Removing Bottlenecks with HUGE CPUs
Something that we need to call out here is something we expect to see from everyone reviewing the platform today. We saw significant bottlenecks elsewhere in the system once we hit 192 cores per socket. We have been running many of our workloads so long, that we have a decent idea of how they should perform. With 128 and 192 cores we started to see an impact by swapping out our normal PCIe Gen4 NVMe SSDs for newer generation PCIe Gen5 drives. We had a few of the new Solidigm D7-PS1010 drives in the lab, and since they are new and fast we decided to do a quick generational comparison.

At 64 cores running our nginx workload, we did not see a huge benefit to the new drives. By the time we got to the AMD EPYC 9965, we were over 8% better performance.
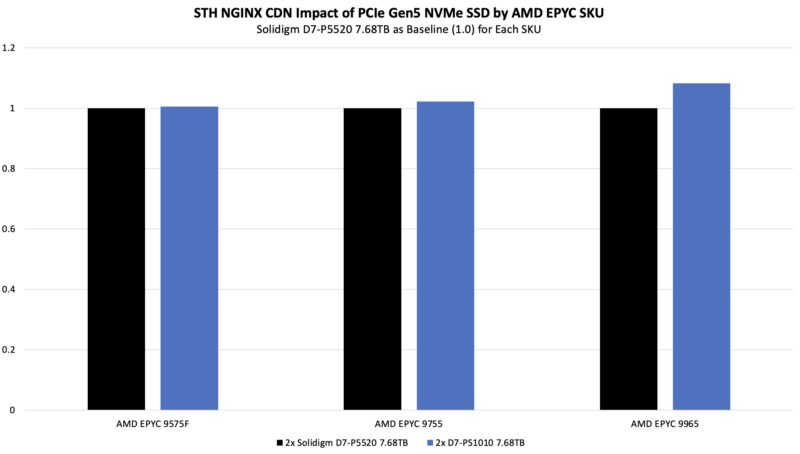
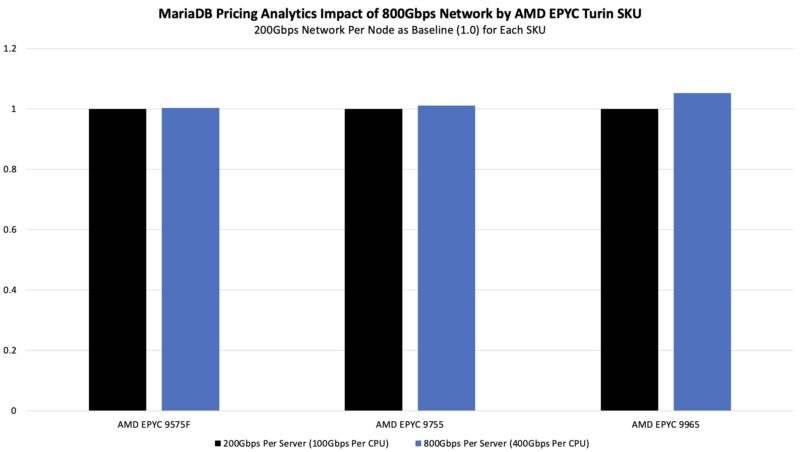
On our pricing analytics workload, we saw slightly better performance especially at 192 cores:
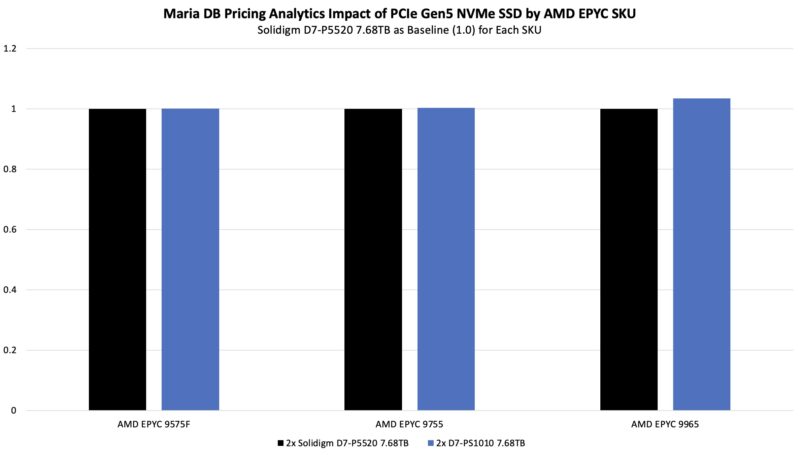
That may not seem like a lot, but using a newer generation of drives effectively gave us a performance benefit similar to adding 5-19 cores. That is a huge deal.
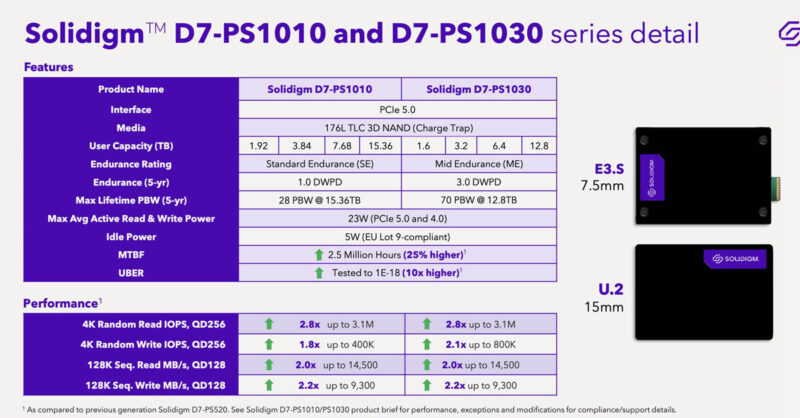
We grabbed these drives because we knew that they were new and very fast. Still, the high core-count CPUs are really showing bottlenecks where we might not have seen them previously.
Something similar happened on the networking side. After seeing the storage change, we thought that new faster CPUs with 192 cores might need more networking than just one 100GbE link per CPU. Since we have the new Broadcom 400GbE NICs, we installed them in the AMD Volcano platform.

