
The newest Top500 list is out, and we have the former #1 supercomputer Frontier was dethroned. In this list, the Intel-powered Aurora supercomputer passed 1EF, but then El Capitan rose to take the #1 spot. This is a big win for HPE and AMD delivering a system at over 2 exaflops of FP64 performance.
El Capitan Towers Above the Top500 in a Big HPE and AMD Win
STH’s El Capitan coverage started from the HPE headquarters building during a press and analyst conference that we captured in HPE-Cray and AMD Win Again with El Capitan 2 Exaflop Supercomputer. Between the pandemic that shut down the bay area later that month and then a number of engineering efforts, El Capitan emerged.
We are going to quickly mention the Aurora supercomputer at #3 on the November 2024 Top500 list. Aurora combines the Intel Xeon Max CPUs with Ponte Vecchio (Intel GPU Max) into the HPE Cray Shasta platform. Frontier, Aurora, and El Capitan are all HPE Cray Shasta Slingshot systems that are liquid cooled to a level well beyond what we often see on the AI cluster side. This is good for Intel to pass 1EF, but it is also not a great result if they cannot claim a #1 spot for a period of time. It looks like AMD is ahead.

The big star of the show, however, is the AMD Instinct MI300A system, El Capitan. With sustained HPL performance of 1.742EF and peak speed of 2.79EF of FP64 performance, this is a big jump over previous generation systems.
El Capitan has a unique architecture as it uses APUs combining CPU plus GPU onto a package with high-bandwidth memory. Here is one of the packages:

We discussed the AMD Instinct MI300X GPU and MI300A APUs previously, but at a high-level think of this as a MI300X GPU where some of the GPU compute resources were replaced with CPU. Or another way to think of this is as a highly leveled-up version of the AMD Ryzen AI 300 series that you might find in mini PCs like the Beelink SER9. An advantage of this approach is that the CPU and GPU portions share memory all on the same package.
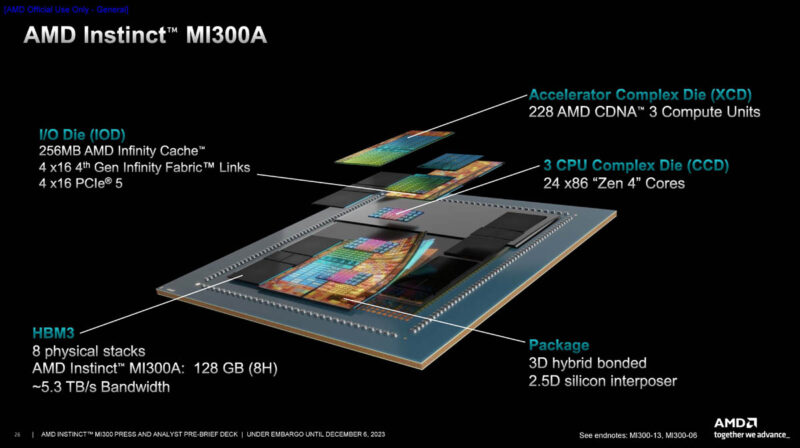
Over 44,000 of these MI300A APUs are then packed into the HPE Cray Shasta liquid cooled platform, and connected via the Slingshot interconnect. Add in ~35MW or so and you get the world’s highest performance Top500 run. We were told HPL actually takes only 28.9MW. There are 11,136 HPE Cray EX255a nodes with four MI300A’s each. Even for a large system, this is still #18 on the Green500 making it relatively energy efficient.

El Capitan is designed to start its classified missions in Q1 2025 for the US Government. There is another sister LLNL system to El Capitan, Tuoloumne which is a 0.2081 EF system. Italy, HPE Cray also has a new #6 system at 0.4779EF based on AMD MI250X. Frontier is now at 1.353EF in HPL making it #2 ahead of the 1.012EF Aurora.
Final Words
On one hand, a 35MW exascale system with tens of thousands of accelerators is huge. On the other hand, the new AI systems are being built to be much larger than today’s Top500 leaders. The question is at what point is a system too big to run Linpack on. Once you have billions of dollars that go into the new generation of AI supercomputers, the question is whether to run Linpack and submit on the Top500.
For some sense Microsoft said that its top supercomputer of three years ago is now the minimum size of a cluster for AI inference as it deploys inference supercomputers for deistributed inference. Microsoft and other hyper-scalers have some huge clusters that are not on the Top500. Beyond that, we recently showed the xAI Colossus system with over 100,000 GPUs. Linpack was not run on that system even though it is much larger than the first three exascale Top500 supercomputers.
Still, a lot of science needs to get done, and for work that requires double-precision calculations, HPE and AMD now hold the pinnacle with El Capitan.



{kind=link}
Patrick said “the question is at what point is a system too big to run Linpack on.” In my opinion, unless the system crashes before a run can finish, then it’s not too big.
Meta recently reported a failure on average every three hours in a recent AI training run involving 16,384 H100 GPUs. While only half of those failures were attributed to the GPUs, it would be amazing if xAI had enough fault tolerance to run HPL on that new 100,000 GPU cluster.
It’s also worth noting that Nvidia’s emphasis on AI at the expense of the high-precision arithmetic used in scientific computation has allowed AMD to take the lead in the Top 500.
I don’t think that’s the only factor that has led to AMD taking the lead in the Top500. I think AMD’s willingness to sell at a lower price and DOE’s willingness to chase FP64 price/performance are two other important factors. There are many more smaller scientific HPC machines using the H100/H200 than using the MI250 or MI300.
Anyway, for various reasons, most of which have been well-covered on STH, year by year the Top500 seems to become less relevant.
I’m really confused. I think there should be some different units of measure on some of these numbers. This system is claimed to take the performance crown:
“El Capitan. With sustained HPL performance of 1.742EF and peak speed of 2.79EF of FP64 performance”
And yet a few paragraphs later….
“here is another sister LLNL system to El Capitan, Tuoloumne which is a 208.1 EF system. Italy, HPE Cray also has a new #6 system at 477.9EF based on AMD MI250X”
So the #6 system is nearly 200x faster than the #1 system according to those sentences.
@James: indeed. In case of Tuolumne, the unit should be PetaFLOPS.