Acemagic F3A Performance
We looked at the AMD Ryzen AI 9 HX 370 previously, so the more interesting thing is probably the comparsion to the Beelink SER9 that used LPDDR5X. How much are you giving up to get expandable memory?
AMD Ryzen AI 9 HX 370 DDR5 SODIMM versus LPDDR5X Performance Comparison
Here is the quick comparison between the two:
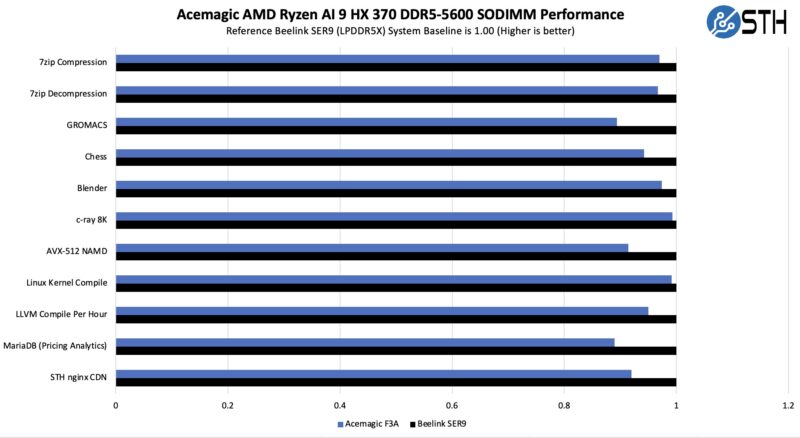
5-13% is not a huge amount, but another way to look at it is that it is somwhere around 0.5-1 core in a 12 core CPU system worth of performance. Surely you give up something for the slotted DDR5 SODIMM.
Geekbench 5 and Geekbench 6 Performance
On Geekbench 6, we ran the GPU compute (OpenCL) on the two systems, and clearly the LPDDR5X on the Beelink was faster.
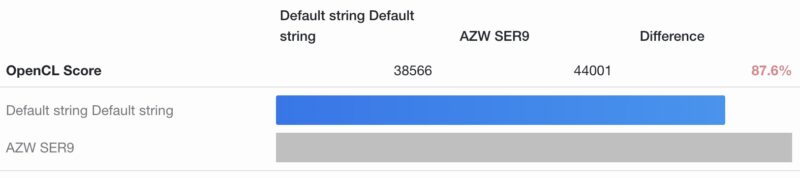
On the CPU compute side, we saw a big impact on multi-threaded workloads, but not as much on single-threaded workloads.

Here is the Geekbench 5 comparison:

Overall, there is a notable gap between the LPDDR5X and DDR5-5600 SODIMMs in terms of performance with the AMD Ryzen AI 9 HX 370. At the same time, there can also be a capacity gap, which we will get to next.
The AI Monster Within
Normally we would end it here, but you are probably wondering why you would give up that kind of performance. Here is asking deepseek-r1 32b running.
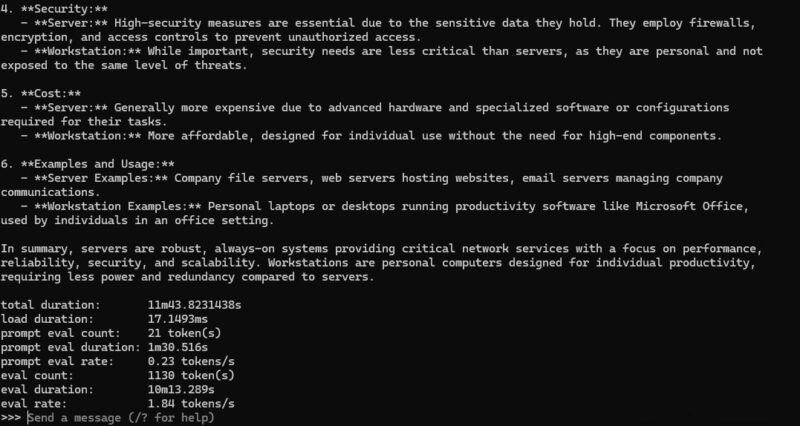
This is not fast, but it is running. Of course, more interesting is running a 70b version, so here is the deepseek-r1 70b distill running in LM Studio consuming well over 40GB alone, or more than the total amount of memory we had in the Beelink SER9.
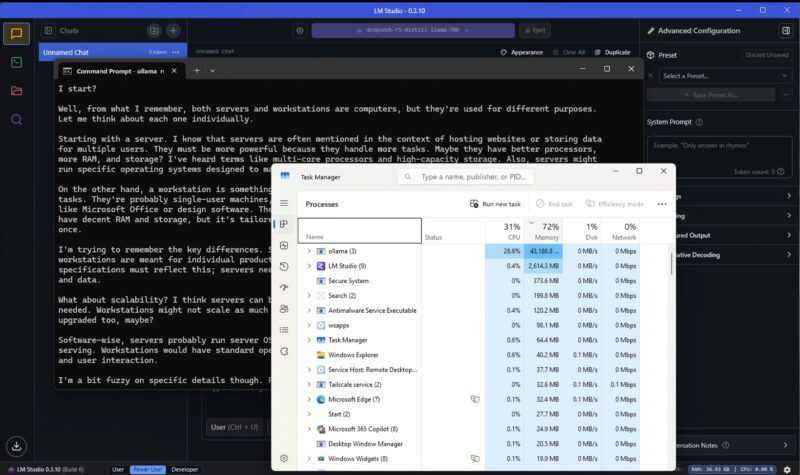
When we started playing with getting the integrated Radeon 890M going as well, that increased our memory usage.
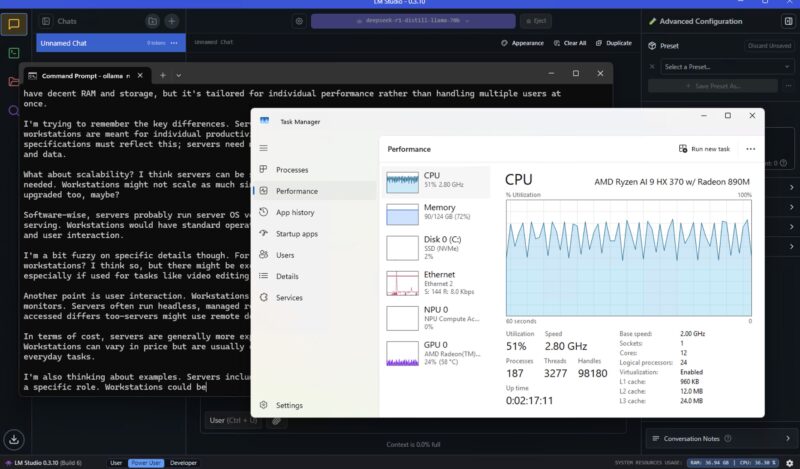
To be clear, if you want to go buy a big GPU for AI workloads with lots of memory, the performance will be much better. On the other hand, if you just want an AI assistant that you can task with something, and come back to in a few minutes, then this is really neat. You can use a higher accuracy model with a mini PC that costs closer to $1000.
Next, let us get to the power consumption and noise.



