
At Hot Chips 2024, a theme is clearly AI. The SambaNova SN40L RDU is the company’s first design for the trillion parameter scale AI model era. I think the SN40L is outside, but there were a ton of people around earlier today. Hopefully, I will be able to grab a snapshot later.
Please note that we are doing these live at Hot Chips 2024 this week, so please excuse typos.
SambaNova SN40L RDU for Trillion Parameter AI Models
The new SambaNova SN40L “Cerulean” architecture. This is a 5nm TSMC chip with three tiers of memory, which is really neat. It is also a dataflow architecture that is designed to be a training and inference chip.

The three tiers of memory are on-chip SRAM at 520MB. There is then 64GB of HBM. There is then additional DDR memory as a capacity tier. SambaNova is showing a 16 socket system here to get features like 8GB of on-chip SRAM and 1TB of HBM.

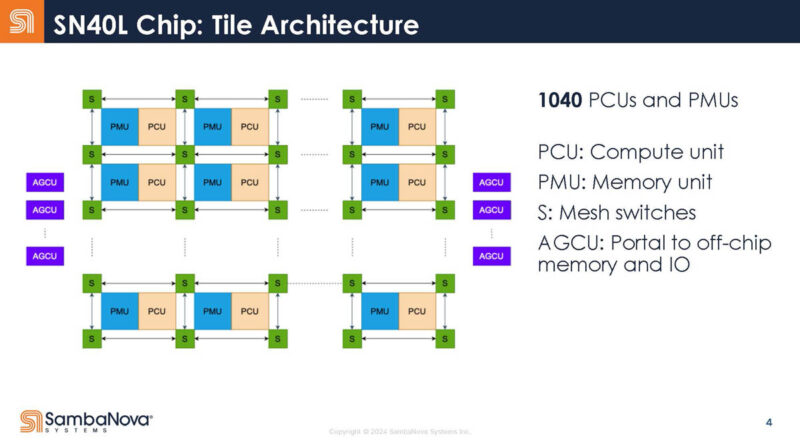
Here is a look at the 1040 compute and memory units with their mesh switches in the SambaNova tile.
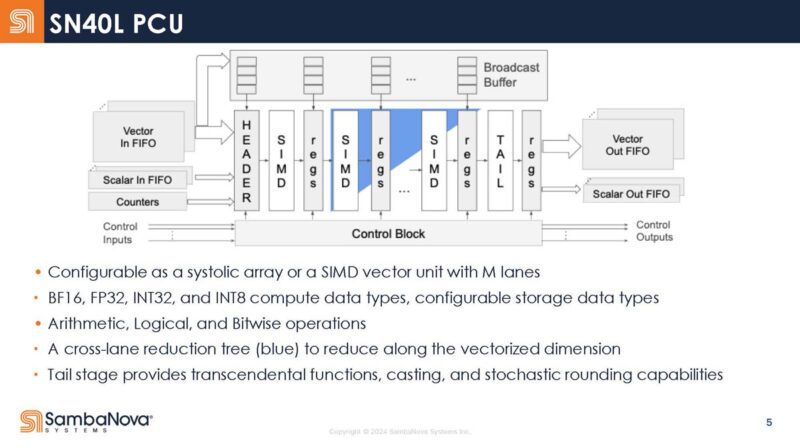
Here is the compute unit. Instead having a traditional fetch/ decode and so forth execution unit, it has a sequence of static stages. The PCU can operate as a streaming unit (data from left to right), the blue is a cross lane reduction tree. In a matrix compute operation, it can be used as a systolic array.
