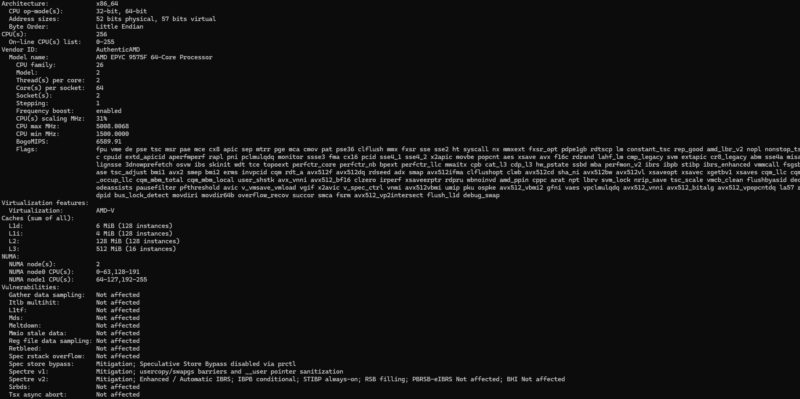
5th Gen AMD EPYC 9005 Performance
For this, we had the AMD Volcano dual socket platform with three sets of CPUs and had around a week to run though everything.
That is rough. Still, here is the big one, the AMD EPYC 9965.
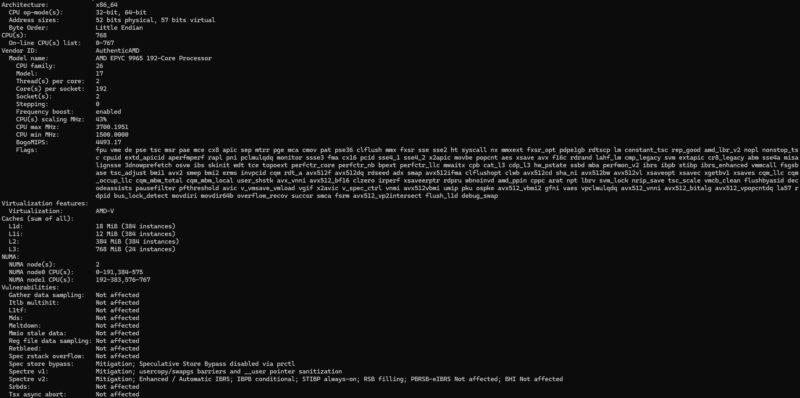
Here is the 768 thread, 1.5TB core complex.
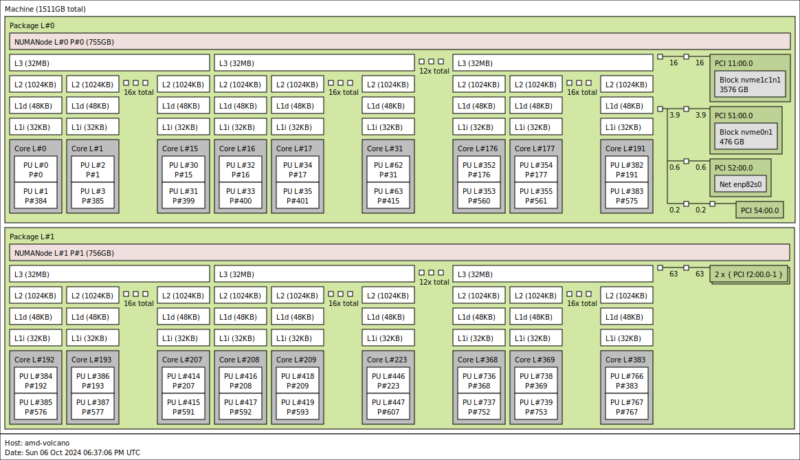
Here is the AMD EPYC 9755:
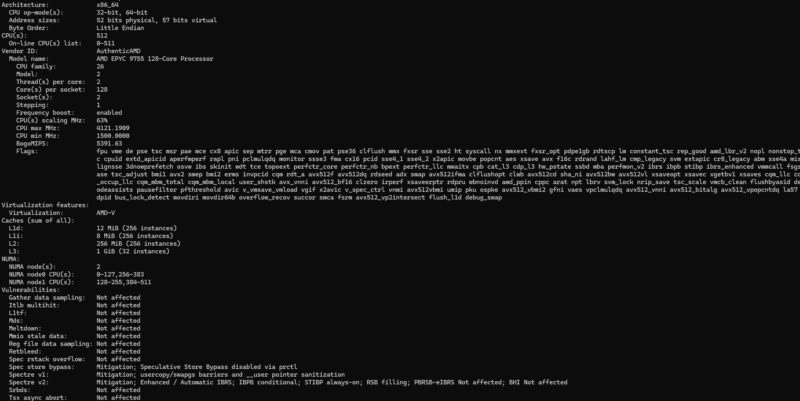
Here is the topology with 512 cores:
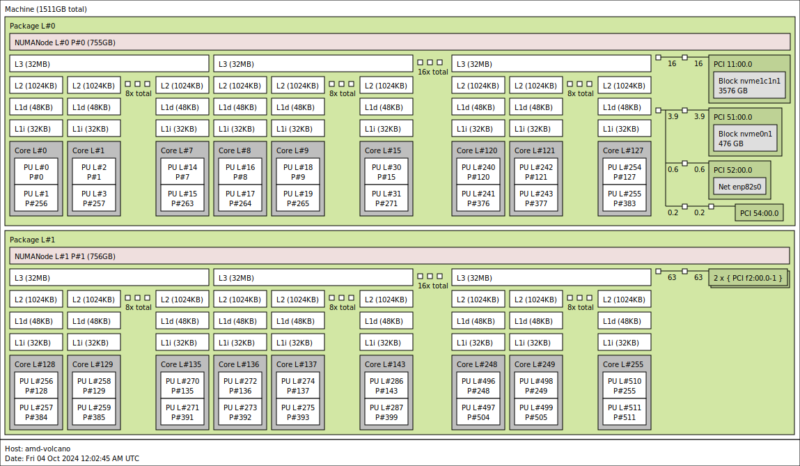
Here is the AMD EPYC 9575F:
Here is the topology of the 128 core/ 256 thread setup of the high-frequency AMD EPYC 9575F:
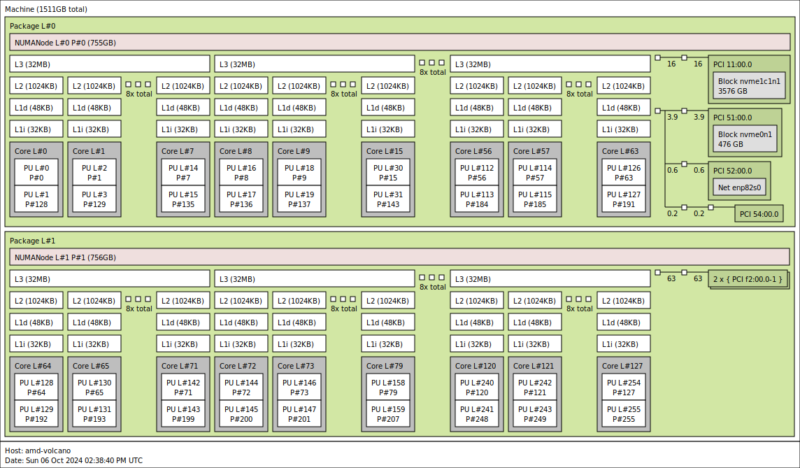
