AMD EPYC 7351P Benchmarks
For this exercise, we are using our legacy Linux-Bench scripts which help us see cross-platform “least common denominator” results we have been using for years as well as several results from our updated Linux-Bench2 scripts. At this point, our benchmarking sessions take days to run and we are generating well over a thousand data points. We are also running workloads for software companies that want to see how their software works on the latest hardware. As a result, this is a small sample of the data we are collecting and can share publicly. Our position is always that we are happy to provide some free data but we also have services to let companies run their own workloads in our lab, such as with our DemoEval service. What we do provide is an extremely controlled environment where we know every step is exactly the same and each run is done in a real-world data center, not a test bench.
Python Linux 4.4.2 Kernel Compile Benchmark
This is one of the most requested benchmarks for STH over the past few years. The task was simple, we have a standard configuration file, the Linux 4.4.2 kernel from kernel.org, and make the standard auto-generated configuration utilizing every thread in the system. We are expressing results in terms of compiles per hour to make the results easier to read.
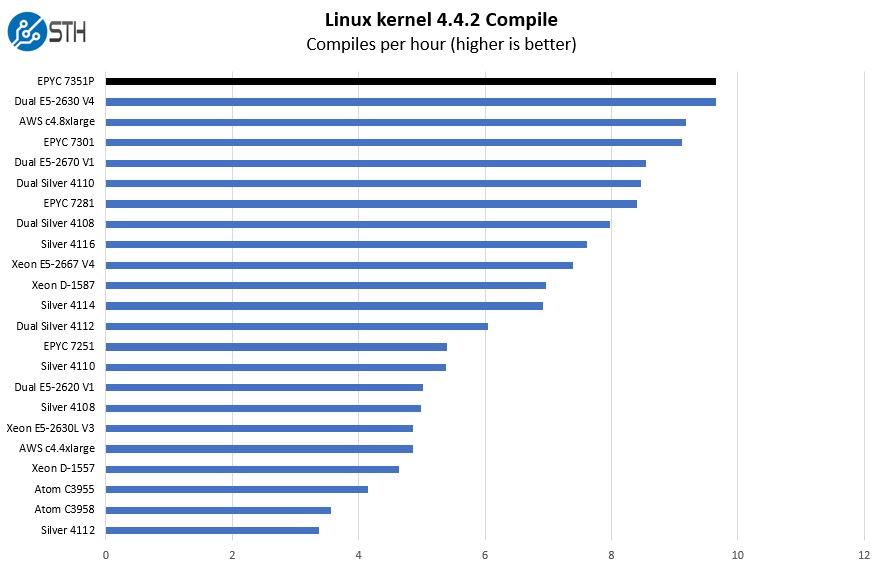
Here you can see a strong showing from the EPYC 7351P which is going to be a recurring theme. There are a few points to note, first the single socket EPYC 7351P a sub $800 CPU compares very favorably to a $1.591/ hour AWS c4.8xlarge instance as well as much of the E5 lines. Furthermore, we are seeing AMD deliver on its promise of the “P” series single socket parts being able to go head-to-head with the lower-end dual socket parts from Intel both in V4 and the Xeon Silver range.
c-ray 1.1 Performance
We have been using c-ray for our performance testing for years now. It is a ray tracing benchmark that is extremely popular to show differences in processors under multi-threaded workloads.
