
If you look at some AMD EPYC 7002 series “Rome” marketing material, you will see that there are four SKUs that are optimized for 4 channel memory configurations. These are the AMD EPYC 7282, AMD EPYC 7272, AMD EPYC 7252, and AMD EPYC 7232P parts. In our AMD EPYC 7232P Review, we briefly touched on the subject. Before we get to the other SKUs, we wanted to discuss what is going on, some thoughts around the why of the product, and some competitive context. It is at least somewhat strange we have not seen competitive marketing in this segment, and we are going to try discussing why.
One Slide on AMD Chiplet Design for Rome and Matisse
To understand what AMD is doing, one needs to gain an appreciation for AMD doing very modular chip design by current standards. This is AMD’s slide from Hot Chips 31 on how it designs its CPUs in modular pieces.
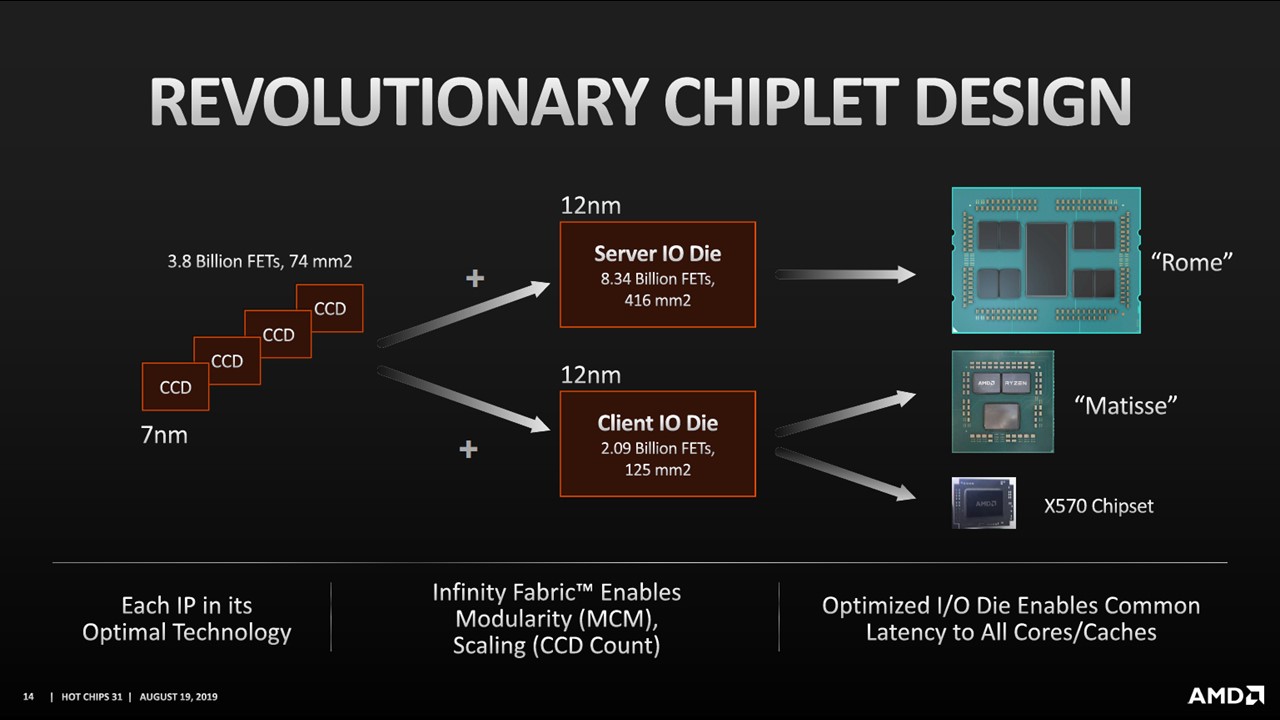
Essentially, AMD takes its x86 cores built using a 7nm process in what it calls CCDs. It then mates a number of those CCDs with either a server or client I/O die. That makes the AMD EPYC 7002 series “Rome” CPUs as well as the desktop Ryzen 3000 series. The I/O dies are so modular that AMD even uses a version of its client I/O die for its X570 chipset. The server I/O die does not have a chipset which saves on server platform BOM cost and power consumption versus current Intel Xeon Scalable CPUs.
As a quick note, if you would prefer to listen to this article in YouTube format:
Those I/O dies are responsible for many things, but the three we are going to care about here is connecting CCDs, DDR4 memory, and PCIe. On the EPYC side, we went into this in more detail if you read our AMD EPYC 7002 Series Rome Delivers a Knockout piece.