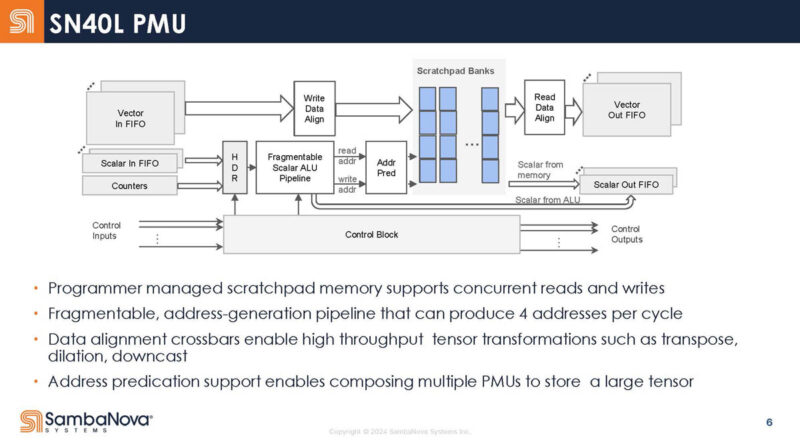
Here is the high-level memory unit block diagram. These are programmable managed scratch pads instead of traditional caches.
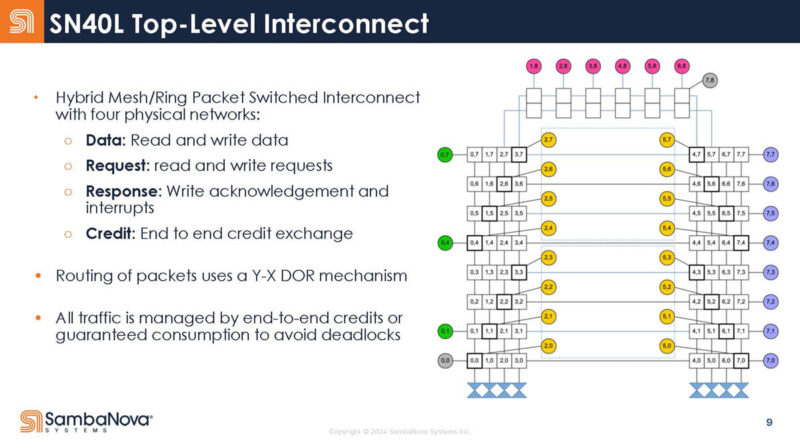
The chip also has a mesh network. There are three physical networks: vector, scalar, and control.

AGCU is being used to access off-chip memory (HBM and DDR) while the PCU is designed to access the on-chip SRAM scratchpads.

Here is the top-level interconnect.
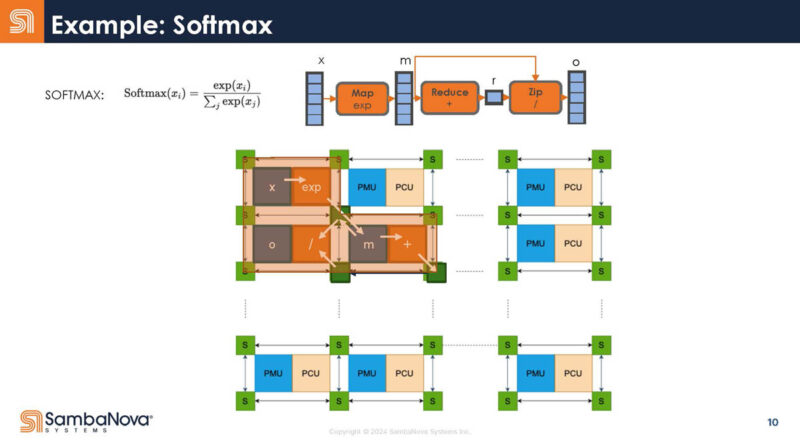
Here is an example of how the Softmax is caught by the compiler and then mapped to the hardware.
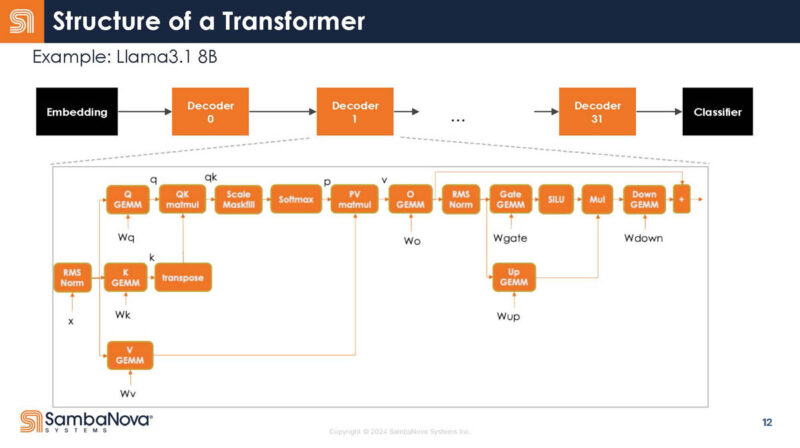
Mapping this to transformer models for LLMs and GenAI, here is the mapping. Looking inside the decoder, there are many different operations.