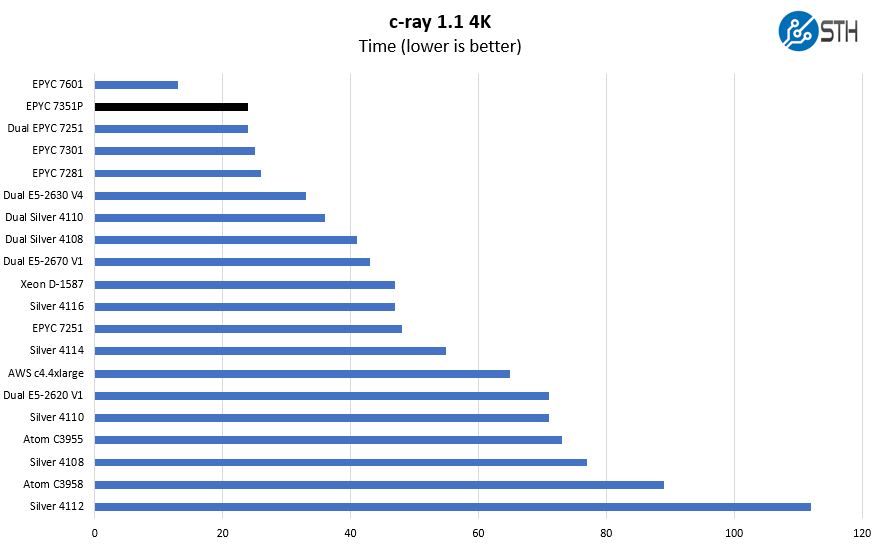
Benchmarks like c-ray (and Cinebench R15 for Windows) are very sensitive to microarchitectures. They are probably not the best benchmarks to use to compare AMD v. Intel, and often not Intel to Intel across major generations. Still we wanted to provide figures using our legacy c-ray 1.1 test.
As we saw when we actually broke Cinebench R15 using quad Intel Xeon Platinum 8180 CPUs, if you need to generate a lot of threads, you often need a longer benchmark or thread generation becomes a limiting factor. At the higher-end of AMD EPYC and Xeon Gold and Platinum, this becomes a significant consideration. As a result, we started building a more complicated render we are dubbing 8K to give us longer render run times. Here is what a few different EPYC options look like on the larger benchmark:
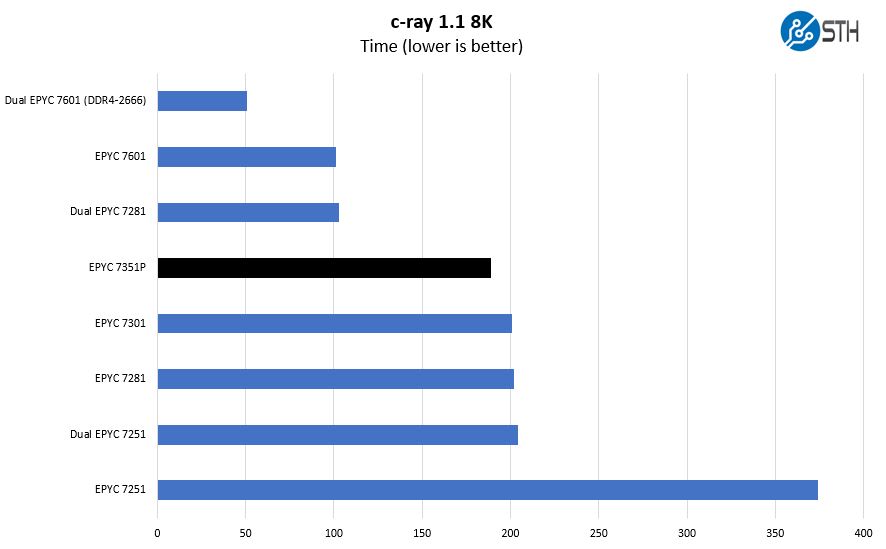
That is probably more EPYC configurations that anyone has put in a single chart to this point. For those wondering about the EPYC 7281 and EPYC 7301, c-ray is not hitting L3 cache. The EPYC 7301 has twice the EPYC 7281 cache which we will show the impacts of during that review. The simplicity of c-ray and Cinebench R15 hide the benefits from bigger L3 caches.
Interestingly enough, you can see on this chart some definite grouping between 8 core, 16 core, 32 core and 64 core offerings. The 24 core parts are finishing runs but we will have a full benchmark set in the next few days. The AMD EPYC 7601 we see as more of a niche part given its price tag while the EPYC 7200 and 7300 series parts are certainly more mainstream.
7-zip Compression Performance
7-zip is a widely used compression/ decompression program that works cross-platform. We started using the program during our early days with Windows testing. It is now part of Linux-Bench.
