
At Hot Chips 2024, we got to learn about TTPoE, or the Tesla Transport Protocol over Ethernet. This is largely around the V1 of the TTP, but it is something that can be shared at Hot Chips. Instead of using TCP, Tesla decided to make its own networking protocol for its AI cluster.
Please excuse typos. These are being done in real-time during Hot Chips at Stanford.
Tesla DOJO Exa-Scale Lossy AI Network using the Tesla Transport Protocol over Ethernet TTPoE
For Tesla’s DOJO supercomputer, the company did not just make an AI accelerator, but also its own transport protocol over Ethernet. Or the aptly named Tesla Transport Protocol over Ethernet (TTPoE.)

Tesla says TCP/IP is too slow but RDMA using PFC for lossless fabric impacts the network.

TTPoE is a peer-to-peer transport layer protocol executed in hardware. One advantage is that Tesla does not need special switches since it is mostly using them for Layer 2 transport.

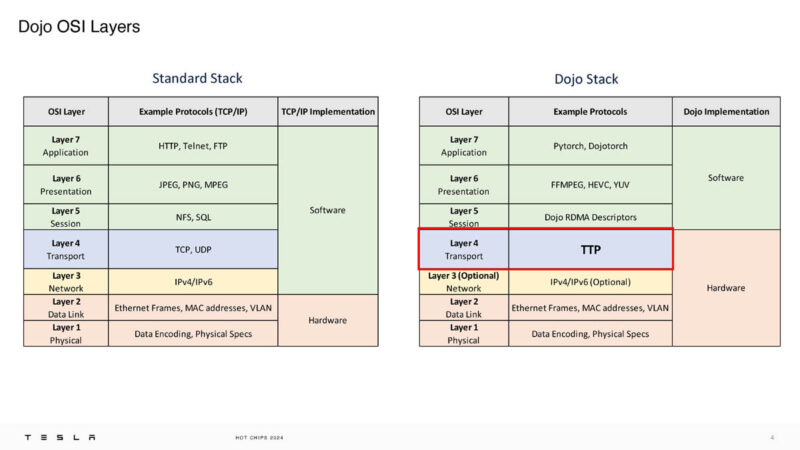
Here is the OSI layer for DOJO. We can see that Tesla is replacing the transport layer.
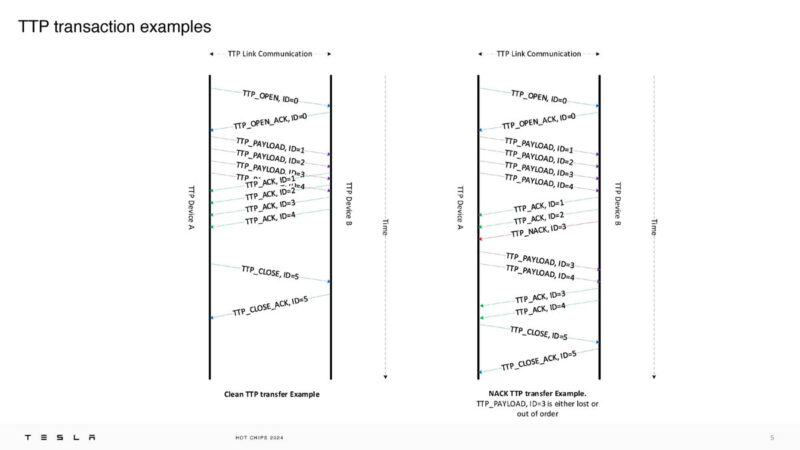
Here are the TTP transition examples over the TTP Link.
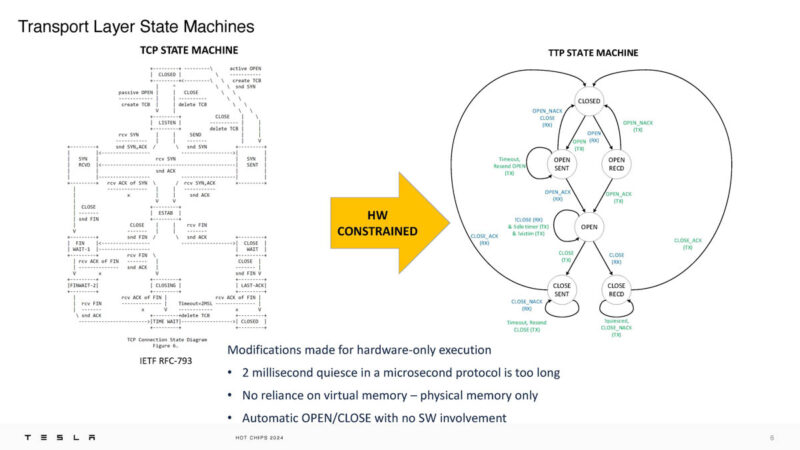
This is the TCP state machine versus the TTP state machine.
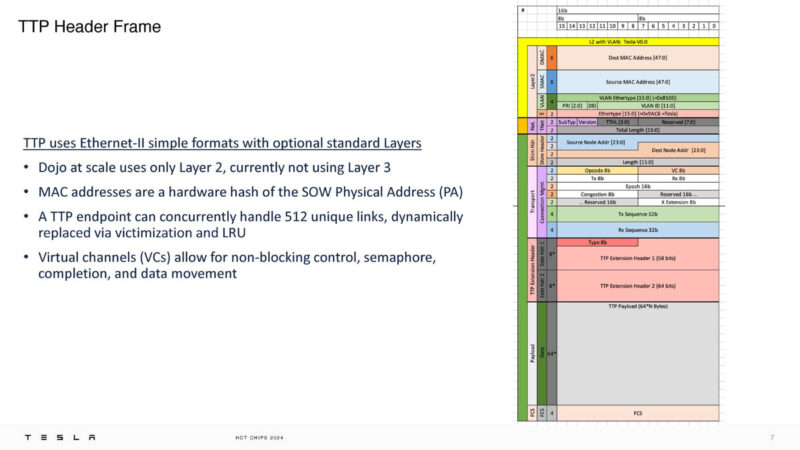
Here is the TTP header frame built on Ethernet-II framing.
Unlike lossless RDMA networks, TTPoE expects to lose packets and retry packet transmission. This is not UDP, instead it is more like TCP.
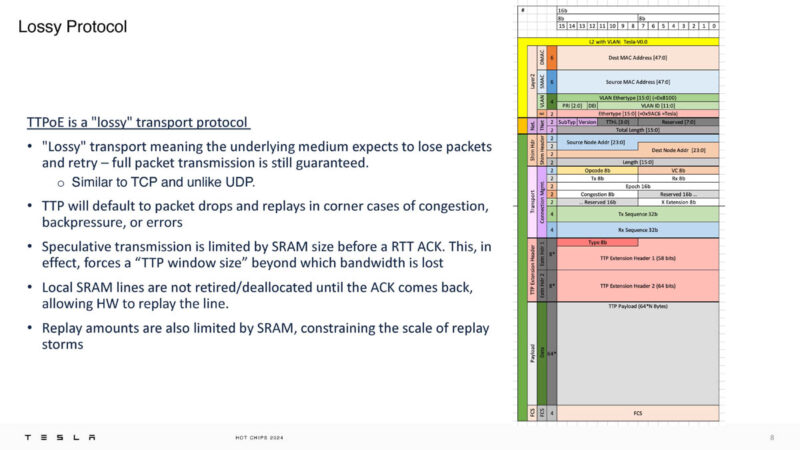
Congestion management is handled by local link channels instead of being done at the network or switch level. Tesla said TTP supports QoS, but it has been turned off.
