 8280 CPUs. After the keynote, Intel quickly followed with a response showing results with its Intel Xeon Platinum 9200 series, followed by results with its Platinum 8280s. Behind the scenes, I was giving feedback to Intel and AMD. I wanted to present our readers with my feedback.
AMD EPYC Rome NAMD Keynote Presentation
The presentation looked innocent enough. 128 AMD EPYC Rome cores for a ~102% performance increase over a 56 core Intel Xeon platform. Over twice the cores and just over twice the performance was the message.

If this was 2016, Intel would likely not have responded. Instead, this is 2019 and we now are starting to see Intel understandably wanting to protect its position, especially since it knows Xeon is vulnerable in Q3/ Q4 2019.
Intel Offers Platinum 9200 Results
The first benchmark Intel offered was of the Intel Xeon Platinum 9200 series. Let us be clear, a 64 core AMD EPYC Rome part we expect to be in the 200-300W range, not at 400W. AMD will have broad ecosystem support. We saw several dozen Rome platforms at Computex 2019 alone. Conversely, we explained why the Intel Xeon Platinum 9200 series lacks mainstream support. For our readers, we suggest disregarding Intel Xeon Platinum 9200 benchmarks wholesale for competitive analysis. Virtually the only time they are better than the Intel Xeon Platinum 8200 is if you need extreme density where you can have 4x 400W CPUs per 1U.
AMD Discussion
Just after the keynote, I had a discussion with Forrest Norrod SVP and GM of AMD’s server and embedded businesses. I asked if AMD was using gcc instead of icc and was told they were using icc and the best they knew how. Frankly, asking someone of Forrest’s level benchmark details is not something I like to do. Asking an executive detailed benchmark setup questions is a bit unfair if they do not have supporting materials on hand. Doing so means they are commenting on something someone on their team did.