We are now in an era where we just have a lot of threads and cache in these systems.
Python Linux 4.4.2 Kernel Compile Benchmark
This is one of the most requested benchmarks for STH over the past few years. The task was simple: we had a standard configuration file, the Linux 4.4.2 kernel from kernel.org, and made the standard auto-generated configuration utilizing every thread in the system. We are expressing results in terms of compiles per hour to make the results easier to read.
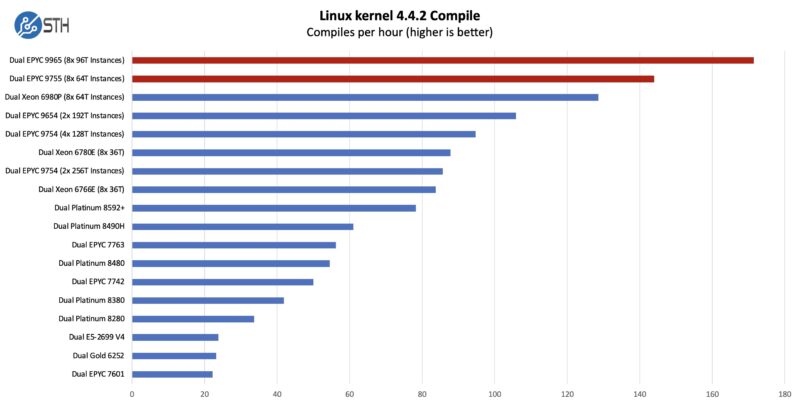
Compile benchmarks we have had to split because short single-threaded bursts stall performance too much. We started splitting into multiple instances in 2023. We are going to have to move this to a tiled workload soon.