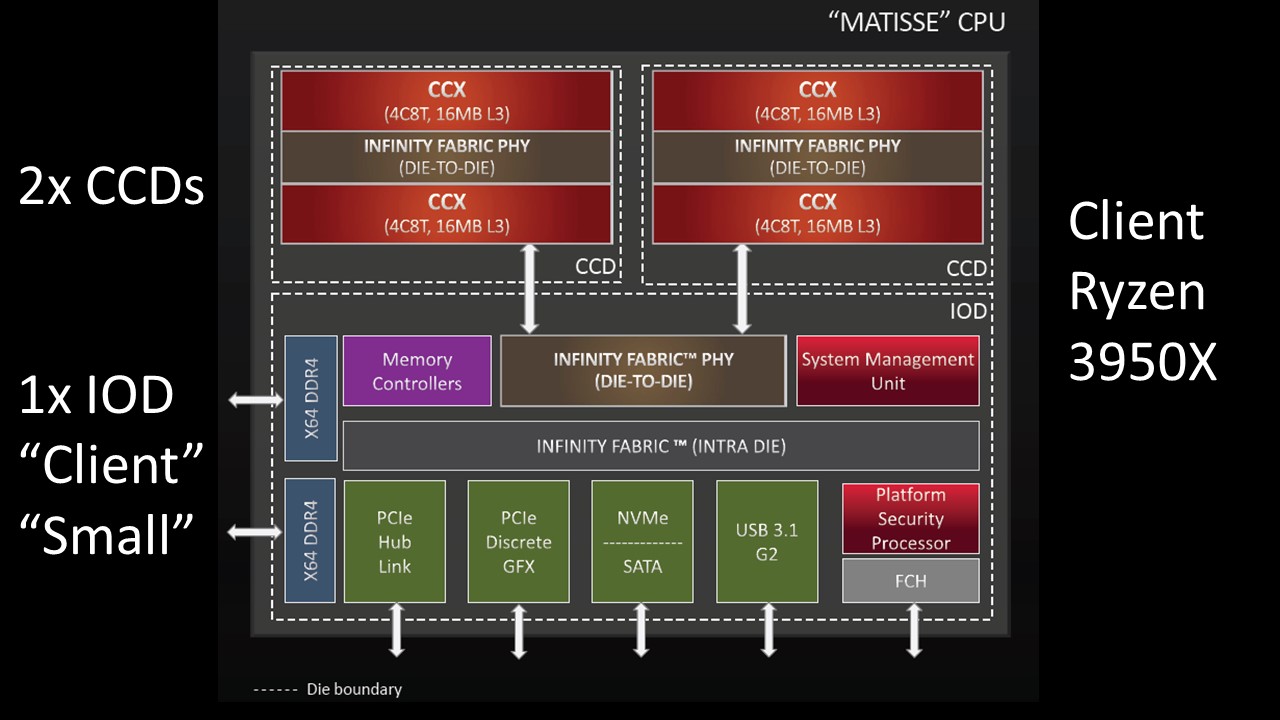
Using the AMD Ryzen 3950X as a fully-populated “Matisse” example, one can see we have two CCDs and one client IOD. That IOD connects the CCDs, two channels of DDR4 memory, and PCIe.
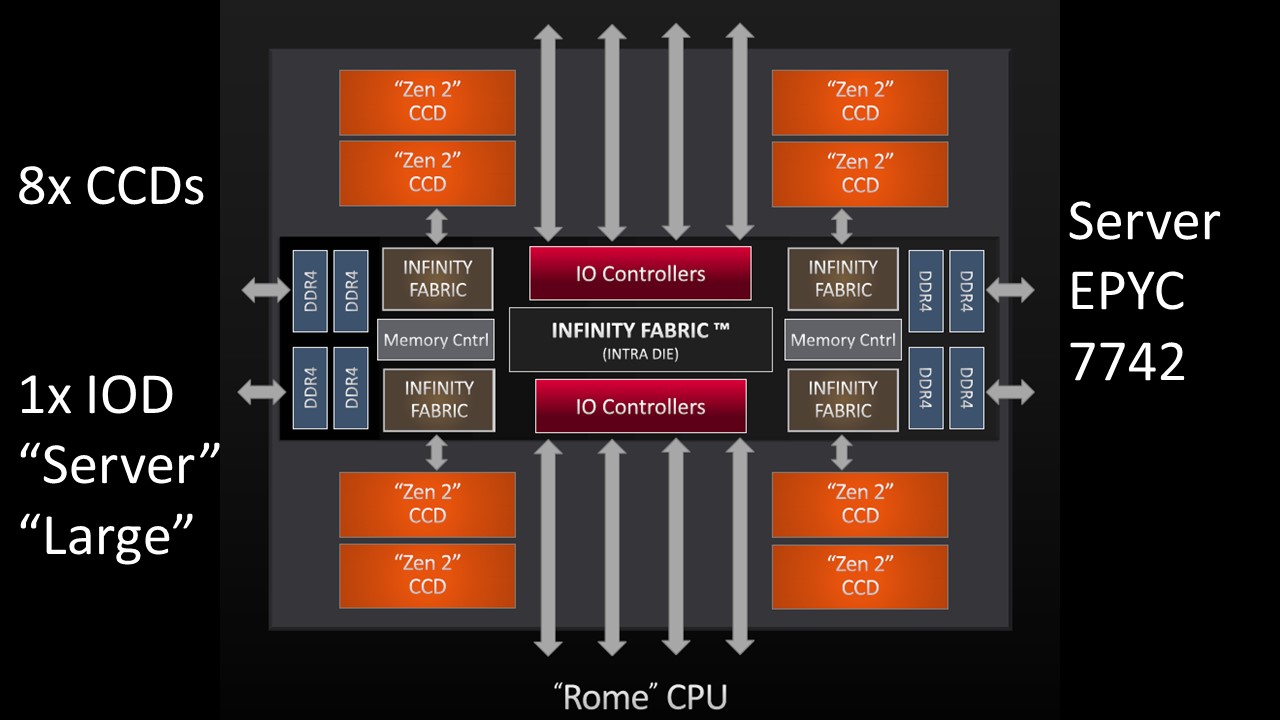
Turning to the AMD EPYC 7002 series “Rome” CPU, one can see a similar concept. The larger server IOD can connect eight of the CCDs, eight DDR4 memory channels, and PCIe Gen4 fabric/ or Infinity Fabric interconnect for dual-socket configurations.
A way we are going to use in this article to think about how these two AMD platforms relate is to think of a fully-populated EPYC 7002 series SKU, the AMD EPYC 7742 as somewhat analogous to four AMD Ryzen 3950X parts.