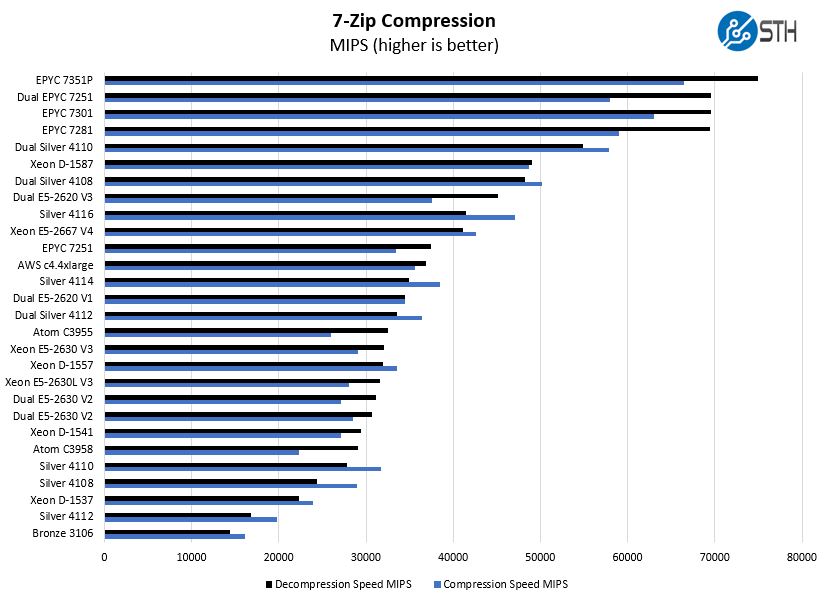
This is a crowded chart, but the raw core count is propelling the AMD EPYC 7351P to some awesome figures. To get above the AMD EPYC 7351P here requires dual Silver 4114 CPUs at nearly 2x the price.
NAMD Performance
NAMD is a molecular modeling benchmark developed by the Theoretical and Computational Biophysics Group in the Beckman Institute for Advanced Science and Technology at the University of Illinois at Urbana-Champaign. More information on the benchmark can be found here. We are going to augment this with GROMACS in the next-generation Linux-Bench in the near future. With GROMACS we have been working hard to support Intel’s Skylake AVX-512 and AVX2 supporting AMD Zen architecture. Here are the comparison results for the legacy data set:
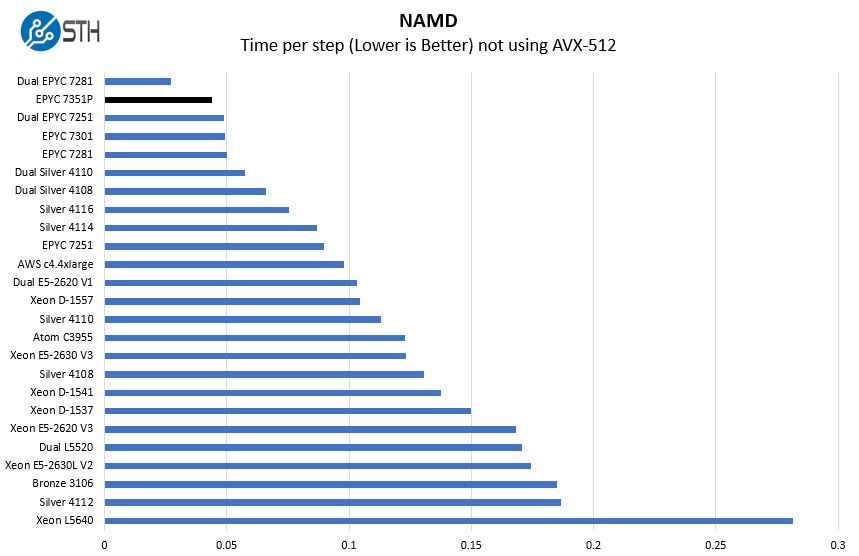
Although we are transitioning to GROMACS, we have a huge NAMD data set that is not optimized for AVX-512. We wanted to use both the dual EPYC 7251 and dual EPYC 7281 configurations here to show the power of the P series parts from AMD. By offering these single-socket specific CPUs, the AMD 7351P certainly allows one to use one socket instead of two.
Sysbench CPU test
Sysbench is another one of those widely used Linux benchmarks. We specifically are using the CPU test, not the OLTP test that we use for some storage testing.