c-ray 1.1 Performance
We have been using c-ray for our performance testing for years now. It is a ray tracing benchmark that is extremely popular for showing differences in processors under multi-threaded workloads. Here are the 8K results:
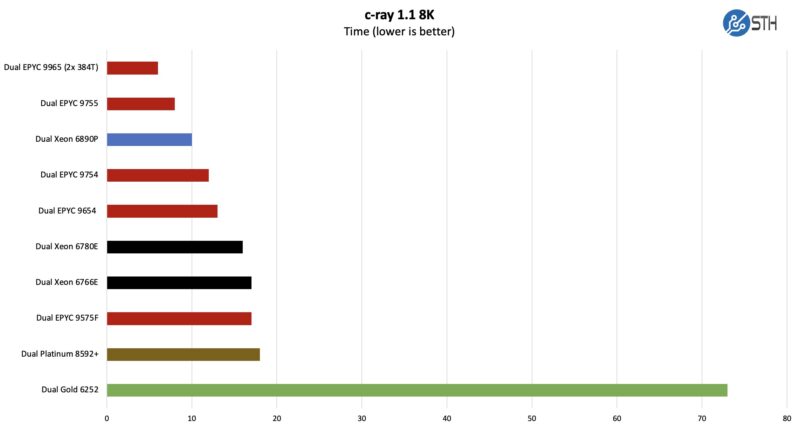
We have this solely because it is a fun one. We developed this benchmark years ago and it would take a 4-socket Xeon E5 server so long to run that we could take a coffee break. Now, we are having to split it up. We are losing resolution here. This workload, similar to Cinebench on the desktop side, runs very well in the AMD Zen caches.
The bottom line is we need much larger workloads for modern CPUs, especially if trying to run them across full CPUs. We are at 768 threads in a single server now, and that is a path unlikely to reverse. These workloads are also less sensitive to the platform components which we have seen is a bigger area of focus today.
STH nginx CDN Performance
On the nginx CDN test, we are using an old snapshot and access patterns from the STH website, with DRAM caching disabled, to show what the performance looks like fetching data from disks. This requires low latency nginx operation but an additional step of low-latency I/O access, which makes it interesting at a server level. Here is a quick look at the distribution:
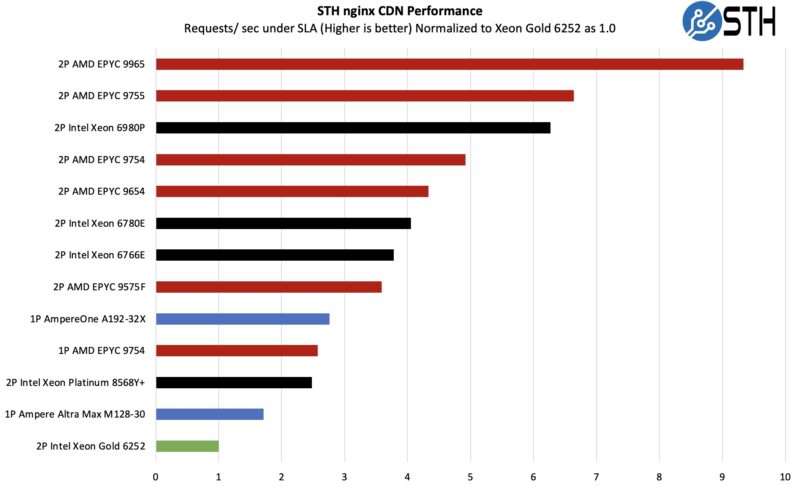
AMD is leading here on raw CPU performance. We must mention we are not using Intel QAT for OpenSSL offload here, which changes things. This is just raw CPU performance. Also, this workload showed a notable increase from using a faster SSD and a huge increase from using faster networking. That makes sense since a lot of hitting the SLA is throughput-based. At the same time, with platform changes a 9:1 consolidation ratio over common 2nd Gen Xeon Scalable parts is huge. We are now in an era where a single server can likely service web traffic for any website outside of the top 10,000 worldwide.
MariaDB Pricing Analytics
This is a very interesting one for me personally. The origin of this test is that we have a workload that runs deal management pricing analytics on a set of data that has been anonymized from a major data center OEM. The application effectively looks for pricing trends across product lines, regions, and channels to determine good deal/ bad deal guidance based on market trends to inform real-time BOM configurations. If this seems very specific, the big difference between this and something deployed at a major vendor is the data we are using. This is the kind of application that has moved to AI inference methodologies, but it is a great real-world example of something a business may run in the cloud.
