
Today, the MLPerf Inference v5.0 results were released. This release was, as one might expect, mostly dominated by NVIDIA Hopper systems, but there were a number of Blackwell GPUs out there as well. We also saw AMD and Intel have a number of submissions, but both were focused on two different parts of the market. What we did not see was a lot of chipmakers outside of those three, except for a Trillium result.
MLPerf Inference v5.0 Results Released
Starting with Intel, the company had several results with the Xeon 6900P and Xeon 6700P series. These results spanned a few OEMs as well. Intel’s marketing slide saying that it “Remains the only server CPU on MLPerf” feels a bit strange since there are plenty of NVIDIA Grace and AMD EPYC systems, they are just focused on the GPU results in those systems. Intel’s point might be that the Xeon results are the only CPU-only results.

NVIDIA, as usual, had a ton of results. It was nice to see the B200 and some of the Grace platforms make their marks on the test.
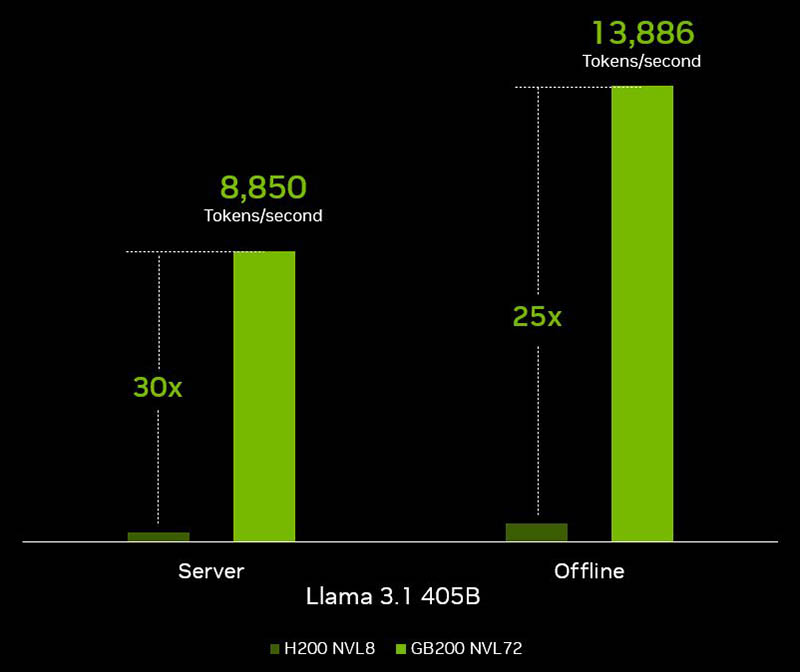
Perhaps most interesting is that in NVIDIA’s briefing materials they focused on the DeepSeek-R1 671B inference performance. A fun note, they are showing FP8 and FP4 here. A FP16 model is something like 1.2-1.3TB so an 8-way NVIDIA H200 system does not have enough HBM to fit a FP16 version.
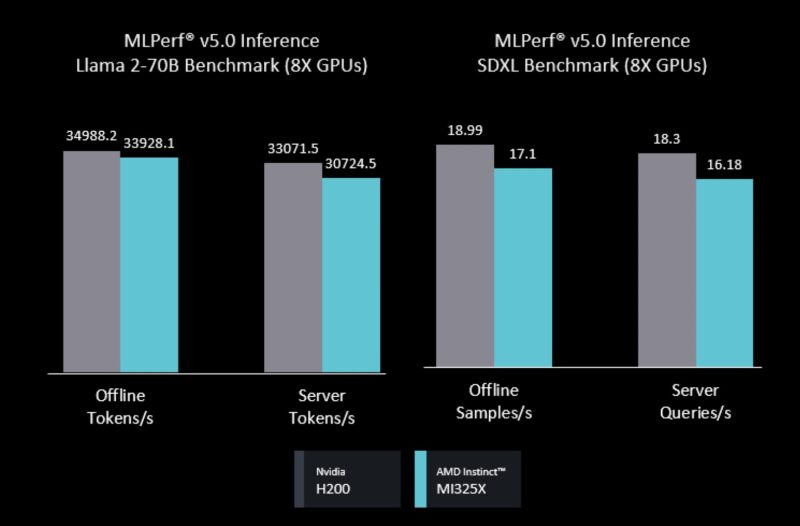
AMD for its part showed both single node and multi-node AMD Instinct MI325X performance in the realm of the NVIDIA H200. NVIDIA is really ramping on Blackwell at this point, but it is still great to see. AMD also is starting to enable its partners to submit results. NVIDIA does a lot of this work for its partner OEMs/ ODMs, so AMD following suit is nice to see.