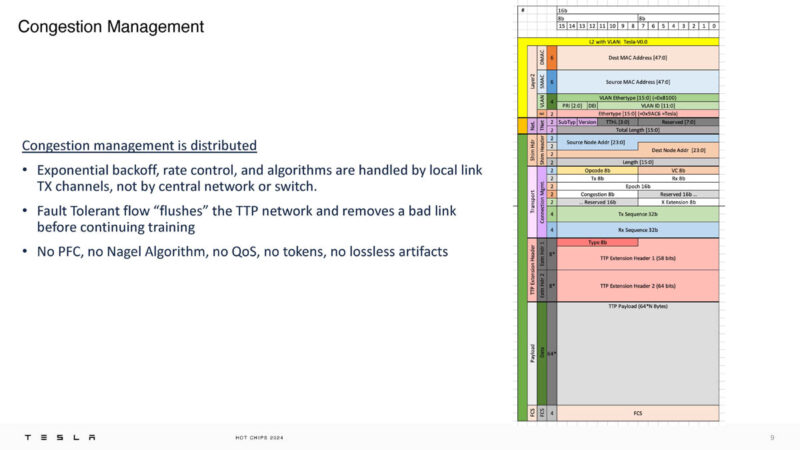
Tesla put this IP block in FPGA and silicon and it is designed to just blast packets across a wire.
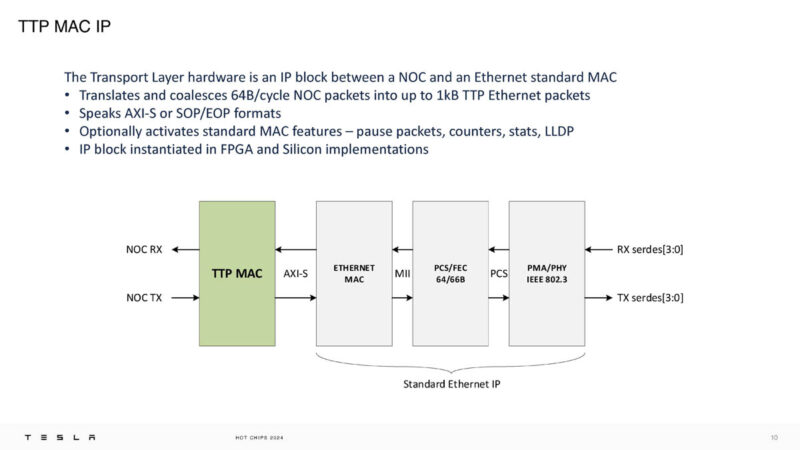
Here is the TTP microarchitecture. Something unique is that it looks a lot like a L3 cache. The 1MB of TX buffer was described as “in this generation” so there is a good chance it has changed in a newer generation. The last line of HBM2HBM fabric memory is a very popular feature.
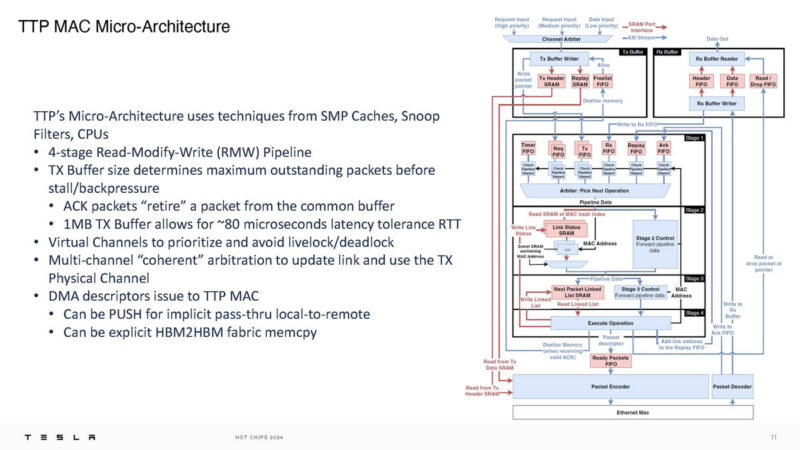
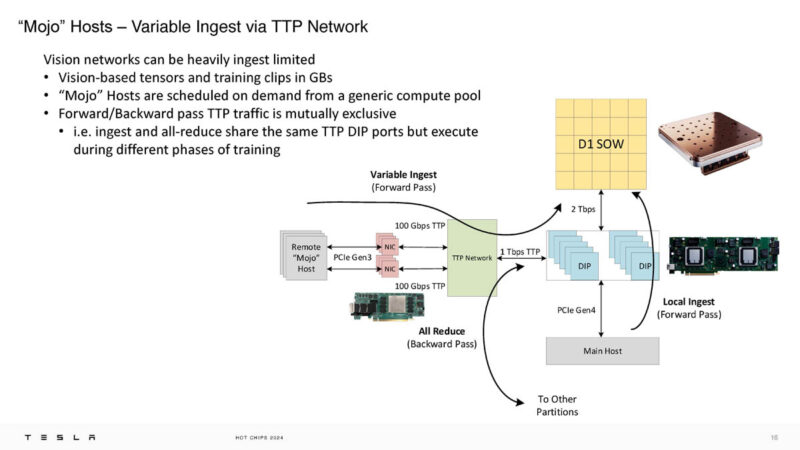
The 100Gbps NIC for Dojo is Mojo that runs at under 20W had has 8GB of DDR4 memory as well as the Dojo DMA engine onboard. We covered this in the Tesla Dojo Custom AI Supercomputer at HC34.