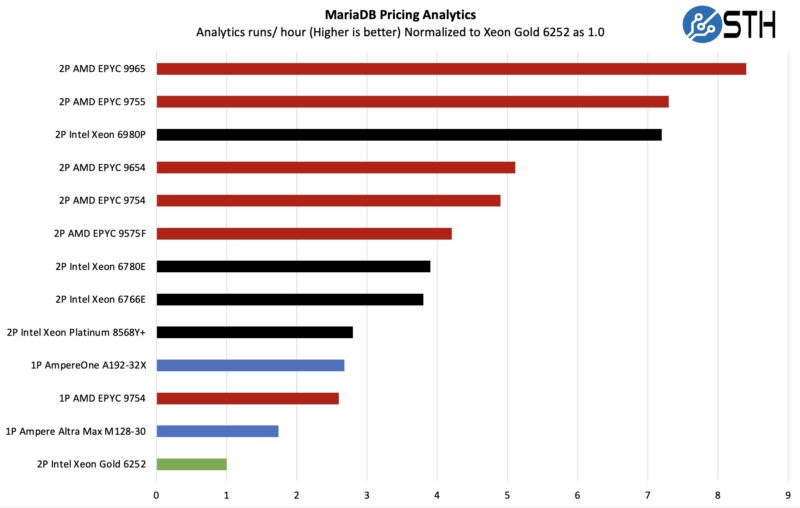
For this workload, AMD does very well. Again, we are going to refer to what we found by switching the SSDs and NICs. Here, the other one to look at is the AMD EPYC 9575F that is using high frequency to push its 64 cores notably past 144 core Sierra Forest and surprisingly closer to Zen 4 high core count generation parts.
STH STFB KVM Virtualization Testing
One of the other workloads we wanted to share is from one of our DemoEval customers. We have permission to publish the results, but the application being tested is closed source. This is a KVM virtualization-based workload where our client is testing how many VMs it can have online at a given time while completing work under the target SLA. Each VM is a self-contained worker. This is very akin to a VMware VMark in terms of what it is doing, just using KVM to be more general.
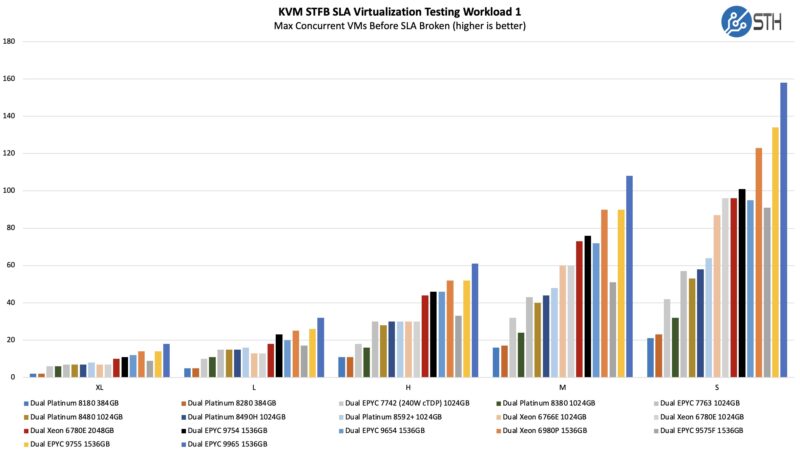
Here, more cores are better, but it is also sensitive to clock speed and memory bandwidth (and capacity.) The AMD EPYC 9965 is the chip you want if you are running a modern open source virtualization platform. It offers enormous consolidation opportunities.
Another important note here is that if you are paying for 16 core or 32 core per socket licenses, it is going to be costly to get this level of consolidation. AMD has frequency-optimized parts for those markets, but people will build ROI models on shifting towards open-source virtualization if they can get 6x the per-socket density.
Additional AMD Performance Slides
Three sets of CPUs with benchmarks that can take a long time, and only seven days was rough. At the same time, we have some of our unique workloads which we focused on since they add something net-new. Still, we did not get to everything just due to time. AMD had a few slides, including its AI performance (note this is usually highly dependent on setup.)