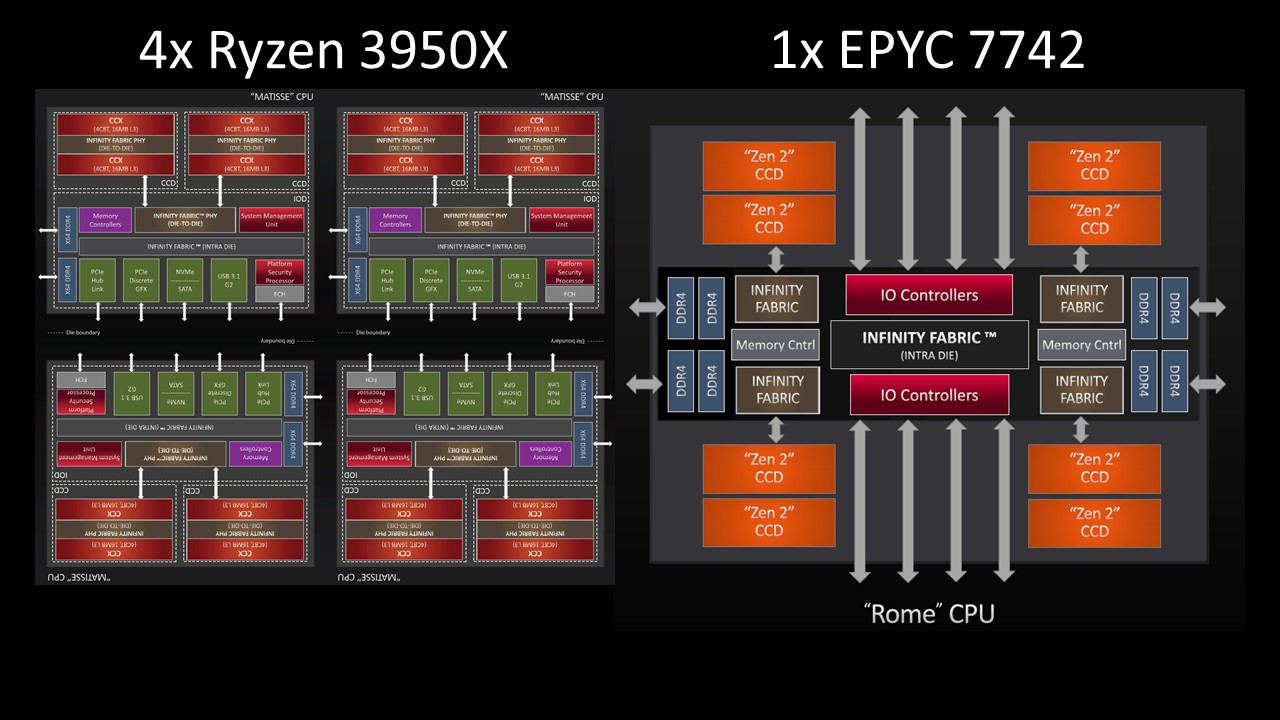
With four fully populated Matisse client packages, we have 2 CCDs per Ryzen 3950X x 4 = 8 CCDs total and 2 DDR4 channels per Ryzen 3950X x 4 = 8 DDR4 channels total.
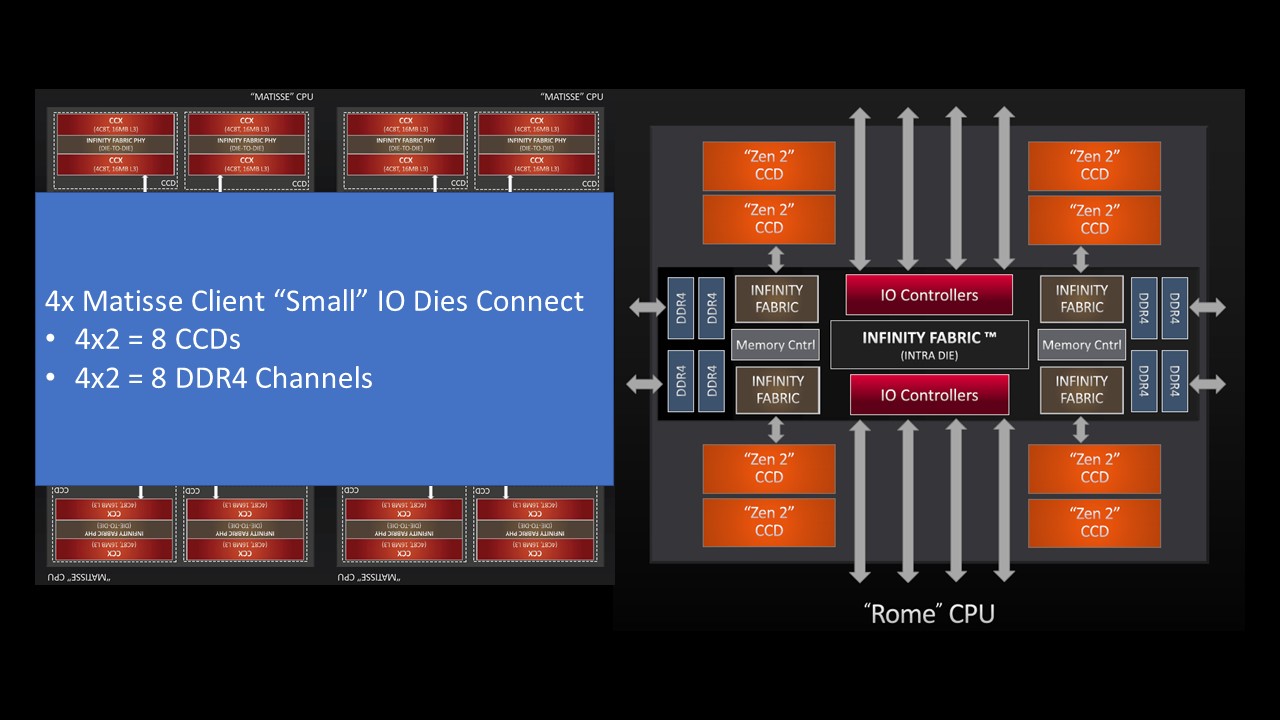
Coincidentally, on the larger server I/O die we find connectivity for eight DDR4 channels and eight CCDs.