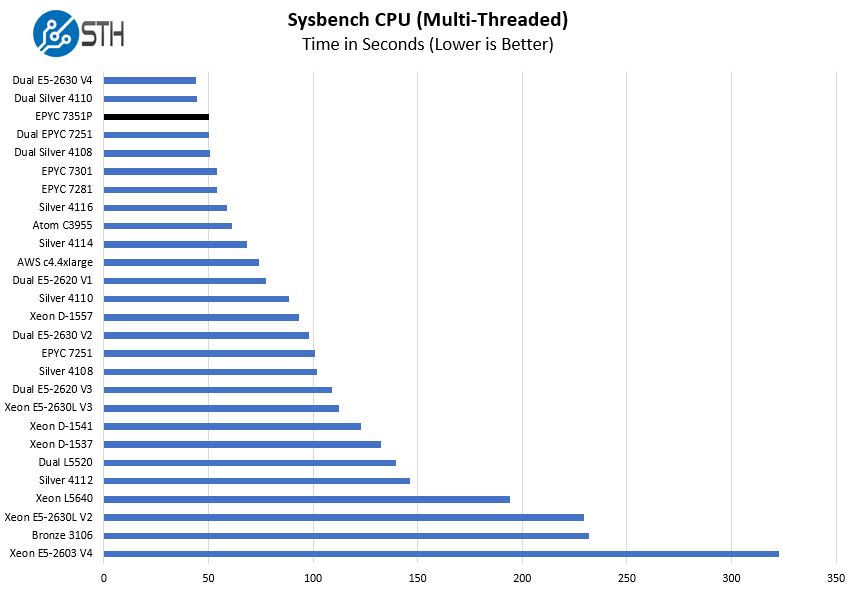
Here the AMD EPYC 7351P falls between the dual socket Intel Xeon Silver 4108 and Silver 4110 configurations. That is a stellar result given both are priced around the same as a single EPYC 7351P.
OpenSSL Performance
OpenSSL is widely used to secure communications between servers. This is an important protocol in many server stacks. We first look at our sign tests:
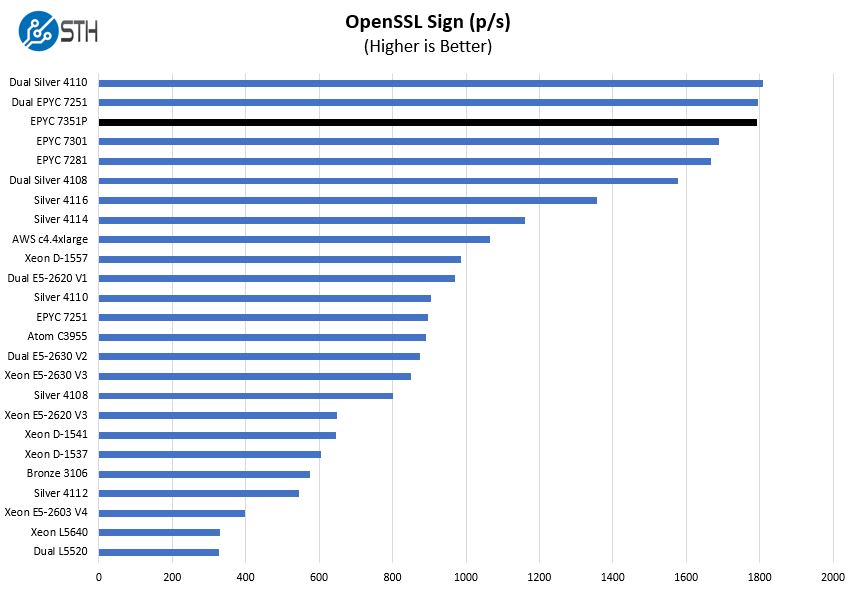
And the verify numbers:
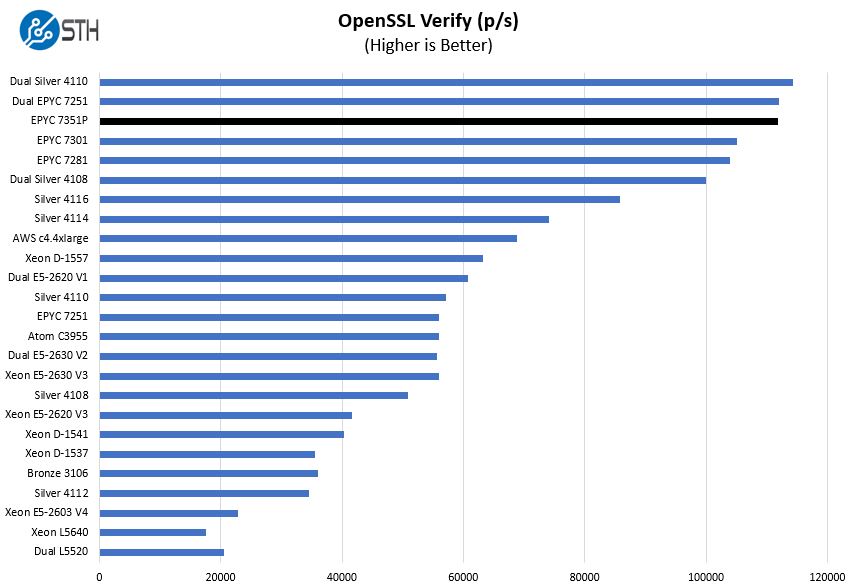
Again, we see the AMD EPYC 7351P performance shine here putting it near the dual Xeon Silver 4110. That certainly supports AMD’s value proposition on the P series parts. It is also why we are seeing so many vendors enter the market with AMD single-socket servers.
UnixBench Dhrystone 2 and Whetstone Benchmarks
