2nd Gen Intel Xeon to AMD EPYC Bergamo Performance
To look at performance, I wanted to focus on something other than the top end for the previous generation. That started a process of which SKU we should use. For that, I asked Supermicro what its most popular SKU was for the 2nd Gen Intel Xeon servers. They looked at their internal data, which can be skewed by a few large customers, but it was the best we had. That led us to the Intel Xeon Gold 6252, a 24-core processor.
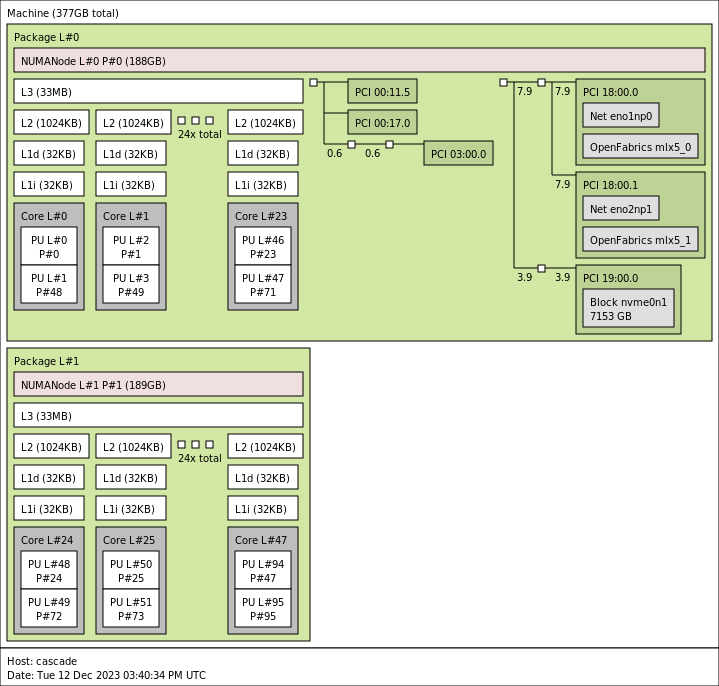
For the AMD EPYC Bergamo, the range is between 112 to 128 cores, so we are using the 128-core part with SMT. Just for some perspective, all 256 threads running at 100% below are on a single CPU socket.
That greatly simplifies the system topology since all PCIe devices and cores attach to the same IO Die. In dual-socket servers, if you use a single high-speed NIC, for example, data may have to traverse the socket-to-socket link before getting to the network. In a single socket, every application, container, and virtual machine has direct access to the NIC. The same situation is the case for SSDs, and that is why one sometimes sees dual-socket all-flash servers run into performance challenges because they can saturate either memory bandwidth or socket-to-socket links.
Now, there are many organizations that assign cores to virtual machines and then underutilize the cores. Think of the applications that get 2 vCPU or 4 vCPU VMs and then run at 5% CPU utilization for years. If your organization simply uses core counts, then your consolidation ratio from the popular 2021-era Gold 6252 to the 2023-era EPYC 9754 will be 5.3:1, moving from 24-core to 128-core CPUs. The per-core performance also matters because there are applications that need raw CPU performance.
For those who care about performance, we have some numbers for you.
Python Linux 4.4.2 Kernel Compile Benchmark
This is one of the most requested benchmarks for STH over the past few years. The task was simple: we had a standard configuration file, the Linux 4.4.2 kernel from kernel.org, and made the standard auto-generated configuration utilizing every thread in the system. We are expressing results in terms of compiles per hour to make the results easier to read.