We re-labeled the out of the package I/O lanes as DDR4 channels here, and are going to use that as a conceptual model for our discussion. If we think of the AMD EPYC 7002 series as four Ryzen 3000 Matisse client parts combined and optimized for servers, it helps to understand what is going on with the Rome parts optimized for 4-channel memory.
Apologies in advance to the AMD engineer(s) who are going to see this conceptual model and start to shake wanting to point out differences. We are using this to explain broadly what is going on, not the exact implementation detail.
4-Channel Optimized AMD EPYC 7002 Rome CPUs Technical Bits
Setting a bit of context here, all AMD EPYC 7002 series “Rome” CPUs have 8 memory channels that can run at up to DDR4-3200 speeds and utilize 2 DIMMs per channel. That means one can fill up to 16 DIMMs per socket, or 4 more than on current 2nd generation Intel Xeon Scalable processors, even the costly Intel Xeon Platinum 9200 series parts. This slide, however, does not take into account the lower-end SKUs exactly where we see this 4-channel memory optimization.

To understand what is going on, we need to take a look at how the AMD EPYC 7002 series is constructed. Here is a fully populated “Rome” package as one would see a 64 core model. We are going to call the somewhat Matisse equivalent portions Rome’s “Quadrants” with two CCDs and two DDR4 channels.
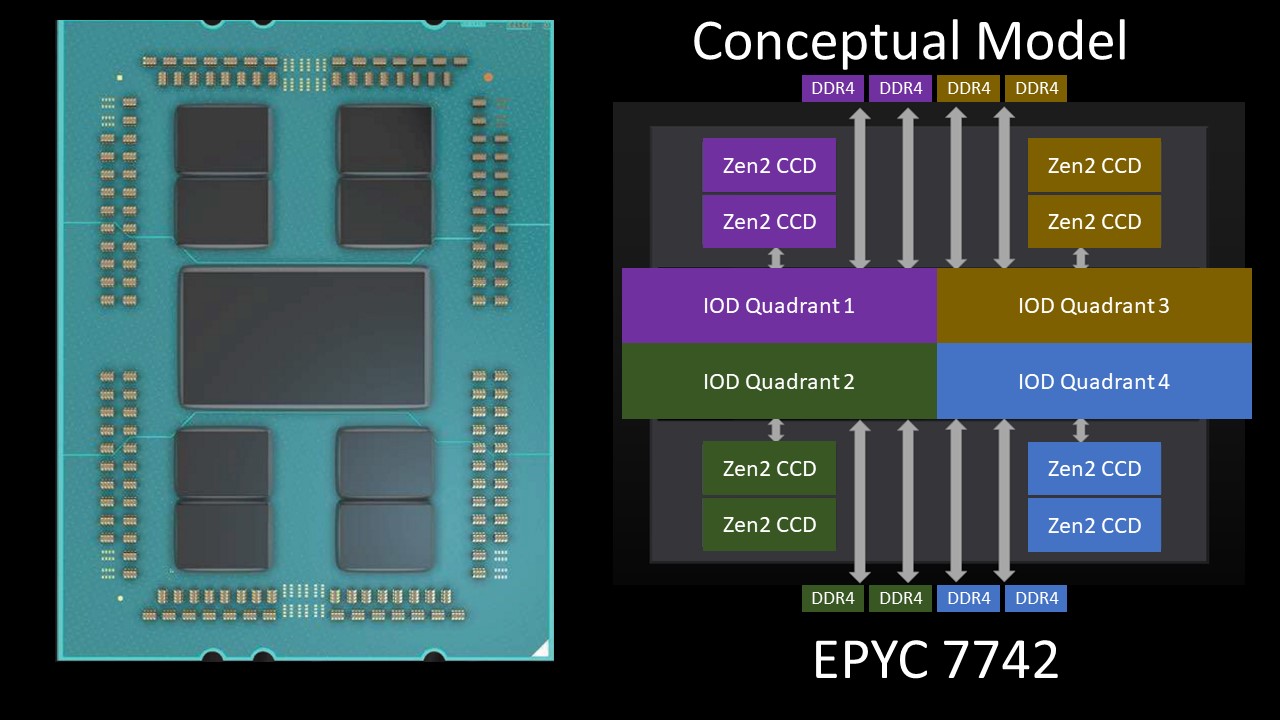
You will notice that there is a large central I/O die and eight CCD’s or the 7nm chiplets with up to 8 CPU cores each. Eight chiplets with 8 CPU cores each and we get to the maximum of 64 cores. If one had two cores per CCD inactive, one would then see 6 cores per chiplet or 48 cores.
When one gets to the lower-end 8, 12, and 16 core parts, this presents a challenge. AMD would need to populate all eight chiplets with dies that only have 1-2 cores active. Given the small size and relatively good yields of the 7nm chiplets, that is a challenge. The company would also have to go through the process of packaging nine dies for an 8 core CPU.
Instead of doing that, AMD essentially populates two active dies per Rome package on some of these lower-end SKUs. That helps keep costs down. Note, this is just a conceptual diagram, not actually where the CCDs are located.