{kind=link}
Consider changing the hero image description to “Acemagic F3A: ISO 64,000” LOL.
According to the review this mini PC can run DeepSeek R1 70B distilled although slowly. How slowly? I’ve tried the same model on an older dual socket Epyc server and quickly realised that too slow makes a big difference in terms of usability.
As large language models perform differently than what’s included in the current selection of Serve the Home benchmarks, I think comparing DeepSeek R1 70B performance across a wide variety of CPU and GPU hardware would be make a very interesting article.
Did this thing come with preinstalled Windows? Be careful, Acemagic shipped Mini PCs with preinstalled malware/spyware in the past; you can find this documented very well on YT.
TBH, since then i dont trust them. Uefi is clean? With that, it would be possible to undermine anya installation, also fresh own ones.
I’d guess, no ECC Ram capabilities? This i’d love: a silent Ryzen mini PC for proxmox with 2 fast Lan ports and ECC support.
I am also waiting for the AMD AI MAX+ 395 MiniPCs to come out. I agree with Eric Olson that it would be nice to see an LLM inference speed comparison across different CPUs and GPUs. For me the expandable RAM is key. I was looking at the SER9 when it launched late last year, but I ended up with a 8945HX MiniPC because I didn’t like that I couldn’t get at least 48 GB of RAM in the SER9. I do LLM inference on some of my MiniPCs but my primary use for them is part of a Proxmox cluster so having expandable RAM is more important than maximum performance.
Does it have GPIO pins for connecting a pikvm for power control?
There is a 64GB version of the SER9 available now.
RAM size and (computational) speed needs to be kept in balance. Upgrading to 256 GB of RAM is pointless, since models requiring that amount of RAM will be very slow at this system. Even a 70B model is sluggish.
Thats where nvidias DGX Spark is much more promising: It combines a fair amount of RAM with, well, acceptable speed. This combination is much more usefull. That explains the price difference.
DPC Latencies would be interesting.
As important as computational speed is, bandwidth to memory is also pretty vital. Otherwise you not only have less than optimal number crunching, but the processor spends more time sitting idle waiting. The (quad channel?) higher bandwidth memory in the Spark is an important part of the design as well.
Which leads to my question: does anyone know if there’s a HEDT or workstation or gaming price range product (system or motherboard and compatible CPU) that uses DDR5 and has quad channel RAM? Ideally paired with an integrated GPU, but that seems unlikely.
Right now seems like Threadripper is probably my best bet for pricing, but I am interested if anyone has other suggestions.
Threadripper, Epyc, Xeon are the only choices I know of that support quad channel with DDR5 memory slots. Mac’s M4 minis have quad channel as well but they suck for gaming. M4Pros are Octachannel? They double the bandwidth and you can get a Mini with up to 64GB of ram, soldered. That makes them possibly decent for moderate gaming. The upcoming Framework desktop will be quad channel up to 128GB, and has an internal PCIe x4 header. In comparison, all of the AI 370 mini PCs are dual channel from how I’m reading specs.
DDR5 only supports up to 6000 MT/s, LPDDR5X supports around 8000 MT/s. If you need an AI-specific design both the M4 Mac Mini and Framework systems are looking interesting. Otherwise, unless you really need quad channel RAM, you can probably buy a decent base system for cheap and use dedicated GPUs instead.
Any idea where the wifi antennas are? I’m getting pretty slow wifi performance. Will probably swap the wifi card first before thinking of swapping the antennas