Some of the longest-running tests at STH are the venerable UnixBench 5.1.3 Dhrystone 2 and Whetstone results. They are certainly aging, however, we constantly get requests for them, and many angry notes when we leave them out. UnixBench is widely used so we are including it in this data set. Here are the Dhrystone 2 results:
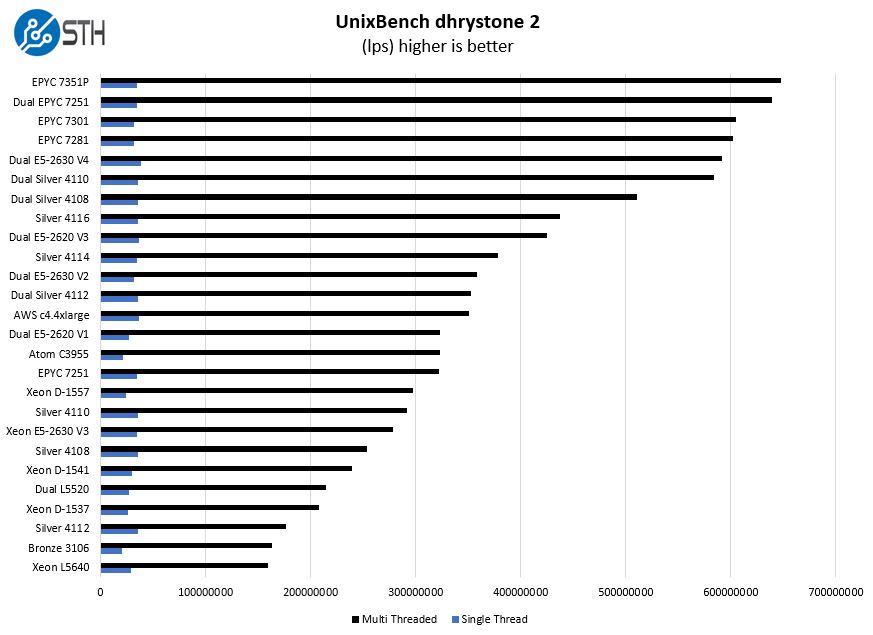
And the whetstone results:
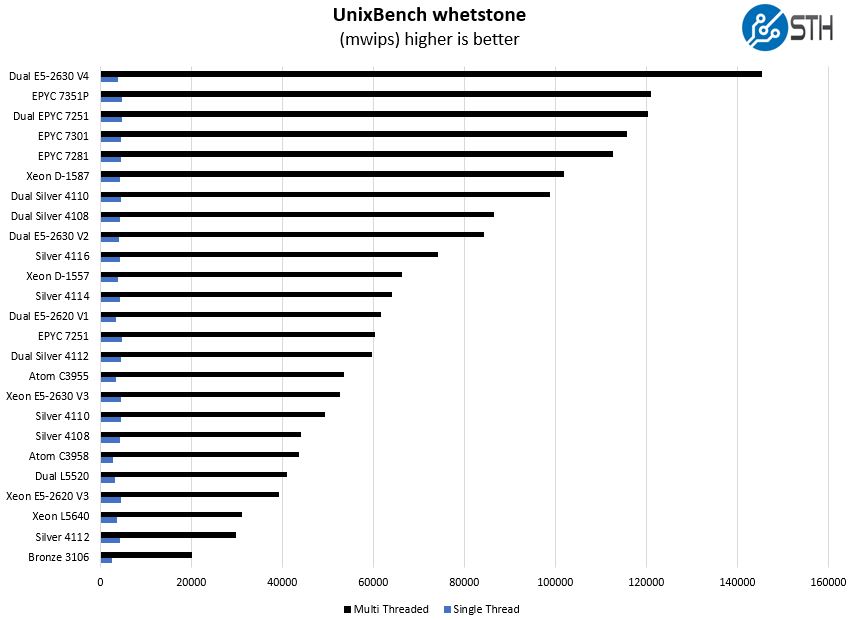
This is certainly an awesome showing for the AMD EPYC 7351P. Intel’s competitive single socket part (price wise) is the Xeon Silver 4114. Figures for that CPU are well below what we are seeing for the EPYC line.
GROMACS STH Small AVX2/ AVX-512 Enabled