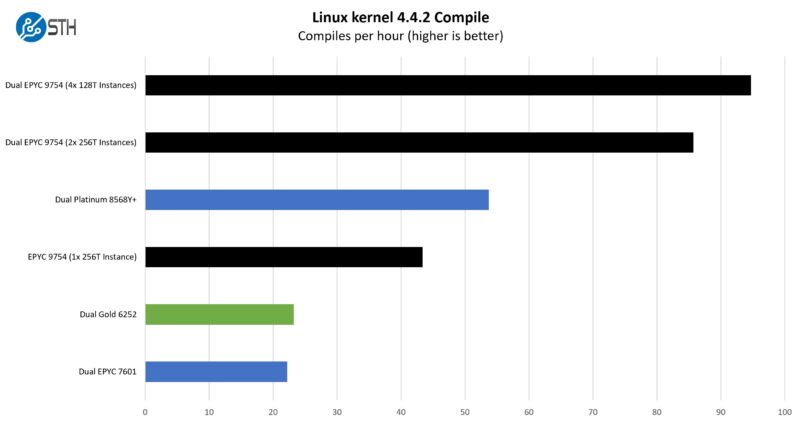
This is not quite 4x the per socket CPU performance, but then again, it is not that far off. One of the challenges with newer CPUs is that running a single workload across the entire CPU ends up eventually getting bottlenecked when the workload hits single threaded portions. Applications that scaled nearly linearly up to 32 threads, 64 threads, and so forth might not make the jump to 256 threads per CPU or 512 total.
c-ray 1.1 Performance
We have been using c-ray for our performance testing for years now. It is a ray tracing benchmark that is extremely popular for showing differences in processors under multi-threaded workloads. Here are the 8K results:
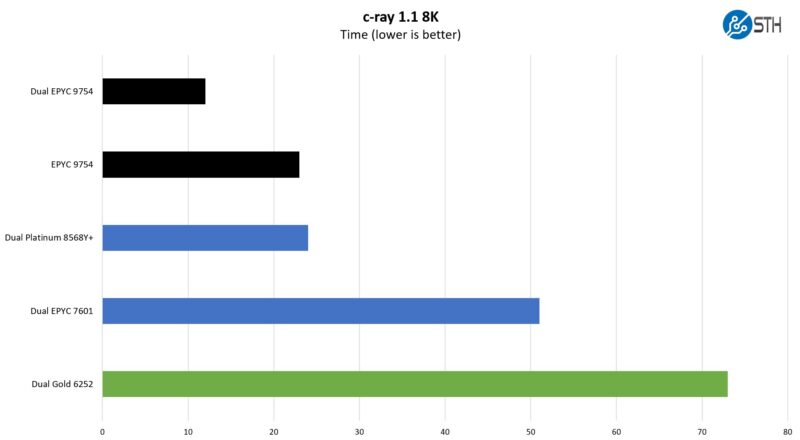
Something to keep in mind here is that AMD’s architectures tended to perform better in this type of test just due to caches. On the cache side, it is worth remembering that although we call Zen 4C a reduced cache chip versus Zen 4, it still has more L3 cache per core than we saw on the typical 2nd Gen Intel Xeon.
SPEC CPU2017 Results
SPEC CPU2017 is perhaps the most widely known and used benchmark in server RFPs. We do our own SPEC CPU2017 testing, and our results are usually a few percentage points lower than what OEMs submit as official results. It is a consistent ~5% just because of all of the optimization work OEMs do for these important benchmarks. Since there are official numbers at this point, it feels right to use the official numbers if we are talking about a benchmark.
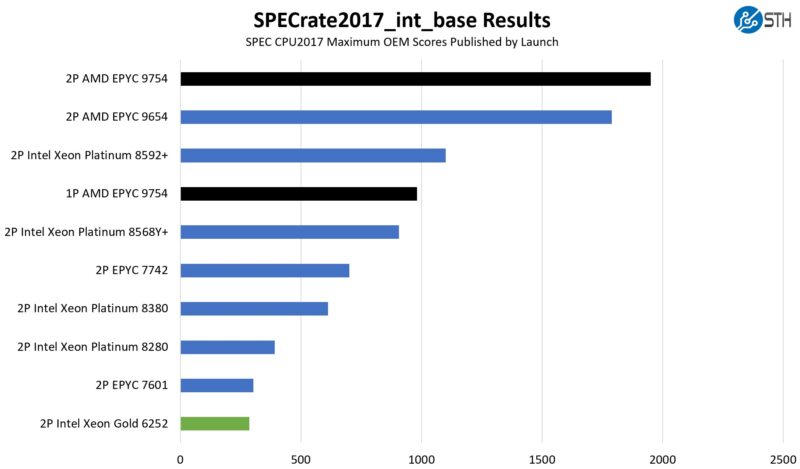
First, we are going to show the most commonly used enterprise and cloud benchmark, SPEC CPU2017’s integer rate performance.