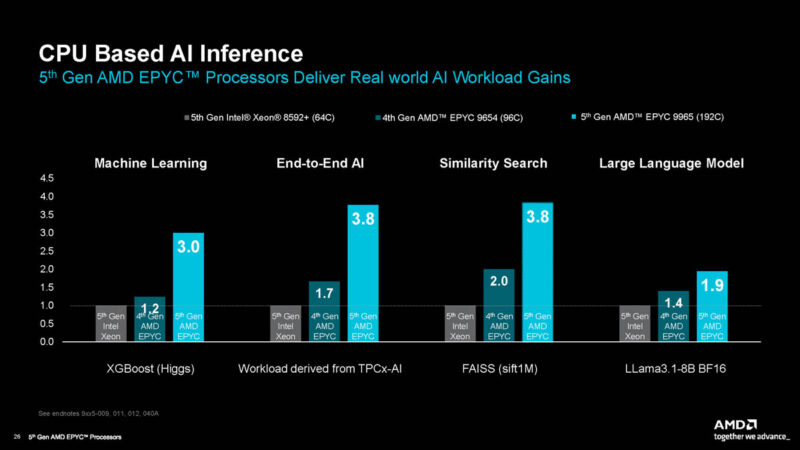
AMD also had common open-source HPC workload performance figures.
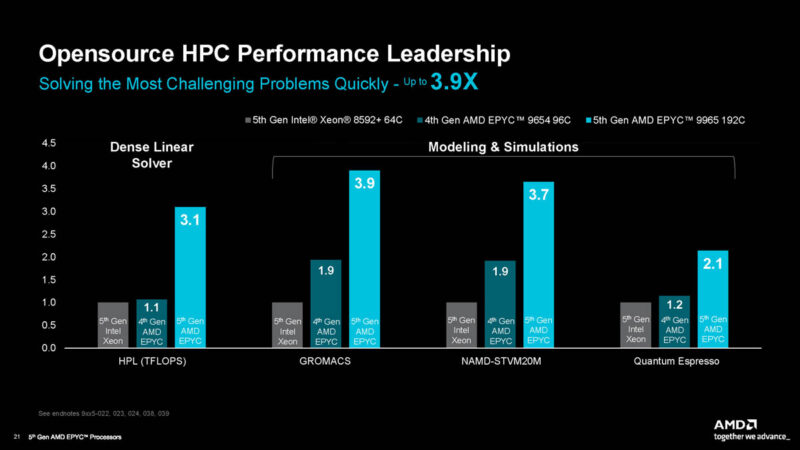
AMD also had some of the licensed enterprise HPC workloads.
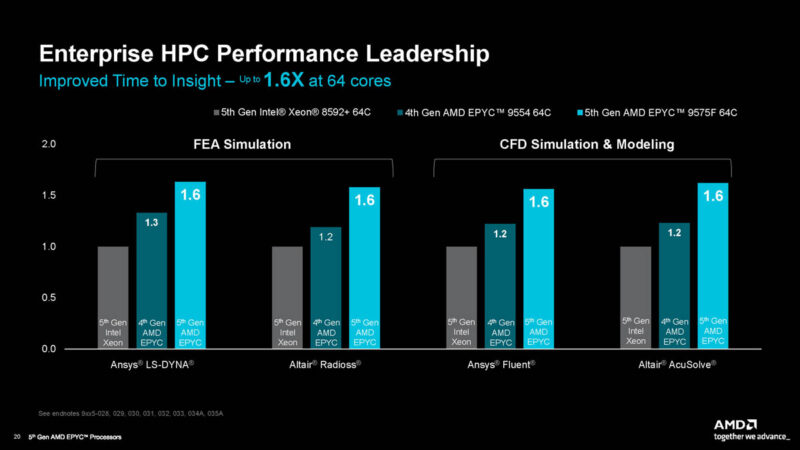
AMD, of course, has many metrics that it performs very well with. At the same time, it is picking some advantageous comparison points here.
Next, let us talk about the memory speeds.



{kind=link}
I’ve come to rely on your cross-generational SKU stacks — hope you get that updated with these new CPUs!
Smart Data Cache Injection (SDCI) which allows direct insertion of data from I/O devices into L3 cache could be a huge gain for low latency network IO workloads. It’s similar to Intel’s Data Direct I/O (DDIO).
There’s great chips here! AMD engineers doing great things.
9965 what a time to be alive
Fascinating to finally see something that hits the limits of x4 PCIe4 SSDs in practice.
768 threads in a server & benchmarks… for a fun test you could run a CPU rendered 3D FPS game. IIRC there is a cpu version of Crysis out there somewhere.
i have a few questions_
Why does the client needs so many vms to run a workload instead of using containers and drastically reduce overhead?
Second question: can you go buy a 9175f and test that one with gaming?
I’m surprised you perform benchmarks on such 2P system with NPS=1 and “L3 as Numa Domain” turned off.
Such a processor deserved an NPS=4 + L3_LLC=On to let the Linux kernel do proper scheduling.