Tesla is now going back to that 2022 presentation showing the D1 Die.
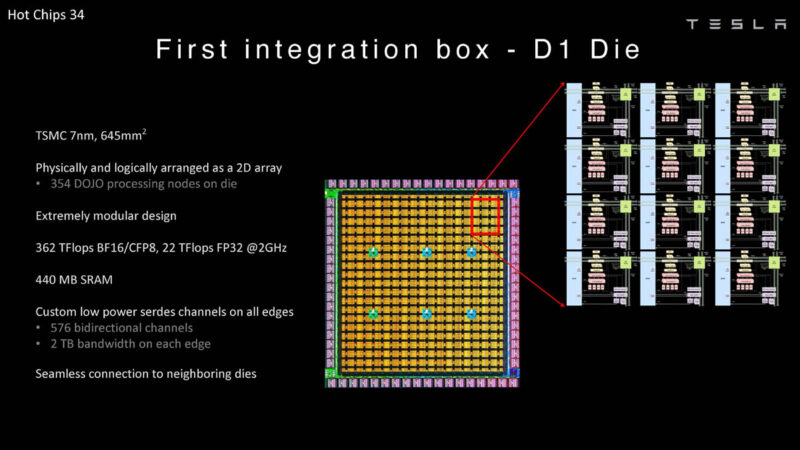
It is now showing the 5×5 array of D1 chips that are packaged together.