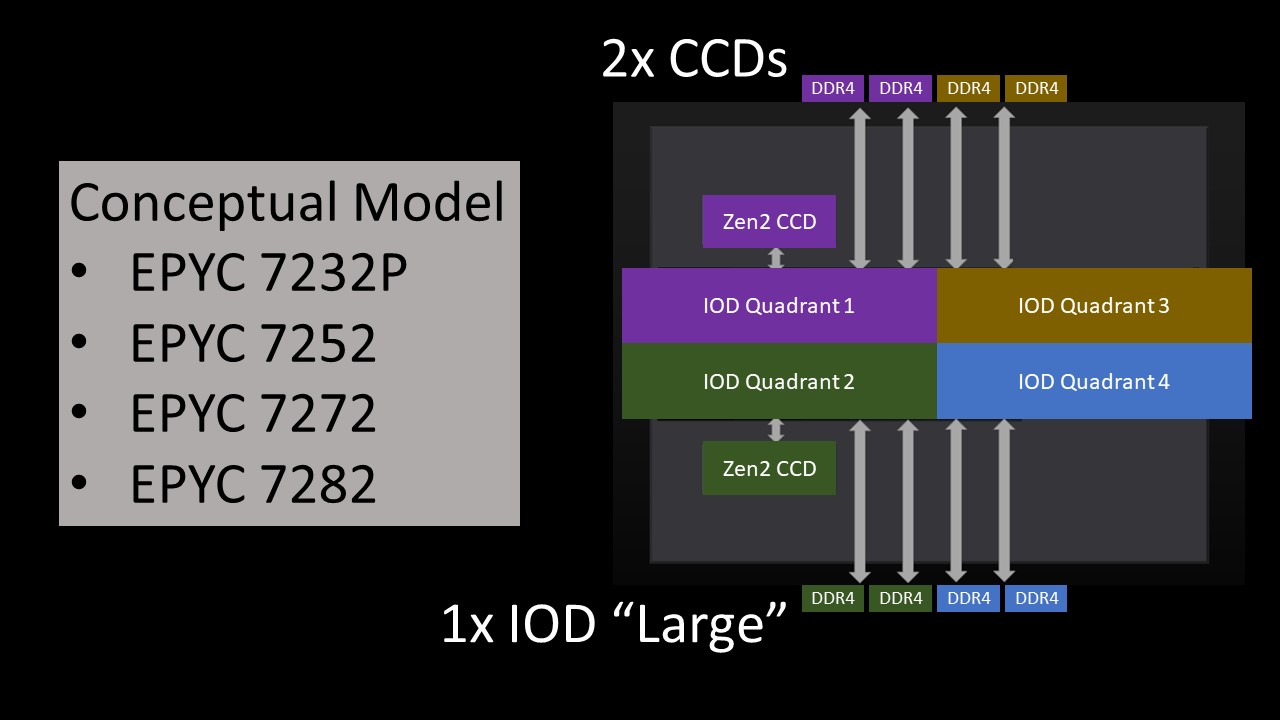
The impact of two CCDs per package is important. AMD says it has optimized bandwidth for this configuration. If you think about AMD’s design constraints then, the summary would be:
- Maintain an entire large I/O die
- Scale the SKU stack to lower-tiers, or 8 to 16 core parts
- Constrain costs when making those 8 to 16 core parts
- Limit power consumption on lower core count parts
Since AMD is populating fewer CCDs (two) per package in order to constrain costs and hit lower core counts, it is left with the large I/O die. AMD can optimize the placement of the CCDs on the I/O die for performance.
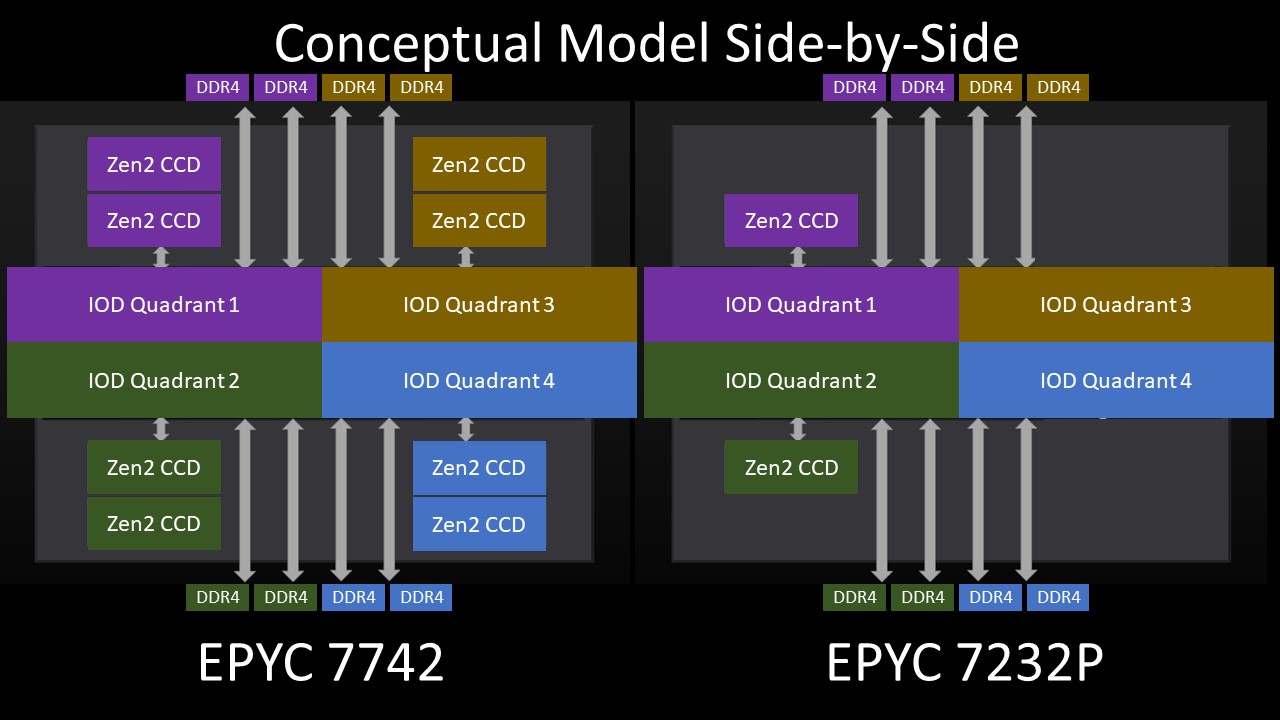
If you recall the conceptual model of that large I/O die again as four small I/O dies, then one can immediately see the architectural nuance. The large I/O die is designed to have CCDs hanging off of four small I/O dies, however, with the low core count parts, there are only two CCDs. That means there are two small I/O die “quadrants” that do not have a CCD attached and two that do. It also means the total fabric bandwidth to the two CCDs is limited to two links from the large I/O die to the CCDs.