Fair enough, AMD maintains it attempted to present a fair assessment.
Intel Fires Back with Intel Xeon Platinum 8280 Figures
At the same time, I was pushing Intel for Intel Xeon Platinum 8280 figures. I was first sent the Platinum 9200 series benchmarks and I said, something along the lines of “great, but not comparable. Get me your Platinum 8280 numbers.” Intel did.
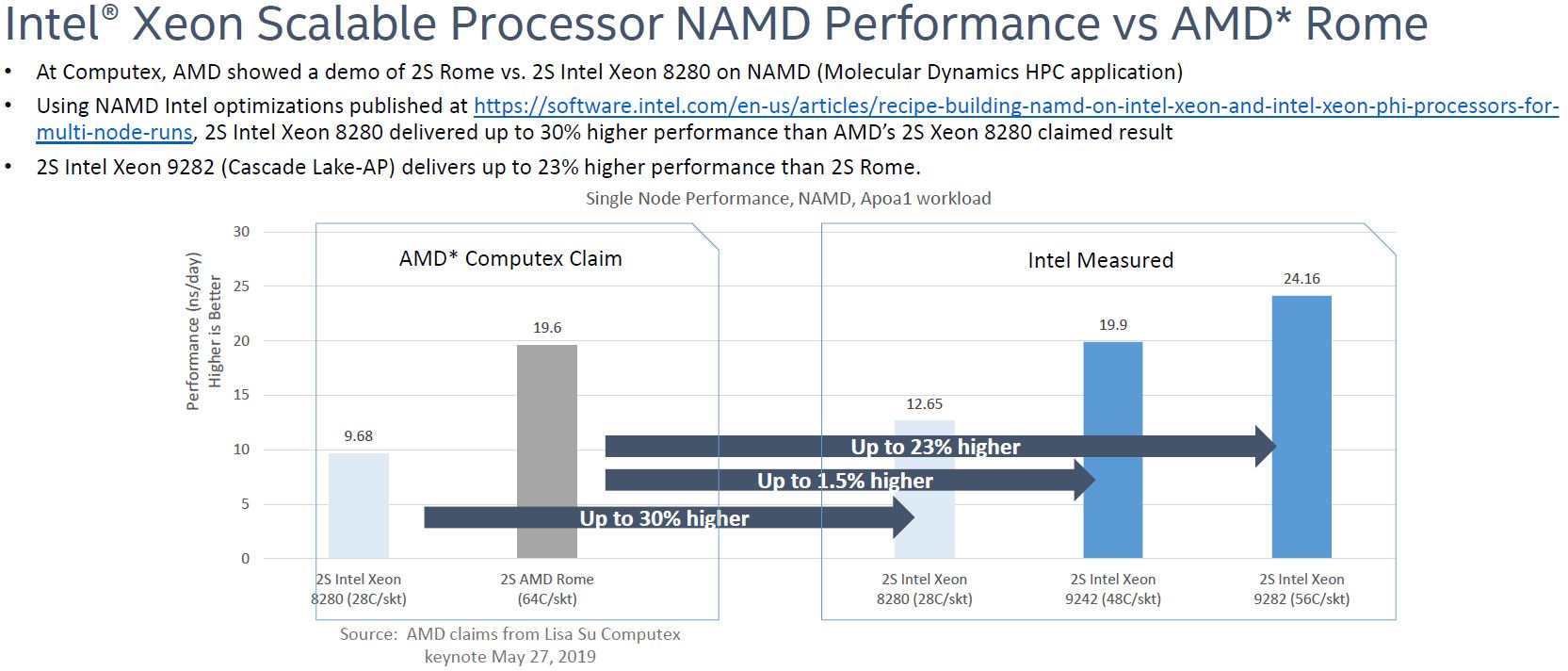
A quick aside: NAMD is an old, well-known HPC benchmark. That means folks have high levels of optimizations for it. This is a benchmark Intel has queued up in their lab with suggested BIOS settings, compiler flags, and etc. Intel even has an article published on optimization here.
As many folks witnessing this had suspected, Intel was able to get better performance from the Intel Xeon Platinum 8280.
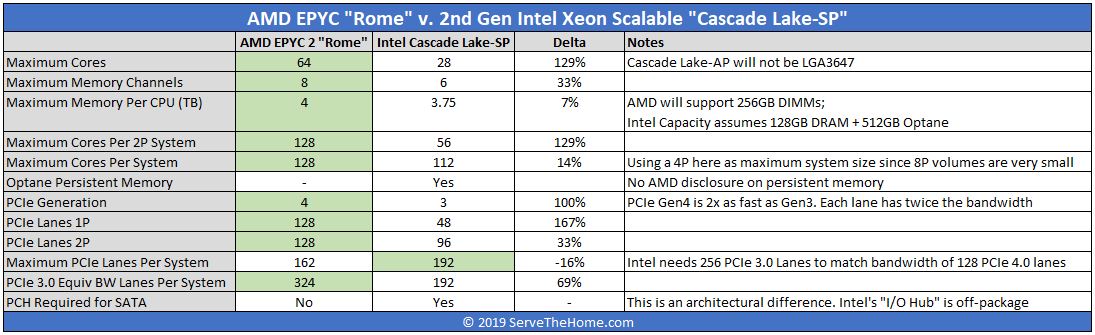
Where AMD Missed
Using NAMD is good because a lot of people know it. On the other hand, there is a danger presenting an absolute figure when someone else has better hand tuning experience. NAMD optimizations on Intel Xeon have happened over countless runs.
Second, AMD needed a picture like this:
The bigger place that AMD missed was in using NAMD in the first place. From our November 2018, Top500 analysis here is the CPU breakdown of the new computers on that list.
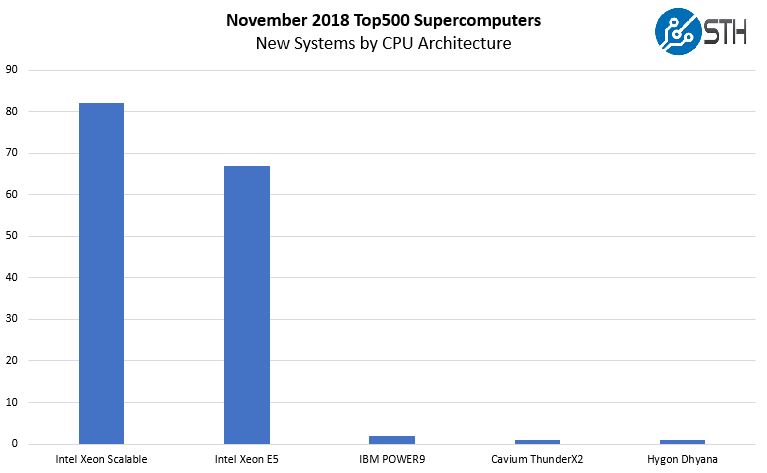
Intel Xeon does well, largely due to how companies like Lenovo use hyperscale web server installations split into blocks and then running Linpack just to pad their stats on the list. Still, Intel Xeon is pervasive on the Top500 and NAMD is a workload that many Ph.D. students have spent meticulous hours learning to optimize on Intel Xeon CPUs. At SC17 I overheard a heated exchange about the best BIOS settings for NAMD.
