
At AMD Financial Analyst Day 2020, the company outlined a broad portfolio of new programs. We are going to focus on the disclosures for AMD EPYC and the company’s new CDNA architecture for GPU compute.
AMD EPYC Genoa 5nm in 2022
AMD showed it is focused on delivering its new architectures on a quick cadence. We are currently on the AMD EPYC 7002 Series “Rome” which is a Zen 2 architecture part.

Later this year, AMD is focused on delivering “Milan” which is the 3rd generation AMD EPYC. This timing is about when we expect we will see some sort of Ice Lake Xeon launch from Intel. As a quick note, we expect to see Cooper Lake Xeons announced in the interim, but most are looking to Ice Lake on 10nm with PCIe Gen4 as the biggest competitor to AMD. AMD seems to be targeting Ice Lake Xeon rather than Cooper Lake Xeon with the next generation.

One of the interesting slides was how AMD sees the TAM for Milan versus its previous processors. Here, it is showing that Rome is only able to address about 80% of the CPU market for cloud, enterprise IT, and HPC. With “Milan” AMD expects this to grow to almost the entire market. That would mean, in theory, AMD will need to get into core/ frequency optimized EPYCs to a greater extent than the 16 and 32 core CPUs it has today as an example.

AMD also noted that part of its roadmap is continued innovation on the packaging side. We did not get specific dates or products tied to this slide.

There are certainly tantalizing bits here. We know Zen 4 and Genoa EPYCs will be shipping, at least for El Capitan, by late 2022 if it is going to be assembled and running in early 2023. That is a significantly higher cadence than we have seen from Intel lately but we know Intel is working to get their own cadence back up.
AMD CDNA GPU Compute for the Data Center
Part of the AMD data center story is a re-focus on data center GPUs. While NVIDIA pushed forward in the space, and Intel has announced its intention to get into data center GPUs, it seems like AMD may have focused more on the data center CPU side (EPYC) to date over the GPU. However, to win new Exascale supercomputer GPU components, it seems as though AMD is funding the GPU side to a much greater degree.

AMD will ship parts for the 1.5 Exaflop Frontier Supercomputer in 2021. The next year, it will ship Genoa and next-generation GPUs for the El Capitan 2 Exaflop Supercomputer. This is going to coincide with next-generation GPUs.

AMD has not revealed much on their new CDNA GPUs. They did release that this is a dedicated GPU for the data center market. It now sits in the data center group and not the gaming/ consumer side of AMD. The company said that the new 7nm CDNA part will be optimized for machine learning and HPC instead of gaming like a consumer GPU (and like NVIDIA Volta in that regard.) AMD has not said what process technology the CDNA 2 GPUs will use, but it looks like shipping alongside these GPUs will be the EPYC Zen 4 Genoa generation on 5nm but there are other options as well. Still, AMD is going to be under pressure to deliver a lot of exaflops in a power budget where a new process may help. NVIDIA will launch something new for the data center this year since Volta was launched during the NVIDIA GTC 2017 Keynote.