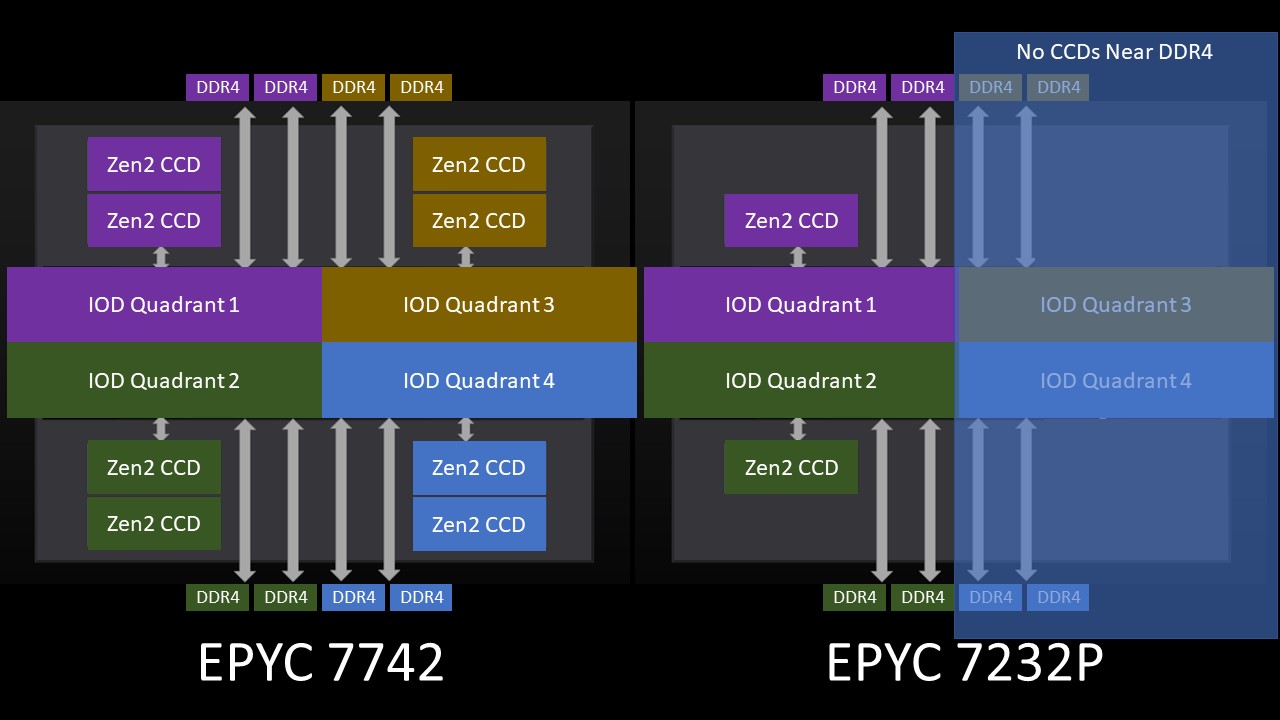
So the net of where we end up with this architecture, again using the simplified model, is that we are limited to about half the bandwidth of a fully populated package. While bandwidth is halved, capacity is not. The eight DDR4 interfaces are still connected to the large I/O die. In theory, you could have an 8 core AMD EPYC 7002 series CPU with 4TB of DDR4 with the bandwidth of 4 channel memory despite populating the system in 8 channel memory mode.