AMD could have chosen a less well-optimized application, but it takes gusto to charge into the bullpen and challenge Intel head-on.
Taking Stock on Post-Intel Numbers
Taking Intel’s slide, we are going to break it down to something workable for Q3/ Q4 2019 server buyers.
First, we need to remove the niche Intel Xeon Platinum 9200 SKUs. As we previously mentioned, they are not competing with 64-core AMD EPYC mainstream processors. The Intel Xeon Platinum 9242 is a 350W TDP part. If Intel is offering a PCIe 3.0 solution with half the lanes as a dual AMD EPYC Rome solution at 350W TDP per socket and claiming similar performance, you will think that is abysmal Xeon efficiency when Rome launches. Rome details are not public, but we will simply say that 350W is not competitive.
That leaves us with a picture that looks like this:
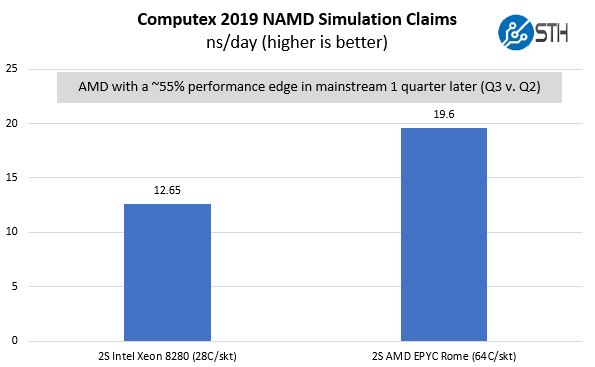
If we take AMD’s best number that they have shared along with Intel’s best number, AMD is slightly later to market but is offering 55% more performance than Intel’s mainstream top-end part that is shipping today. That is a massive improvement. Combine this with more memory channels, memory capacity, PCIe lanes, PCIe Gen4 bandwidth, and we are no longer in the realm of this being close given Intel’s Cascade Lake family launch two months ago. Then again, one can buy an Intel Xeon Platinum 8280 today, and not a 64 core AMD EPYC Rome part (unless you are a large AMD early ship customer.)
AMD did not show power consumption or TDP of the chips used. Our sense is that it will end up somewhere between the 205W TDP Intel Xeon Platinum 8280 and the 350W Intel Xeon Platinum 9242.
Final Words
The key takeaways are this:
- AMD showed a benchmark that Intel is fluent in, and where the market expects high levels of optimization
- Intel tried using “halo” products that are 350W-400W TDP per sockets that are not readily available on the market to claim equal or better performance
- Intel’s numbers show AMD will still have a massive lead later in 2019 with Rome in one of its home court benchmarks
- Both companies are using a healthy dose of marketing spin
Overall, 2019 is going to be a lot of fun in the server space. Stay tuned for a first-hand view of what is to come.



{kind=link}
A 64c/128t Rome core has an operational boundary around 250W TDP. Just as a heads up.
How about comparing dual Rome CPUs with quad Xeon Gold 6252 (24c/150W/$3,665 list ea)?
That should be much closer performance-wise and in terms of RAM size (with 64GB DIMMs – as 128GB are still considerably more expensive per GB) and total IO speed.
It makes sense for AMD to keep the TDP close to the prior generation, that saves time and money where (in some cases) the only change is the CPU (assuming that the you don’t want to pull the motherboard and get PCIe 4.0) and one doesn’t need to upgrade the power supply and cooling solution.
Another consideration is that 6 nm is a die shrink, that easily leads to a modest bump next year. Also with the finalization of PCIe 5.0 the CPU could support that, even if no motherboards do. It looks like AMD has a few tricks up it’s sleeve that we likely won’t see Q4, but probably next year.
Does anyone else think AMD would have been better off using a workload that doesn’t rely upon AVX-512?
With AVX-512 the all-core clockspeed of the 8280 goes down from 3.3 GHz to 2.4 GHz.
