
Every so often when we do server reviews, folks ask for Geekbench 6 results so that they can compare their desktop, old server, Raspberry Pi or what have you to the latest server chip. Although Geekbench 5 is now considered “legacy” it is also much better suited to huge numbers of cores found in today’s processors.
A Reminder That Geekbench 6 is NOT for Big CPUs
Geekbench is primarily targeted at lower-end desktop and mobile processors. There are so many mobile devices out there that this makes sense. On the other hand, for large systems, we have seen since the Geekbench 6 launched that it is not designed to scale efficiently across multiple cores. At the time, the AMD Ryzen Threadripper 3995WX, a huge 64 core/ 128 thread part, was performing at only 3-4x the rate of an Intel D-1718T quad-core part, even despite the fact it had 16x the core count and lots of other features. Make no mistake, the AMD part is designed and is indeed much faster, and not 3-4x.
We recently tried the AmpereOne A192-32X on Geekbench 5 and it posted some solid numbers. Geekbench 6 for Arm errored out so we did not get a result for that one.
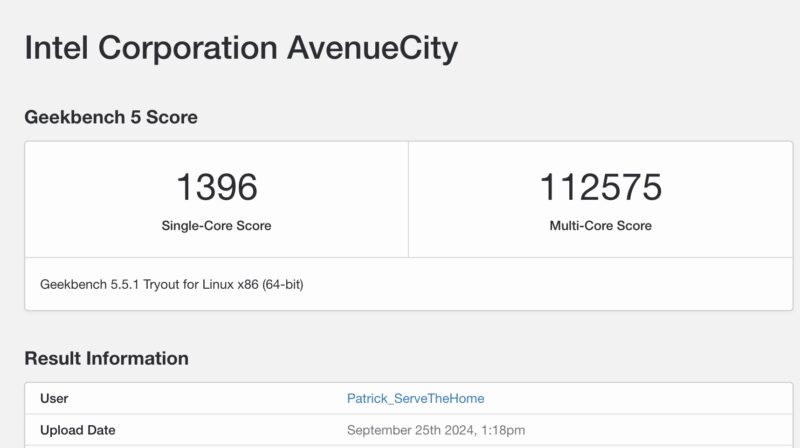
We also tried the dual Intel Xeon 6980P system, which out-of-the-box posted a top 10 Geekbench 5 score, with only what looks like some more tuned EPYC 9754 systems ahead. Geekbench 5 scales much better, but also can run into scaling challenges. On Geekbench 6, however, the massive 512-thread system posted a score closer to the ultra-low power edge Intel Core i7-1265UE. That is, of course, a silly result. Please do not quote that as the actual performance of the 512-thread Xeon since Geekbench 6’s score is nonsense for that chip running at very low overall CPU utilization.
At the same time, it is imperative from a conceptual standpoint. Today’s server chips often have so many cores that they are too big to run all but the most multi-threaded and scalable workloads across a single system. That is why more of our benchmarks are running tiled with multiple instances simultaneously. Perhaps 25 years ago, that would seem wrong, but modern CPUs are designed for virtualized and containerized environments and run multiple workloads simultaneously on the same package. The big customers for CPUs are cloud customers these days, and those CPUs are used for running multiple workloads and applications at once.
Final Words
We get asked about Geekbench 6 a surprising amount. With the transition from Geekbench 5 to Geekbench 6, the focus of the Primate Labs team shifted to smaller CPUs. Again, that makes a lot of sense since there are so many devices out there, from phones to notebooks. Today’s higher-end workstations and even higher-end desktop CPUs run into scaling issues with Geekbench 6. We will still post scores for lower-end to midrange desktop parts, but given the lack of scalability Geekbench 6 results are not coming to server reviews soon.



{kind=link}
The trade-off noted when Seymour Cray asked, “If you were plowing a field, which would you rather use? Two strong oxen or 1024 chickens?” is today reflected by the comparison of more efficiency cores versus fewer performance cores. Could the cloud be more like a chicken farm than compute-optimised HPC?
Amdahl’s Law limits strong scaling, Gustafson’s Law provides for weak scaling and some tasks are just not parallel. Does lack of scaling in Geekbench 6 result from hardware with catastrophically bottlenecked memory bandwidth or from the limits of strong scaling?
In my experience thrashing the shared L3 cache plays a huge role when scaling embarrassingly parallel but memory intensive tasks on current generation Xeon and Epyc hardware. Therefore, I find performance comparisons to be especially important in contexts where the observed parallel scaling is less than perfect.
Just wondering if the tiled approach would get interesting results for Geekbench 6 as well?
@Eric
Most of these servers are going to be used as hosts for a hypervisor. Therefore you are basically only limited on parallel work by your physical core counts. These 128 core CPUs aren’t going to be used for a SQL DB in a physical appliance. However, using Geekbench 6 is akin to doing that. Instead a better way to view it would be to have 10 VMs with 24 vCPUs (12 physical cores) running Geekbench 6 benchmarks on each VM but having them staggered as you almost never are running higher than 50% CPU utilization at any given time. Sure your VM Geekbench score won’t be as high as say a Ryzen 7900X but all 10 of them will look A LOT different than it would as a single 128 core appliance.
Why don’t you use passmark?
Just confirming what you wrote, I just compared Geekbench 5 and 6 on the AmpereOne A192-32X, and the results are staggeringly different, with the Geekbench 6 run not even using 1/3 the system’s normal power draw when maxing out the CPU for multicore operations. See: https://github.com/geerlingguy/sbc-reviews/issues/52#issuecomment-2452250408
It’d be nice if there was a ‘Geekbench of the servers’ though, it’s nice to have a round number as a *general/relative* comparison that is easily indexed, and has clients for all kinds of different devices/architectures. Not as many runs are shared for the server benchmarks we see on Phoronix, STH, etc.
Thanks for the reminder! It’s crucial to pick benchmarks that align with a CPU’s architecture. Geekbench 6 may work well for mobile or low-core systems, but for larger setups, a more scalable tool is needed to get accurate performance insights.