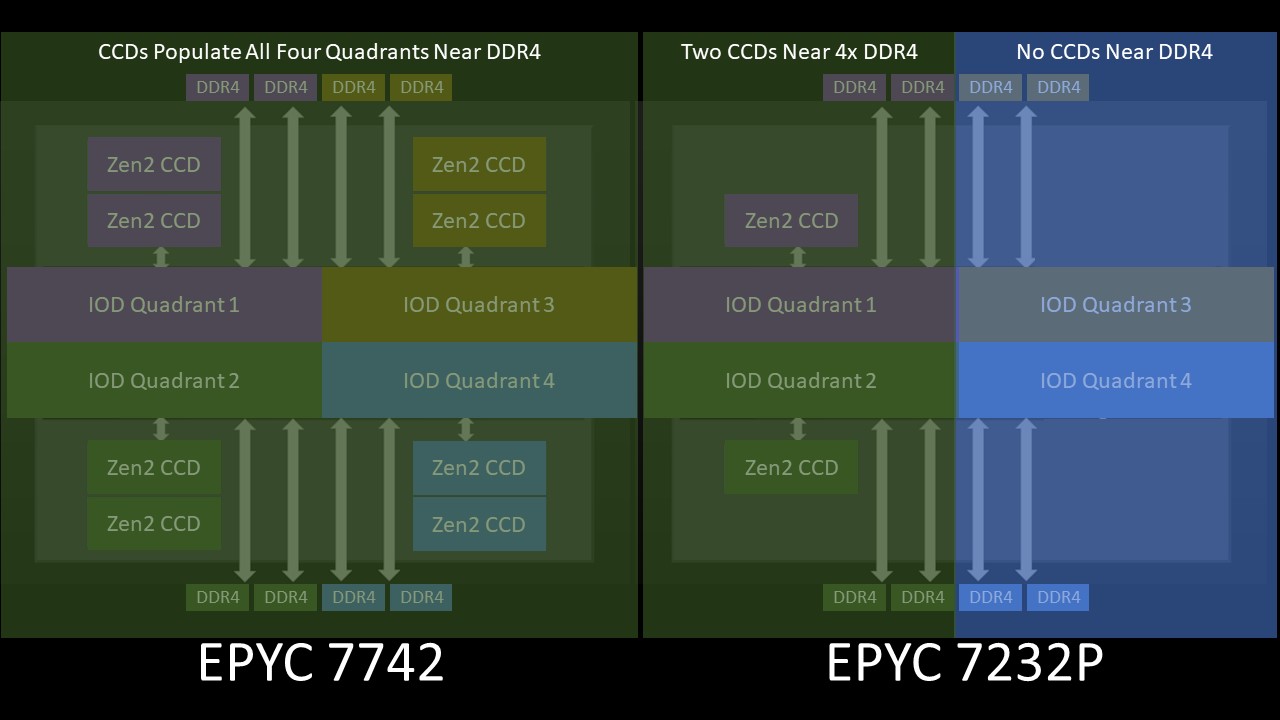
This is an extremely important nuance. In the last decade or more of Intel Xeon architectures, if you had a memory channel, you had the bandwidth for that channel. With these lower-end AMD EPYC 7002 series SKUs, you can have twice the number of DDR4 channels as the cores can consume in bandwidth.
4-Channel Optimized AMD EPYC 7002 Rome CPUs Impact
Many are likely now wondering, what four-channel memory means in terms of performance. That really depends on the application. When we looked at the results, we saw just about half the STREAM memory bandwidth of the higher-end SKUs. That is basically a worst-case benchmark. For the majority of the test suite that we run, both public and for our DemoEval clients, the real-world impact is in the 2-10% range in the HPE ProLiant DL325 Gen10 system if we were to project expected performance at the given core and clock speed of the chips we have tested. Of note, we have not been able to secure an EPYC 7252 but we have tested the other three chips that this configuration impacts. Other impacted application types are those that depend heavily on memory bandwidth often in the HPC space, and in-memory computing space, such as with Redis. We spoke to AMD about this before releasing this article to confirm this view.
The performance purists are not going to be happy with the concept of having eight-channel memory but the bandwidth of four. Still, this is absolutely fine for the market segment for a few reasons.
First, these are not the CPUs that people would use for high-performance computing applications. If you want fewer cores for per-core HPC application licensing, you are going to use a higher-end SKU. As an example, moving from the 4-channel optimized EPYC 7252 to the 8-channel optimized 7262 that we reviewed is only about $100. If your application costs thousands of dollars per core, you will be willing to spend that extra $100 in a heartbeat. Likewise, if you have an in-memory database application that you need a lot of performance from and a ~1.7-2x speedup costs $100, the $100 is almost inconsequential.
Instead, the market segment for these four SKUs is really the low-end server where CPU performance, and memory bandwidth related performance, are not the main purchasing criteria. Instead, this segment is focused on cost. An example of some of our eagle-eyed readers may have seen is from our HPE ProLiant DL325 Gen10 review. The HPE Smart Buy channel configurations we purchased for the lab only have 2 DIMMs populated to keep costs down. HPE has similar configurations for Xeon-based servers as well. The goal here is to keep costs down to an absolute minimum so populating the servers with additional memory is not a priority. Nor are expensive CPUs.

You can note here, only one DIMM is installed in this pre-configured system.
Common use-cases here are the workgroup backup server, print and file servers, low-end dedicated hosting servers. All of the types of applications that are cost-sensitive to where that $100 at the lowest-end make an enormous difference. The particular platform above is also a DDR4-2666 platform with PCIe Gen3 which uses a lower-cost motherboard. These platforms AMD also says the four-channel memory-optimized SKUs are designed for. That is why AMD lists them as quad-channel memory-optimized on DDR4-2666 platforms.
For that market, this configuration is actually still on the better side. Primary competitors at this core count and price point for the market segment are the Intel Xeon Bronze and Silver lines as well as perhaps the higher-end of the Xeon E-2200 line. One can also look to the replacement of Intel Xeon E5 V3 and V4 servers which are hitting their replacement cycle.
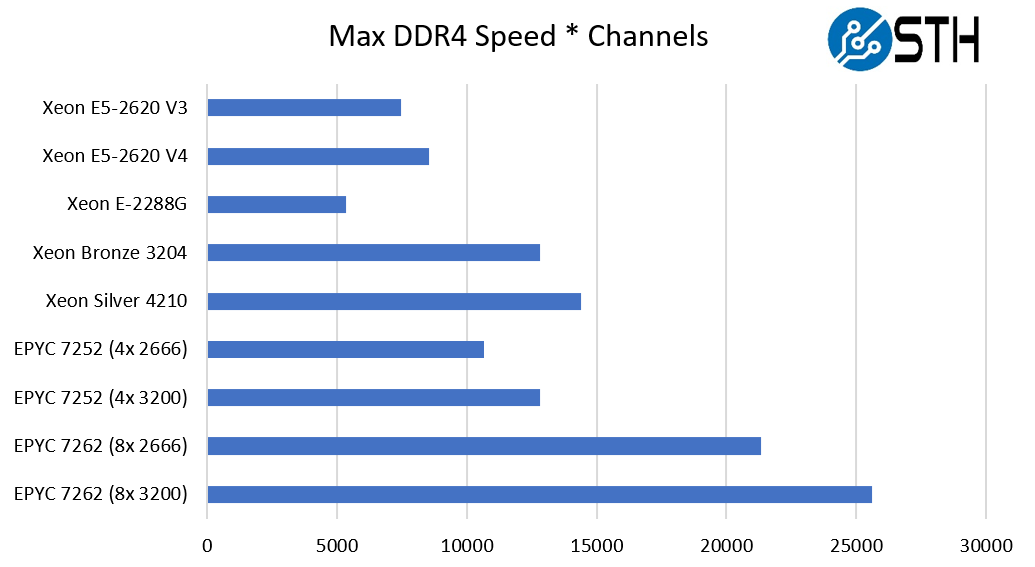
To keep the model extremely easy, and take out most of the effects of architectural differences and compilers, let us use a simple metric to see why. Effective DDR4 memory channels and speed. This is not perfect, but when we saw that the four-channel optimized EPYC 7002 series parts had about half of the STREAM benchmark performance of the normal eight-channel optimized parts, and we confirmed it with AMD, this became an easy way to show the market segment.