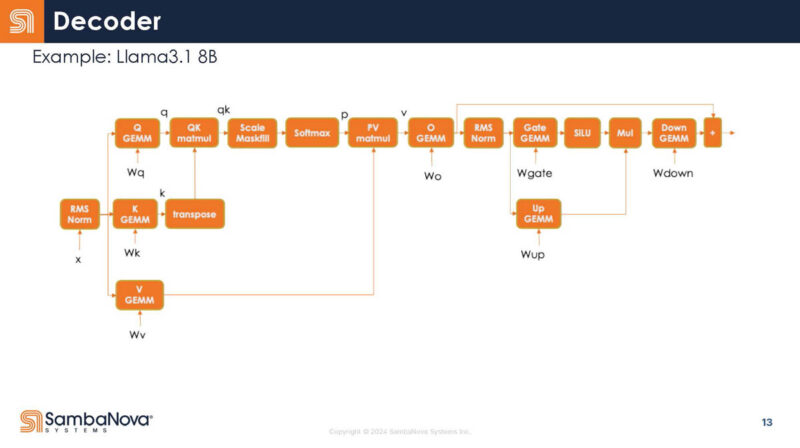
Here is a look at the decoder zoom-in. Each box is an operator. At the same time, usually you are running multiple of operator, and you keep data on chip for reuse.
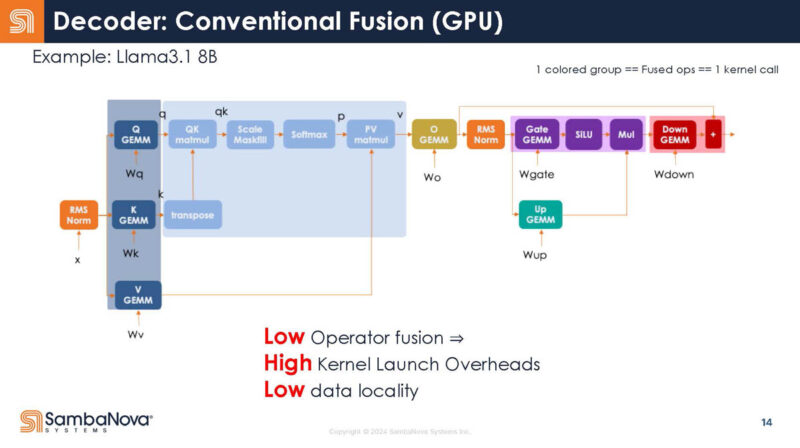
Here is SambaNova’s guess on how operators are fused on GPUs. They noted this may not be accurate.
In the RDU, the entire decoder is one kernel call. The compiler is what does this mapping.
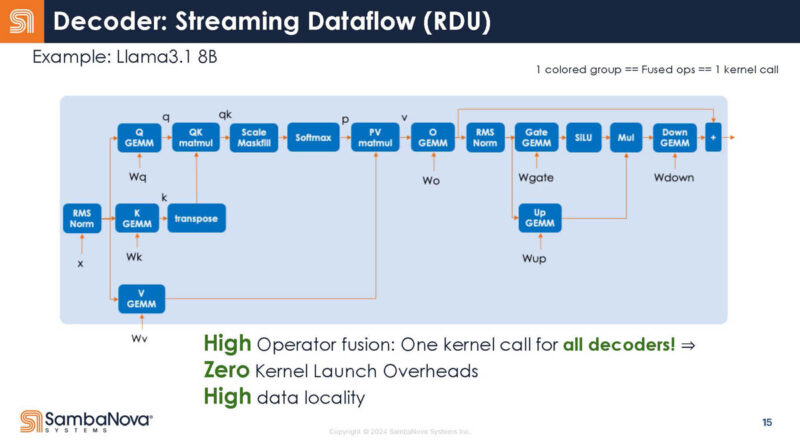
This slide is just a “cool picture” of the decoder mapping.