On the floating point side here are the figures:
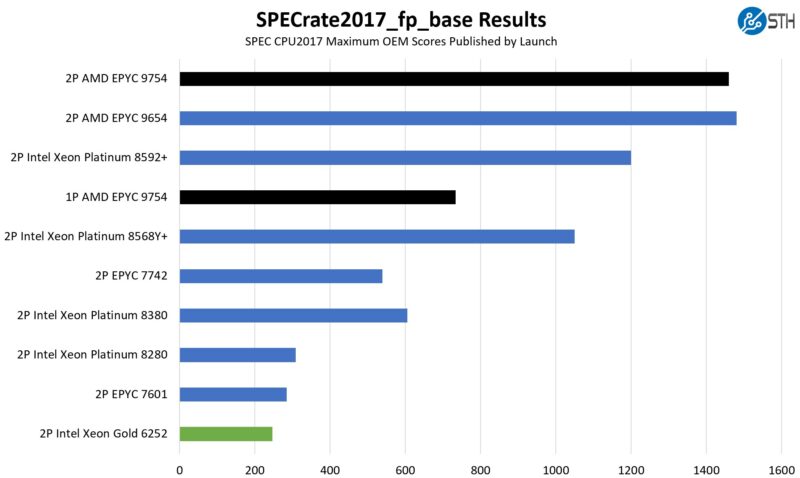
We put some figures for the top-bin parts in each generation as well just to put the numbers in perspective. The two SKUs we have are not the top-end but are in the upper half of SKUs for their generations.
128 cores per socket is just so much more than what was available in the 3-5-year upgrade cycle that we see huge deltas. The single-socket AMD EPYC 9754 is consistently significantly more than twice the performance of the dual-socket Intel Xeon Gold 6252. If you use these as your sizing benchmarks, then you might be looking at closer to a 5:1 server consolidation ratio which is crazy.
STH nginx CDN Performance
On the nginx CDN test, we are using an old snapshot and access patterns from the STH website, with DRAM caching disabled, to show what the performance looks like fetching data from disks. This requires low latency nginx operation but an additional step of low-latency I/O access, which makes it interesting at a server level. Here is a quick look at the distribution:
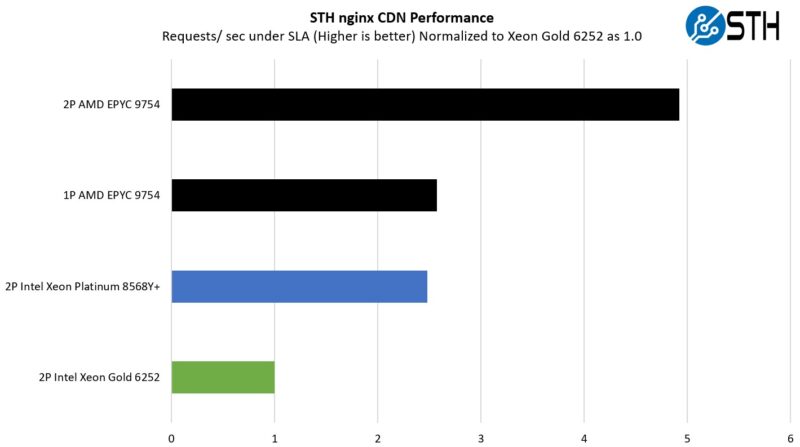
Running a very real-world workload for us, we got just shy of a 5:1 consolidation ratio, which is awesome. Even the single socket platform does very well here. This is one of the common use cases for AMD and for Arm server vendors because it involves serving web pages. On one hand, it is not the most demanding workload and scales well with cores. On the other hand, there are a lot of virtual machines, containers, and servers out there that just serve web pages, images, and video.
MariaDB Pricing Analytics
This is a very interesting one for me personally. The origin of this test is that we have a workload that runs deal management pricing analytics on a set of data that has been anonymized from a major data center OEM. The application effectively looks for pricing trends across product lines, regions, and channels to determine good deal/ bad deal guidance based on market trends to inform real-time BOM configurations. If this seems very specific, the big difference between this and something deployed at a major vendor is the data we are using. This is the kind of application that has moved to AI inference methodologies, but it is a great real-world example of something a business may run in the cloud.