Due to the DDR4-3200 speed on the AMD EPYC 7002 series, and the fact that Intel de-rates the memory speed of its Xeon Bronze and Xeon Silver CPUs, one actually ends up with the 4-channel optimized SKUs in a dead heat with the 6 channel Xeon Bronze 3204 at 6x DDR4-2133. Even with two extra memory channels, the Xeon Silver 4210 is only about 12.5% ahead with DDR4-2400 memory. Since the Xeon E5 series is a quad-channel memory line, yet with older memory technology, we see the modern 4-channel optimized SKU well ahead of the Xeon E5 V3 and V4 SKUs that they would replace. The Xeon E-2200 series with its DDR4-2666 and dual-channel memory is not in the same league.

Therefore, de-rated, these 4-channel optimized SKUs are actually in-line with what Intel is offering in terms of theoretical memory bandwidth yet with much more scalable platform capabilities. If you want more performance, AMD has SKUs at the lower-end that can utilize more memory bandwidth.
Final Words
It has taken a while, but we finally have a good picture of the set of lower-cost SKUs that AMD markets as 4-channel optimized. On one hand, there are some benchmarks and applications where the 4-channel optimized SKUs are not as fast as their 8-channel counterparts. Those applications have simple alternatives in the EPYC stack except with the EPYC 7272 where there is no public 12-core 8-channel optimized SKU. For the intended market, optimizing for lower costs makes a lot of sense since memory bandwidth is less of a concern than cost and I/O connectivity. This cost-optimized segment is also running workloads that are unlikely to see a major impact from the reduced memory bandwidth. It just brings memory bandwidth down to levels more in-line with competitive Intel Xeon parts while maintaining the other EPYC 7002 series platform benefits.

AMD is marketing this as a feature. Probably the biggest benefit one gets is savings on power and cost. All four of these SKUs are 120W TDP parts. That figure is 35W lower than the next lowest SKUs in the AMD EPYC 7002 stack at 155W. Realistically, we should call these TCO optimized parts instead of 4-channel memory-optimized parts.
We hope this helps STH readers make intelligent decisions when specifying which CPU they purchase.



{kind=link}
Thanks for the interesting article. With this interrelation between dies and local memory channels, doesnt this contradict the supposed 1 NUMA domain architectural improvement of Rome vs Naples?
The Threadripper 3000 parts also come with 4 memory channels. Coincidence?
Today is not April 1, and you have a picture of an EPYC box in purest Intel blue. What is going on here?
What happened to the original article? I spotted it several days ago but then it disappeared until today.
What happens to the PCIe-to-RAM bandwidth? It seems the problem is not the RAM bandwidth itself but the CPUs-to-RAM access so it should leave plenty of RAM bandwidth for an NVMe array loaded up to the gills without affecting the CPUs-to-RAM bw.
I’m literally sending this to one of our customers right now.
I am glad this was designed on this fashion. This means it’s more likely servers will have a very nice upgrade path, especially for the second hand market. In a few years we could pick up a cheap used low end epyc 8core system and slap a high core count CPU in there vs the low end servers being lga115x or similar.
These CPUs might also make sense being used in SANs if cooling is done right. For example the Dell EMC SC All Flash Storage Array comes with dual E5-2628 v3 and 128GB RAM per controller. Could easily swap out the dual Xeons for a single 16 core Epyc and still get the same RAM density.
The one question or request that I would make is would you be able to compare the STREAM benchmark results between the EPYC 7252 and EPYC 7262 against the AMD Ryzen 7 3800X and the Ryzen 9 3950X as well?
The reason why I would ask for that is because if the EPYC 7252 and EPYC 7262 are geared towards low-end server applications where it is more sensitive to cost vs. performance (either in regards to the CPU or the raw memory bandwidth/performance), might there possible server use cases where even using the AMD Ryzen 7 3800X or the Ryzen 9 3950X be able to meet the needs and the demands of those use cases?
If you can present and/or comment in regards to that, that would be greatly appreciated.
Thank you.
alpha754293 – that is dual-channel v. quad-channel memory so it is about half of the 4-channel EPYC bandwidth.
As mentioned around the E-2200 series, they are somewhat different expandability segments. Then again, it is much easier to buy a single socket EPYC server from your favorite vendor than a Ryzen server.
hi, shouldn’t be the maximum number of CCDs (per IOD) FOUR instead of EIGHT? See your summary.
thank you
Jan
Correct me if I am wrong, but doesn’t this means you can populate all memory 8 channels each at half the speed and get unchanged bandwidth per core ? 2400Mhz dimms are somewhat less expensive than the 3200Mhz ones
So which are the 4 preferred channels namely, from the ABCD and EFGH channels marked on DIMM slots for the half-Rome models ?