Returning to the transformer’s structure, here are the different functions for decoders. Something that you can see is that each function call has launch overheads.
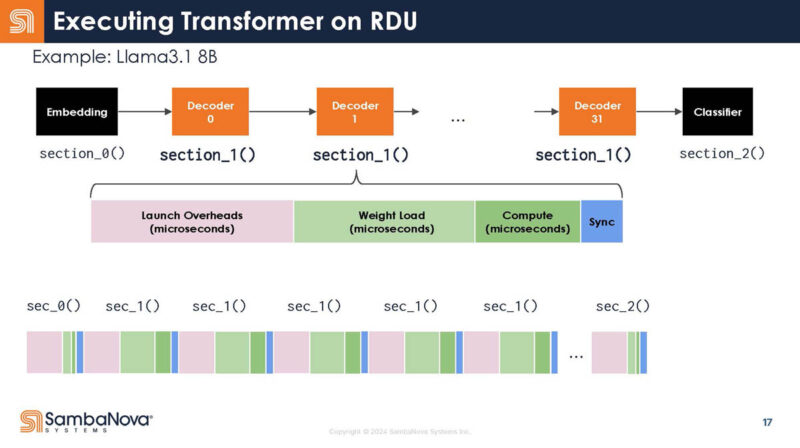
Instead of 32 calls, it is written as one call.
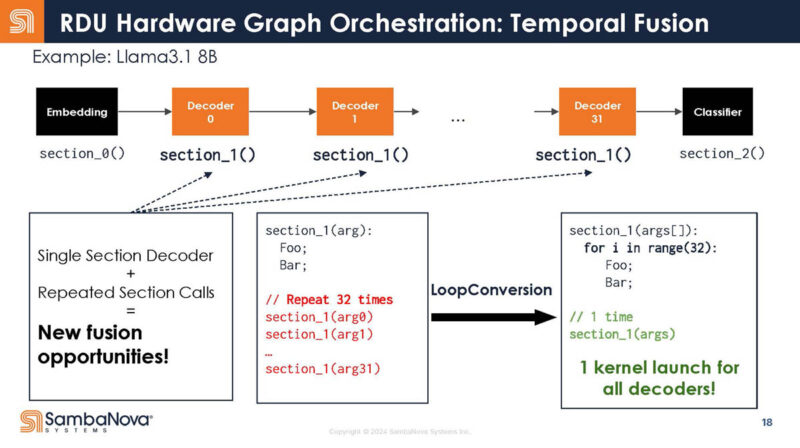
Translating that, it means that less of the call overhead is being done since there is one call instead of multiple calls. As a result, you increase the time the chip is doing useful work on the data.
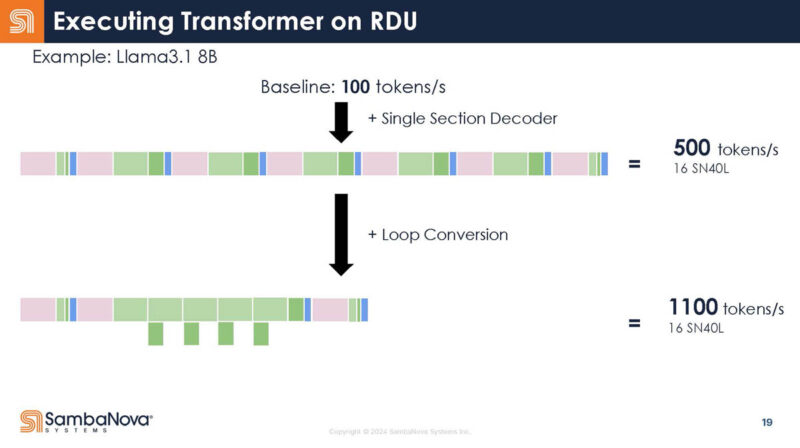
Here is SambaNova’s performance on llama3.1. There is a QR code here. It is SambaNova’s. We suggest not using it since… well who knows.