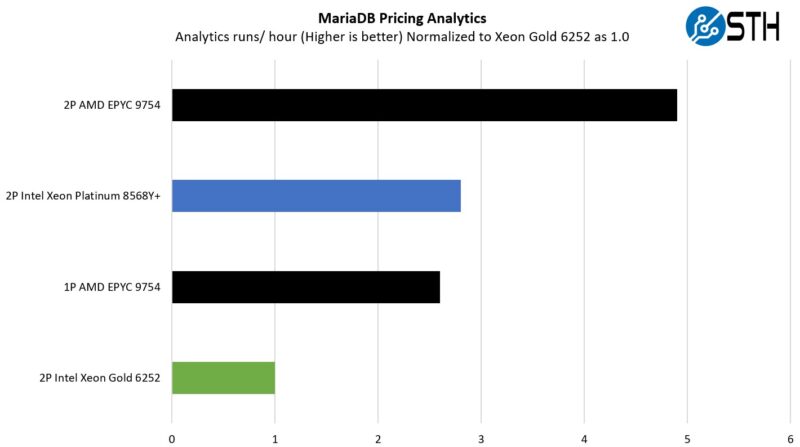
Here, the net gain is over 5x per socket performance. Having newer cores with bigger caches and then simply more cores really helps here. Today one would likely run this as an AI inferencing task for a bigger performance increase, but this is running a financial model that has to be accurate because there were revenue recognition implications for the company.
STH STFB KVM Virtualization Testing
One of the other workloads we wanted to share is from one of our DemoEval customers. We have permission to publish the results, but the application itself being tested is closed source. This is a KVM virtualization-based workload where our client is testing how many VMs it can have online at a given time while completing work under the target SLA. Each VM is a self-contained worker. This is very akin to a VMware VMark in terms of what it is doing, just using KVM to be more general.
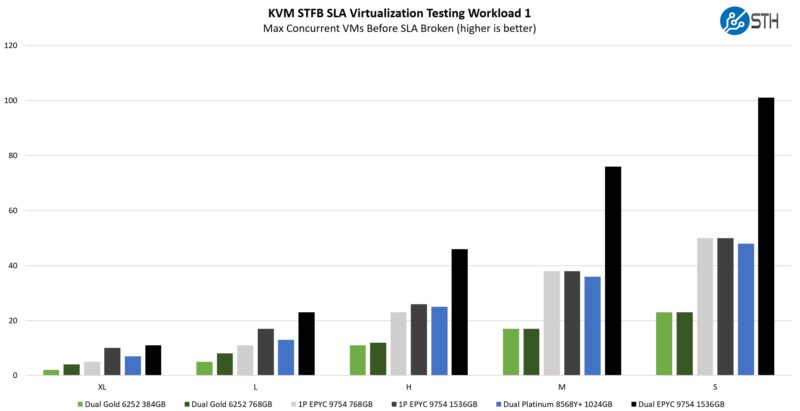
On the virtualization side, we can see two ends of the spectrum between being memory capacity-bound and being CPU-bound. For example, on the small VMs, using 24x 32GB DIMMs on the AMD EPYC 9754 single socket system gives us very similar performance to using 24x 64GB on the smaller VMs, but then the difference is much larger on the XL VM sizes. Memory capacity certainly comes into play in virtualization workloads. Still, a lot of the cloud-native push is really the masses of VMs. These are the workloads where you see small VMs with 2-4 vCPUs and lower memory needs of 4-8GB/ vCPU. Sometimes you just need more cores, and that is where having 128 cores per socket really shines.
A key lesson, though, is that you should keep in mind memory capacity when doing an upgrade like this. You do not want a system with 128 cores and 256GB of memory, for example, since CPU cores will become stranded resources. On these small VMs, we see the 128-core CPUs perform better than two of the Intel Xeon Gold 6252 servers, so this is where the 4:1 and greater consolidation comes into play.
Next, let us get to power consumption.
2nd Gen Intel Xeon to 5th Gen Intel Xeon Power Consumption
We took our two Supermicro servers and did a quick head-to-head on the power consumption side.