Without knowing the exact details of the process, it is highly likely that the US DOE surveyed NVIDIA’s offerings over the next 36 months while making this decision. These large-scale supercomputer contracts are for years in the future and often include funding for technology acceleration so disclosure is clearly part of the process.
If we think that NVIDIA “Volta” was the primary GPU architecture for at least three years in the data center, AMD is essentially showing that it is committing to releasing three GPU generations in three or three and a half years (although the MI60 GCN GPU was announced in late 2018.) With these new Exascale systems, AMD needs to efficiently deliver significant performance in order to get to 10x what we have today with Sierra and Summit.
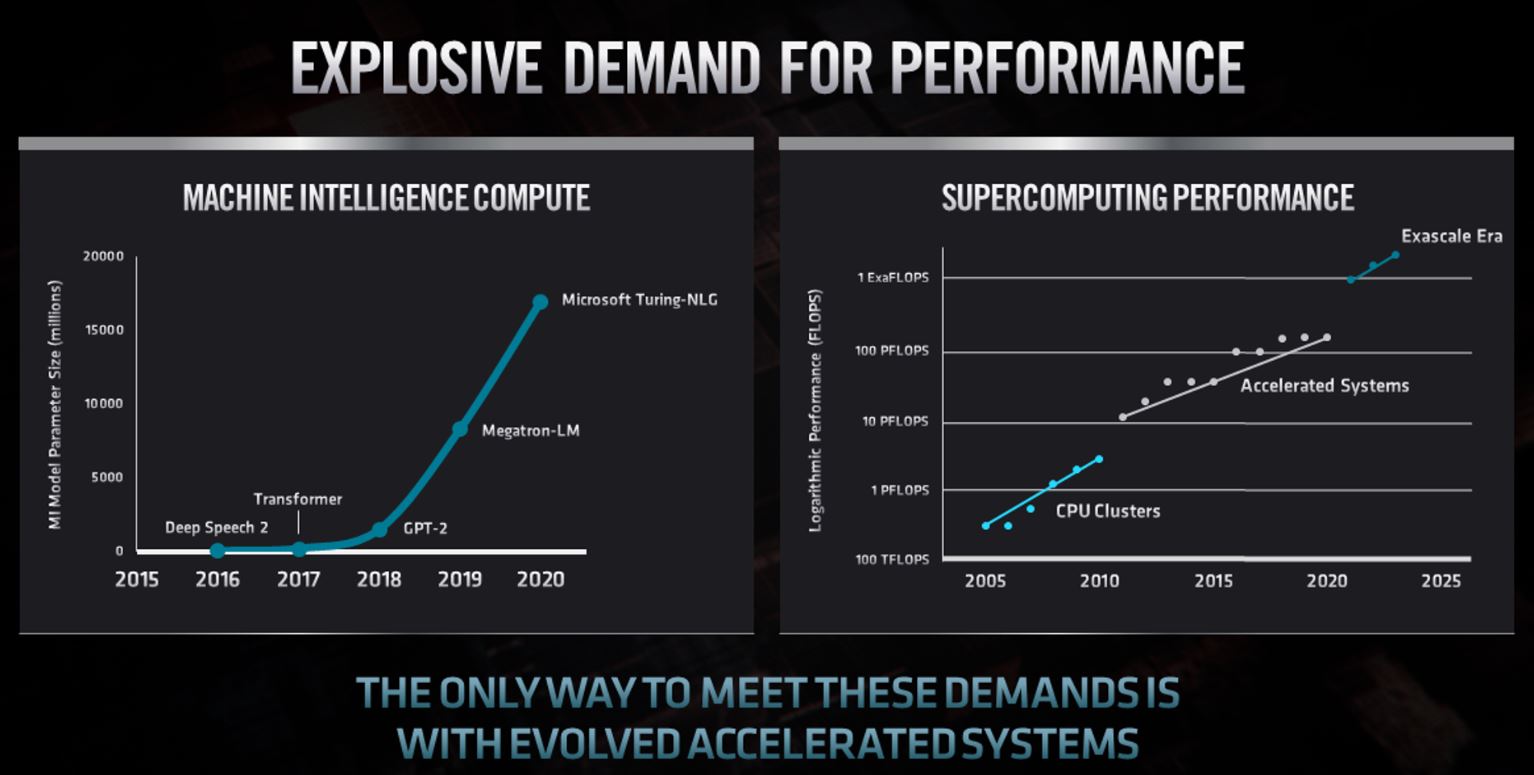
The new CDNA and CDNA 2 products seem to have impressed the US DOE and HPE-Cray with two-thirds of the initial exascale program using these parts.
Part of the funding for the new supercomputers is going towards upgrading the open-source software that underpins their usage. The US DOE is focused on that being the way forward rather than being locked into CUDA. As a result, there is a huge investment in taking what is ROCm today and turning it into a more viable open-source alternative. Essentially, the US DOE is undertaking a program analogous to what Google did with Tensorflow and Facebook did with Pytorch and decoupling their workloads from a CUDA lock-in model. That is why we see players like Cerebras Systems able to bring non-GPU architectures and relatively easily get them integrated with Tensorflow.
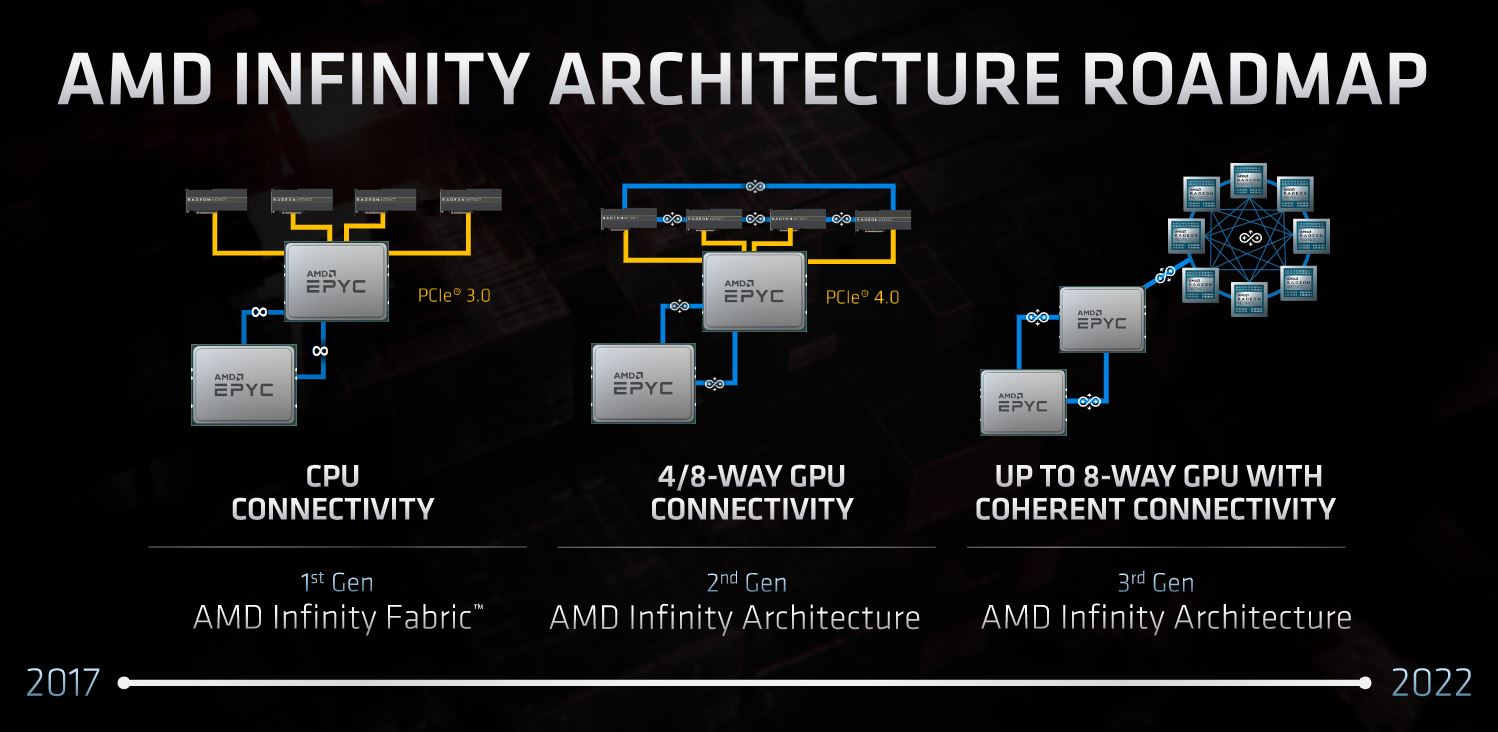
AMD spoke about how it is moving to a new cache coherency approach and new Infinity Architecture. We know this is the architecture the HPE-Cray Shasta platform is using.