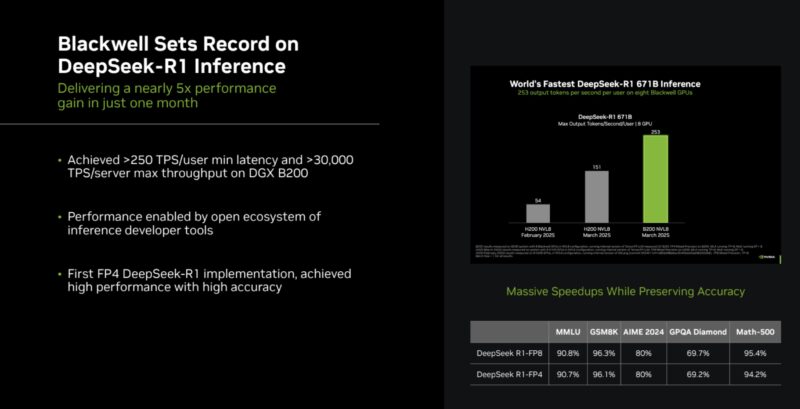
In AMD’s MLPerf Inference v5.0 blog, the company also highlighted its Deepseek-R1 671B performance tuning with AMD Instinct accelerators. That was certainly a theme.
Final Words
This was a bit of a strange one. Intel was doing its own thing showing CPU-only inference. That is a valid use case, and we are going to have a crazy cool article/ video on CPU inference in the next 48 hours. NVIDIA still had a lot of H200 results after Jensen said at GTC two weeks ago that the H200 was not worth buying. AMD has the MI325X competing with the H200 which is good to see. The one strange thing was that both NVIDIA and AMD went out of their way to highlight Deepseek-R1 tests not in MLPerf Inference during their MLPerf Inference releases.
You can check out the MLPerf Inference v5.0 results here.



{kind=link}
I do not really get why Intel pushes this CPU-only solution as viable. When you look at perf/power (even when going with just TDP) it is atrocious for Xeon 6, and requires that your solution works well with AMX which only supports BF16, FP16 and INT8. Accelerators often support more data formats, have better software ecosystems and superior perf/power.
Is it so surprising what Intel does? Their CPUs (as long as you can use AMX) are leading the competition, their accelerators are more of a sad story. So of course they’ll focus on the one area where they can win, even if that workload itself might not make much sense.
@Stefan
Xeon 6 leading the competition? That was only true when compared to Zen 4 EPYCs. With Zen 5 Turin AMD is again on top on average, even in some benchmarks that can take advantage of AMX.
From Phoronix’s test of Turin 10 benchmarks were AI-focused with TensorFlow and OpenVINO. Xeon 6 won only two by a decent margin, one by a small margin and lost 7 despite some of those also being the optimal type (FP16-INT8 or FP16) for AMX. So AMX’s performance is highly variable depending on type of workload, and can be beat by AMD’s AVX-512.
All while using more power. It’s a product that is somewhat competitive with a few narrow niches that perform spectacularly. Another advantage is non-TSMC production which positively impacts availability.