In the future a NAMD version for AMD GPU’s will come out which will be able to use the VRAM of the GPU’s (via infinity fabric when you need more the a single GPU can provide) and when that is not sufficient it can offload it to system memory over PCI4 at the moment en PCIE5 in the future. With NVidia you can use NVLink but you can’t offload to the system memory.
OK AMD just showed off some new “Vega 2” based Pro Graphics Products(Vega 20 DIE based variants) that are not only using PCIe but Infinity Fabric for GPU die to GPU die communication. So I’m more interested in finding out just when there will be any Epyc CPU to Radeon Pro GPU interfacing via that xGMI(Infinity Fabric Based) direct attached accelerator usage model that’s similar to what Nvidia’s NVLink does for interfacing Nvidia’s GPUs to CPUs(Power9).
AMD’s Epyc/Naples supported xGMI but that was only used for inter-socket processor to processor communication so what about Epyc/Rome or Epyc/Milan and any Epyc CPU to Radeon Pro GPU accelerator SKUs more directly connected via that xGMI(Infinity Fabric Protocol) interfacing at 5 time the bandwidth of PCIe 3.0. And Infinity Fabric has more coherency specific signalling that’s more deeply integrated into AMD’s CPU/GPU processor IP than any PCIe standards signalling supports.
If AMD’s Infinity Fabric is 5 times the bandwidth and at a much greater level/granularity of coherency than PCIe 3.0 supports then that implies that Infinity fabric will maybe be faster than PCIe 5.0 as well and definitely the Infinity Fabric will have the better level of CPU/GPU integration in AMD’s processor lineup going forward since Vega and Zen Epyc/Naples.
Don’t get me wrong AMD’s GPUs will still have PCIe compatibly but that will be in addition to AMD’s Infinity Fabric/xGMI IP that’s a great deal more integrated into AMD’s processor lineup than just some PCIe controller/controllers hanging off of SERDES links. Those Radeon Vega 2 Pro/Pro Duo SKUs are in addition to AMD’s Radeon Instinct MI50/MI60 AI variants and I’m more Interested in seeing AMD’s Epyc CPUs begin to make use of some form of xGMI(Infinity Fabric) communication options with Radeon Pro GPUs on Graphics Workstations rather than only PCIe 3.0, or 4.0, interfacing that’s used currently/soon to be in use.
Hopefully any CPU to Radeon GPU xGMI(IF protocol based) interfacing will be available by Epyc/Milan and AMD’s/Cray DOE Exascale supercomputer is supposedly some custom AMD Zen3 CPU variant and will not be based on any Epyc/Milan reference designs. But currently Nvidia’s GPU NVLink to Power9 CPU interfacing offers a bit more performant and coherent of an interfacing method than even PCIe 5.0 could provide.
The Radeon Vega 2 Pro duo is using Infinity Fabric links to interface the 2 GPU DIEs across its PCIe card’s PCB and in addition to that there are 2 Infinity Fabric based xGMI links that can connect up to 2 Radeon Vega 2 Pro Duos to each other on Apple’s new Mac Pro. So what about that GPU die to GPU die topology block diagram across 4 GPU DIEs on any 2 GPU card configurations(2 Vega 2 Pro Duos) that’s missing from any of the press materials on that SKU. And I’m sure there will be variants that are not restricted to only Apple in the future. I’d expect that AMD’s Vega 10 based Radeon Pro V340 SKUs(Dual Vega 10 DIEs/single PCIe card cloud gaming/graphics visualization SKU) will be getting updated to using 2 Vega 20/7nm GPU DIEs on and updated SKU, and very likely to be interfaced via the infinity fabric as well.
Rome 64c 2.2 GHz will draw 225W.
See spec sheet below of an announced super computer for norway.
https://www.sigma2.no/content/tidenes-kraftigste-norske-superdatamaskin-til-forskere
If TSMC is able to produce epyc in huge quantity and with a 70% yield as if seems (bitandchips source) , hyperscalers are going to rush to AMD.
this may be a very strange question:what they show on the screen/ppt?,a protein complex with 6-7 alpha helix,a quite distinctive feature.Is it some sort of transmembrane channel/receptor(may be a G protein coupled receptor) or an enzyme complex(ATP synthase may be)
Wait and see, 2019-2020 should be the opportunity for AMD!
Anybody have an idea when the Epyc 7371 will finally be available?
Hendrik – it is available in supported systems since early Q1 2019.
Thanks Patrick,
I mean to purchase the chips separately only for our server build. They do not seem to be available commercially yet.
Hendrik