x
There is also a 32GB HBM Dojo Interface processor with TTPoE. The 900GB/s TTP interface is internal. TTPoE is wrapped in the Ethernet frame.

Tesla showed how Dojo is connected.

It starts with the assembly that houses the D1 tiles all packaged together which SerDes cabled connections.

Those go to the Interface Cards.

They are then attached to the low cost 100G NICs.

Here is another view of what was on the table.
Here is the Mojo Dojo Compute Hall or MDCH in New York. We can see 2U compute nodes without any front 2.5″ storage, which is really interesting.

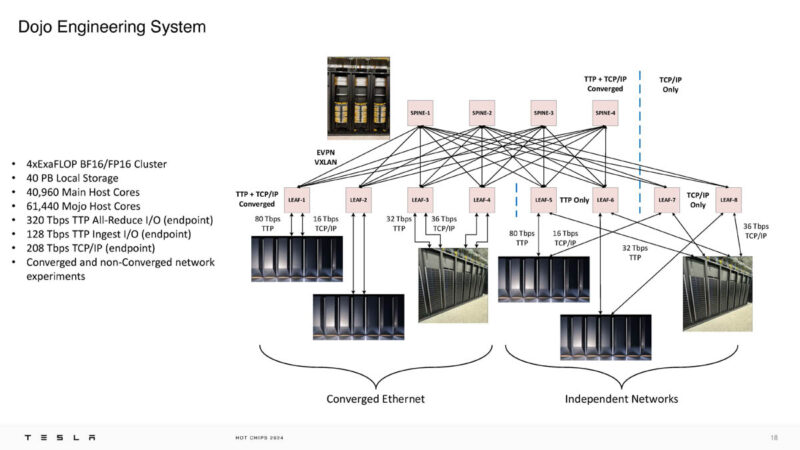
This is the 4 ExaFLOP engineering system with 40PB of local storage, and lots of bandwidth and compute. It is also somewhat crazy to have a 4EF (BF16/FP16) engineering system.
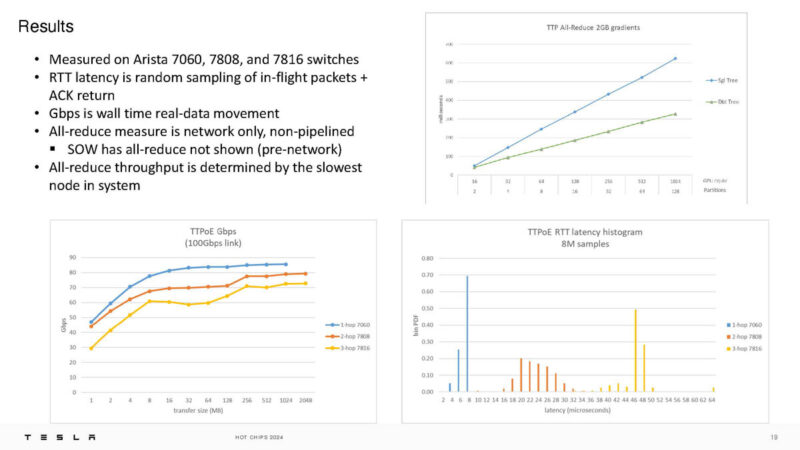
Arista has been providing switches for this. When the network is brought to a larger scale, with more hops, the latency additions have an impact on the bandwidth.
Tesla is joining UEC and is offering TTPoE publicly. Very cool!


It looks like Tesla is using Arista switches in the photos as well.

Here is something interesting. Tesla is also saying that TTPoE can have lower one-way write latency over a switch, and that includes NVLink.
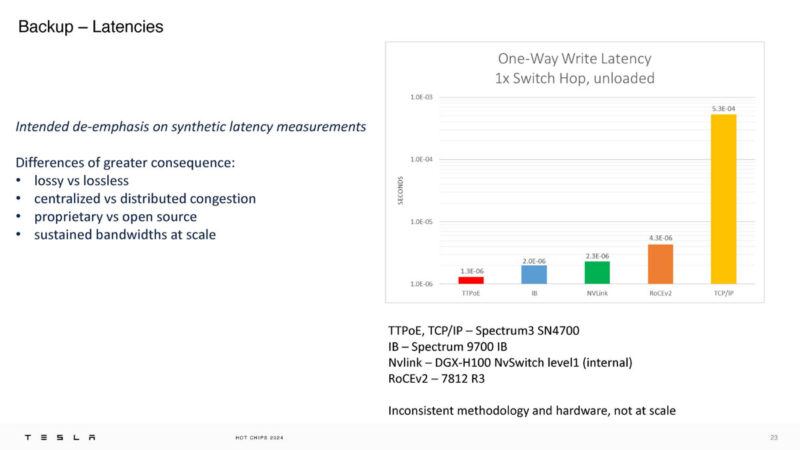
Tesla’s takeaway is that they are in the microsecond realm.
Final Words
This is one of those interesting talks, but at some point it would be cool if this was used beyond just Dojo. It feels like a lot of lifting to do making custom NICs, custom protocols, and so forth for a system and not trying to benefit from economies of scale. It was cool to see that Tesla is bringing this to the UltraEthernet Consortium.



{kind=link}
One slide makes a reference to a 40PB storage. Of course the storage must support TTPoE. Which kind of protocol is used to access the storage ?
My educated guess is that the DMA controller in the DOJO interface processor will handle that task.
Please ignore my comment. I misread the question.
Great to hear this is being taken to the Ultra Ethernet Cons. The ambition of lossless Ethernet is admirable but may have taken it beyond a reasonable timeframe.
Making everything work while the real world happens is the way to go.
Now to get testing how much loss, latency, jitter, etc is TOO much.