We have a small GROMACS molecule simulation we previewed in the first AMD EPYC 7601 Linux benchmarks piece. In Linux-Bench2 we are using a “small” test for single and dual socket capable machines. Our medium test is more appropriate for higher-end dual and quad socket machines. Our GROMACS test will use the AVX-512 and AVX2 extensions if available.
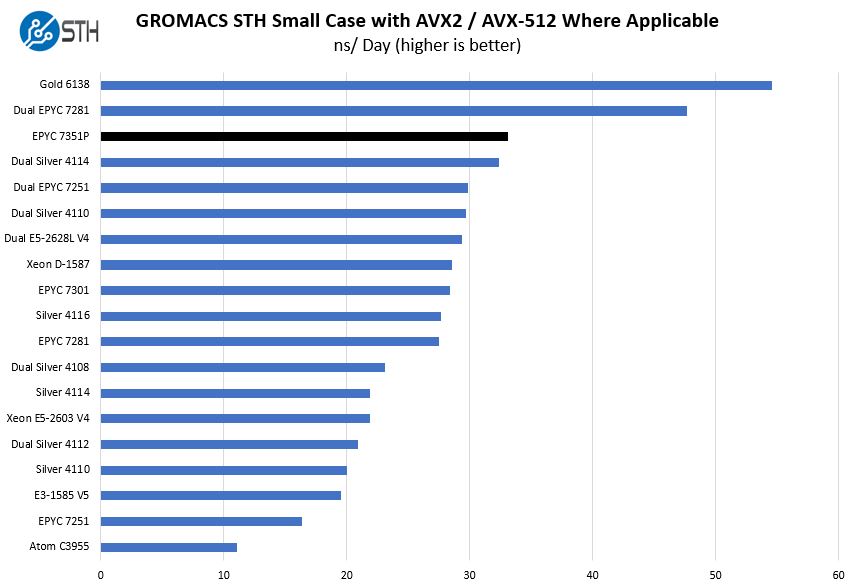
We added a few larger and more expensive configurations, namely the dual EPYC 7281 and single Xeon Gold 6138 results here to give some sense of perspective. Even though AVX-512 is a key feature for Intel Xeon Scalable, Intel made a product decision to neuter its effectiveness on the Xeon Silver line. It did so both by lowering clock speeds and removing the second compute unit. As a result, AMD EPYC supporting AVX2 not AVX-512 is able to keep pace even with Xeon Silver configurations that are 2x or more of the price.