Unfortunately, we only had one of each card, but we could get a total of 400Gbps on each CPU (1x 400GbE and 2x 200GbE.) Not perfect, but it is what we had.

As we would imagine, hitting our SLA on the STH nginx CDN benchmark was easier with faster networking.
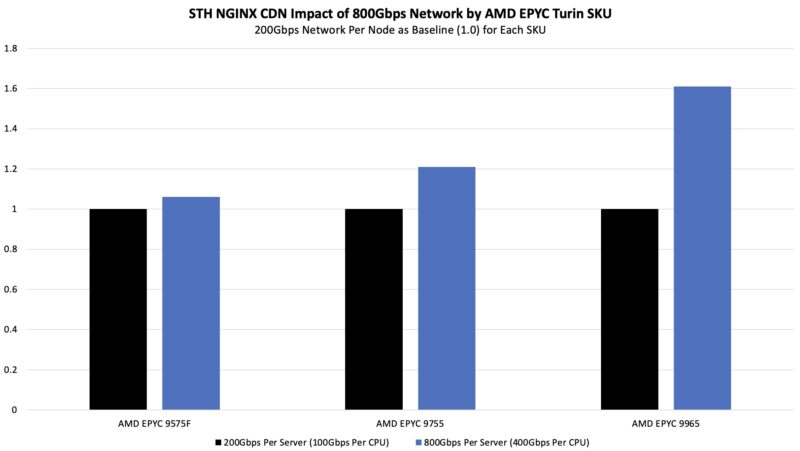
We saw a smaller impact on the pricing analytics side.
These NICs are also relatively low power and more power efficient on a pJ/bit basis than the 100GbE ConnectX-6 NICs we often use in the lab.

This was cool to be able to show, but it was also a bit frustrating. We only had a limited amount of time with the system, and three sets of CPUs to test, so finding something like this put us behind. On the other hand, it is a really valuable insight, and probably a step beyond the “more cores = more better” message that we would have expected with this review.
We also used the NVIDIA BlueField-3 DPUs and ConnectX-7 cards to generate traffic.

Thank you to NVIDIA for sending its NVIDIA BlueField-3 DPUs and ConnectX-7 cards, which we have featured a few times and used here to provide additional network throughput. These are very high-end cards and a step up from the 100Gbps NICs we had been using.
Let us next get to performance.



{kind=link}
I’ve come to rely on your cross-generational SKU stacks — hope you get that updated with these new CPUs!
Smart Data Cache Injection (SDCI) which allows direct insertion of data from I/O devices into L3 cache could be a huge gain for low latency network IO workloads. It’s similar to Intel’s Data Direct I/O (DDIO).
There’s great chips here! AMD engineers doing great things.
9965 what a time to be alive
Fascinating to finally see something that hits the limits of x4 PCIe4 SSDs in practice.
768 threads in a server & benchmarks… for a fun test you could run a CPU rendered 3D FPS game. IIRC there is a cpu version of Crysis out there somewhere.
i have a few questions_
Why does the client needs so many vms to run a workload instead of using containers and drastically reduce overhead?
Second question: can you go buy a 9175f and test that one with gaming?
I’m surprised you perform benchmarks on such 2P system with NPS=1 and “L3 as Numa Domain” turned off.
Such a processor deserved an NPS=4 + L3_LLC=On to let the Linux kernel do proper scheduling.