Taking a leap here, 3rd Gen AMD Infinity Architecture coming in Genoa with a 2-2.5x CPU to GPU bandwidth gain over PCIe Gen4 likely means that it is based on PCIe Gen5. If AMD is using PCIe Gen5 and has a cache-coherent link it is deploying, this may be CXL.

That is some speculation, however, it seems like there is at least a decent chance we are going to see PCIe Gen5 from AMD in 2022. The alternative to getting there is that AMD would need to move to PCIe Gen4 x32 GPUs which seems less likely.
Final Words
The AMD Financial Analyst Day 2020 is focused more on the financials and giving financial analysts information. Still, there were a few nuggets for those of us following the industry. Also, AMD has now committed to both its investors, as well as the US DOE that it will deliver its CPU and GPU roadmap with specific timelines.



{kind=link}
Having cache-coherent link between CPU and GPU would mean GPU may use CPU’s RAM — ala POWER9 + NVidia in AC922. Which would be great.
Typo: “As a result, there is a huge investment in taking what is ROCm today and turning it into an open-source alternative.”
I’m guessing you mean “taking what is Cuda today”.
Added two words of clarification to that bit. I did not mean CUDA.
I would like to note that having more bandwidth than PCI-E 4 doesn’t mean AMD is moving to PCI-E for the interconnect, nor even CXL. IF is, afterall, a protocol that runs on top of PCI-E.
In Epyc 1 with IF gen 1, it offered a 20% bandwidth gain when running over PCI-E 3. They haven’t, to my knowledge, released what IF 2 offers over PCI-E 4, so things may have changed.
Article quote: “That is some speculation, however, it seems like there is at least a decent chance we are going to see PCIe Gen5 from AMD in 2022. The alternative to getting there is that AMD would need to move to PCIe Gen4 x32 GPUs which seems less likely.”
PCIe 6.0 is scheduled to be ready in 2021: https://www.businesswire.com/news/home/20190618005945/en/PCI-SIG%C2%AE-Announces-Upcoming-PCI-Express%C2%AE-6.0-Specification – For Epyc (in 2022) it makes sense to have the groundwork for PCIe 6.0 (then, already a year old) ready because it’s not a simple doubling of bandwidth, it adds PAM-4 and FEC; even if motherboards need to catch up.
If motherboards (initially) need to go to fewer slots there are examples of SuperMicro boards with x32 X9DRW-CTF31 and x48 X9DRW-iTPF PCIe 3.0 slots, since AMD makes graphics cards it’s not impossible for them to go beyond x16 (and add more lanes to the CPU).
While they’re certain to break new ground it’s also likely that they’ll expand on what’s already working for them; and that’s more lanes currently running at 4.0.
Before anyone says I’m getting too far ahead I’ll say I hope that they add support for posits, and end this comment there.