Adding the lone Xeon Gold 6138 result here was simply to show how much the Xeon Gold 6100 and Platinum series CPUs benefit from higher clocks and AVX-512. Even the 14 core / 28 thread Xeon Gold 6132 will easily outpace the 16 core AMD EPYC 7351P by a wide margin. For that AVX-512 performance, the Xeon Gold 6132 costs almost 3x what an AMD EPYC 7351P does. From a system perspective, if you were doing heavy AVX-512 Intel still has a strong value proposition with their Xeon Gold series over AMD EPYC. With the product feature segmentation Intel does on the Xeon Silver line, it is simply not competitive.
Chess Benchmarking
Chess is an interesting use case since it has almost unlimited complexity. Over the years, we have received a number of requests to bring back chess benchmarking. We have been profiling systems and are ready to start sharing results:
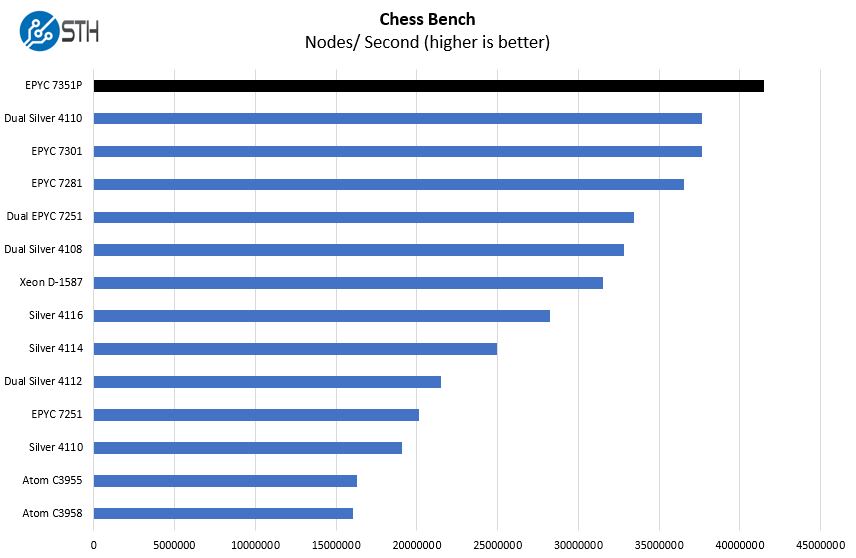
Lots of cores and higher clock speeds help the AMD EPYC here. In fact, the only EPYC that falls below the Intel Xeon Silver 4116, a $1000 part) in this workload is the AMD EPYC 7251 a $450 part.



{kind=link}
Great review.
Looking forward to a comparison between AVX512 and GPU.
GROMACS would be a perfect benchmark. When still availible with this very nice system https://www.servethehome.com/tyan-thunder-hx-ga88-b5631-server-review-4x-gpu-1u/
and/or DeepLearning 10/11
And again, great review.
I’m in IT procurement for a big F100 company in the US. We’re struggling with AMD to Intel now and our IT staff is trying to quantify for the business case. You may have done their jobs for them. +1+1 for the timely article. I’m emailing them this now
Great job AMD team.
Just what I needed. Your point on completeness is good. It’s also good that you’ve got a consistent setup and enviro for testing. We use SPEC06 for our purchases but it’s tough to use. You know it’s the OEM with the best tuning team getting the best results. I’m also sure that the OEMs have some special cooling that they’re using or something for their runs to get the best #’s. Having AMD and Intel H2H is a value to the IT community. Scripted + same rack = consistent. We know we’re buying nodes. This is helpful for gauging relative performance improvement.
3 ?’s:
— Ever consider using less stodgy lingo? It sounds like you’re a professor.
— You mention a larger data set. I can see you’re running more than you’re reporting here. Are you accepting inquiries to purchase an expanded set?
— Are these nodes going on DemoEval?
So for power draw.
7351P max load 340W?
Dual Xeon Silver 4110 under 200W?
The 2 seem to have same performance on some tests.
Is that correct?
Thank you.
@patrick Do you know if an Epyc P part will run fine as the single processor in a dual socket board? Or it must be installed on a single socket board?