Idle power consumption was generally in the 80-100W for the 2nd Gen Intel Xeon system, which was fairly similar to our single socket AMD EPYC 9754 system that was in the 90-120W range. Under load, the older systems would often run at 600W-700W maximum, while a single socket AMD EPYC 9754 system would not breach 500W.
This is where things get weird. The AMD EPYC 9754 single socket has performance in the 3-5x or so performance per socket. At the same time, comparing dual socket mainstream 2019-2021 system to the new cloud-native system offers a decrease in total power consumption. We are seeing somewhere between 29-50% of the power to achieve that performance.
When we talk about consolidation, it is possible to take five dual-socket Xeon Gold 6252 servers and consolidate them into a single dual AMD EPYC 9754 server. That can save 80% of the rack space, and up to 2.5kW of power. It is almost mind-boggling.
Next, let us get to key lessons learned.



{kind=link}
The vast majority of companies who used Scalable Gen 1 or 2 moved on to Ice Lake and Likely Sapphire Rapids by now – but the only way AMD can come out on top is to compare something they haven’t released vs something Intel released years ago.
AMD cannot feed 64 cores much less 128.
I used Gen 1 which led to Ice Lake which led to Sapphire Rapids – which is the path many organizations did.
With AMD’s launch schedule (Launch, with actual hardware months later – like how Mi300 was never mentioned as an AI processor until it shipped 9 months later and is now magically AI focused) Bergamo is a year out at least.
If AMD was so superior then they would not be sitting in single digits in the DC.
@Truth+Teller: the fact that intel DC business isn’t making money despite having 70% of the market is even more damning. It suggests that they are unable to demand a premium for their products. AMDs DC operation has been profitable for the last couple of years, growing both revenue and margins. It Does not need sherlock holmes to deduce what is going on.
I’ll mention first that this is the best article I’ve seen on the cloud native subject. I wish you’d done a video of it too.
My concern with Bergamo is that it isn’t much cheaper than Genoa or Genoa-X, but you know you’re getting less performance per core. You’re losing performance but you’re getting what 33% more cores in a socket? I don’t think that is enough of a gap. AMD needs to be offering twice the cores for cloud native to wow people into switching.
I think you’re earlier coverage of Sierra is also right that customers won’t jump on the first gen of a new CPU line like this. You’ve also nailed the most important metric for those who will switch, how many NVIDIA H100 systems it allows you to add.
I’m just commenting that I’m agreeing with Hans. I’d also say this is hands down the best Bergamo cloud native explanation I’ve ever seen and that 15 3 1 example is perfect for what we need. We’re probably going to order Supermicro H200 servers because STH seems to think they’ve got the best and they’re the only ones with a history of reviewing every gen.
AMD could buy STH for $M’s just to use this article and the ROI’d be silly. You’ve just done something AMD’s marketing’s been trying to push on OEM partners and turned it from “who tf cares?” to something we’re putting on our staff meeting tomorrow.
@Truth+Teller: in order of your assertions, you’re probably wrong, wrong as this article has a picture of all 128 cores 100% loaded, can’t say, somewhat right but that’s due to demand not the products coming out late and definitely wrong as their DC market share is definitely double digits.
“”Truth” Teller another paid Intel shill boy……makes Bagdad Bob look like an amateur :-) and oh Bergamo has been in ample supply for quarters now and many customers had it that long already or longer,
Great analysis.
Truth+Teller your assessment is full of baloney. First most companies outside of places like AWS didn’t go from Gen 1 > Gen 2 > Gen 3 Xeon as that was a huge cost with minimal upside. The only benefit was getting onto Gen 3 or later as you could add more RAM without needing the L series CPUs. However, if you already had those well it didn’t make much sense. Secondly AMD Bergamo has been available for a long time now. I can go on Dell’s website right now and purchase a brand new system with Bergamo in it. Therefore it isn’t “a year out at least.” Also they can feed that many mores. There is a reason they went to 12 channel DDR5 RAM. A single socket now has more bandwidth than a dual socket from the DDR4 era.
Are companies even looking for consolidation? I’d think most datacenters have more problems with power and cooling than available rack space. Of course having CPUs that deliver what general purpose applications need instead of focusing on AI boondoggles to woo shareholders is always appreciated. Most of the newer instruction sets are barely used.