I would like to see how these perform for workloads like medium sized databases (postgres / MySQL) compared to Intel, I suppose these kinds of workloads may suffer a lot more from NUMA than the ones in your testsuite.
Prosgres largely disk io bound, verdad?
That Tyan server looks amazing with all that NVMe connectivity, and the BCM5720 NIC with dual 1G RJ45. We are using the Silver 4110 in a lot of configurations, so I can see the EPYC P-processors as a good alternative, offering greater value, performance and connectivity. Often I go for single-socket, which is advantageous from a licensing perspective, but it often means a compromise on I/O.
From the article is mentioned “The AMD EPYC 7351P can handle 16x DDR4-2666 DIMMs (8 channel)”. In the presentations I have seen, EPYC only support DDR4-2666 with 1 DPC, and DDR4-2133 with 2 DPC. Has this been improved with microcode improvements similar to desktop Ryzen?
Could you post some benchmarks under Windows 10 Pro / Windows Server like Cinebench or FFmpeg? I think EPYC processors can be very useful for 3d content production and multimedia production. Thanks in advance and congrats for the reviews!
@Francesco F
I second that, but understand that Servethehome is focused on server benchmarks.
And yes EPYC is a wonderfull platform for a program like Davinci Resolve which runs mainly on GPU.
Staxrip is a good program to see how the multi-thread speed is (lot better than handbrake).
A stellar article read this morning. Thanks for doing Xeon D as well. Xeon D costs more for 16c but it’s got a miniscule tdp of 65w for 16c. Intel really needs some cheaper performance parts in the silver line. I’m all for low power but there’s no performance option in Silver or Bronze.
We don’t need every number but a good set of relative numbers is all we need. This hit the spot. I don’t like seeing places use geekbench or others with user submittals since ya never know how differ to the systems being tested are or if there’s something else running.
@Misha Engel
I understand, but some software like V-Ray (Cinebench test), Adobe Media Encoder (FFmpeg test) works primarily on CPU. STH have already done some Cinebench test in the past.
+Franchesco F don’t they have c-ray here and show Cinebench can’t handle high spec nodes in that linked article? Cinebench is worthless on servers now. I’m reading the words in the article and not comprehending your comment? Or you just want to see Cinebench and Windows on a CPU where Windows 10 Pro will occupy 0.00000000001% of the install base?
I’d like 24c results.
@WombatFool, so the guys that run RebusFarm (https://us.rebusfarm.net/en/company/render-farm-specs) or RenderRocket or FoxRenderFarm or Rescale or… they are just a bunch of fools? The 0.00000000001% as you said? I’ve just asked for one additional test, if it isn’t possible there is no problem at all.
Seems my reply get stuck, anyway well done, nice benchmarks!
Over at phoronix they also did some tests with numactl which essentially took a single 7601 epyc ahead of a dual 6137 gold server, which is quite impressive.
I really had high hopes for the new xeons but cutting away the avx units drove me to order some new broadwell nodes.
As soon as there is a quad node in 2U server for epyc available, we will switch to epyc.
@Tobias
As soon as there is a quad node in 2U server for epyc available, we will switch to epyc.
Hope AMD will give permission to the MOBO makers. Looking at this article https://www.servethehome.com/amd-epyc-infinity-fabric-update-mcm-cost-savings/ there is no reason not to come up with quad node version.
Wow this is the best. you’ve got so much comparison data for a site that isn’t aggregating user data. i’m seeing like every server cpu combo under $1K. i like the c3958 and c3955 and d-1567 too for other 16 core intel. it appears cheap by comparison. good job amd too on delivering cheap parts with cores and performance
@Misha
it seems like SuperMicro is working on something: H11DST-B
But it is too late for us this year. What was nice, even our distributor preferred the broadwell over the silver cpus.
Do you happen to know a good MKL alternative? I know ATLAS and openBLAS, but had no time to test it against MKL, the biggest problem will be a good fortran compiler, I guess IFORT still beats gfortran by a large margin
@Tobias
Thanks for the tip.
Fortran is a long time ago for me so can’t help you with that.
@Nino
It depends mostly on the size of the data set. If it fits completely in RAM then only writes are i/o bound, although this might be interesting by itself since of course I/O also suffers from NUMA, especially with fast NVMe drives.