Here is scaling versus batch size with another QR code. The same warning applies. As you increase batch size, you ideally get scaling aligned with the batch size. SambaNova gets close.
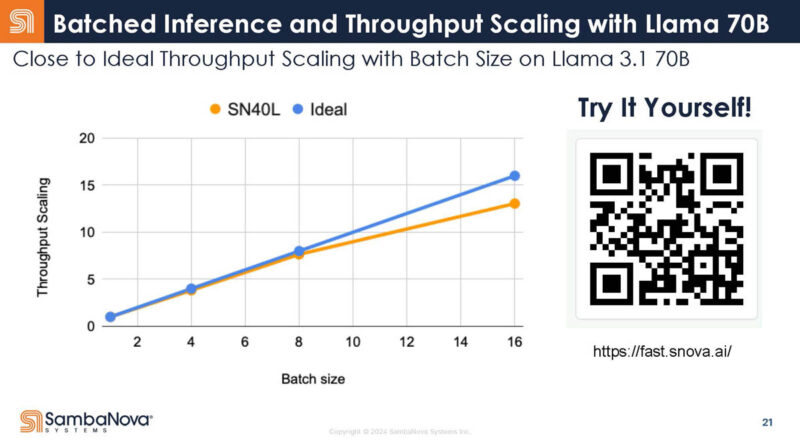
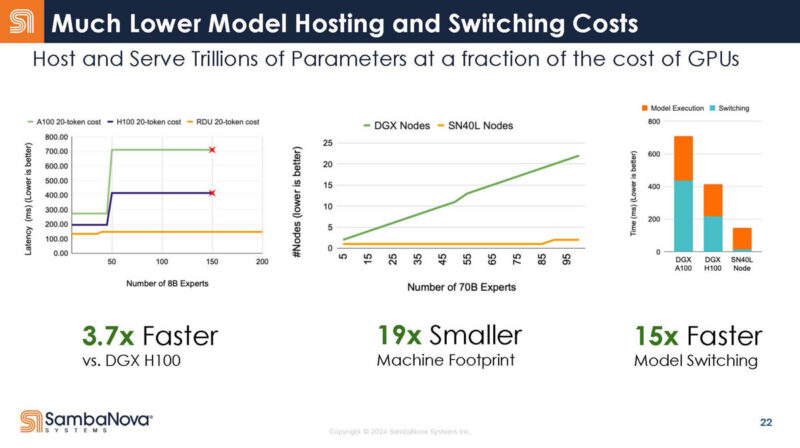
As a result, SambaNova says it has a compelling inference product. The DDR is being used for mixture of expert model checkpoints. The DDR onboard means that SambaNova does not need to go to a host CPU to get that data. Alternatively, you would need more GPUs to hold all of these checkpoints for the expert models. That DDR helps a lot on the model switching side.
Here is the slide on training.
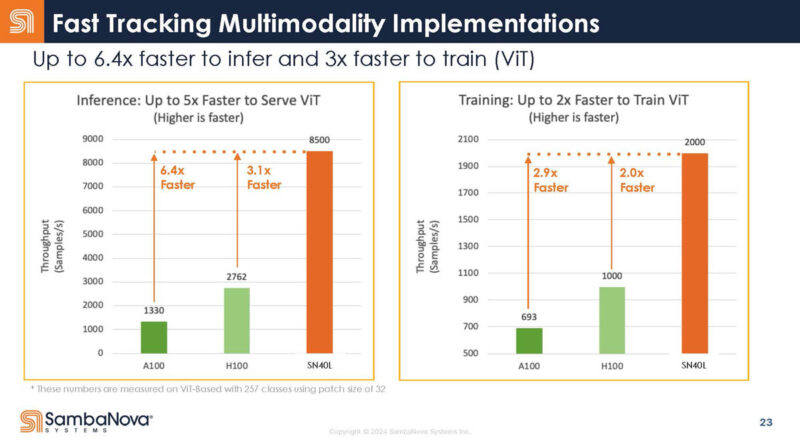
It looks like we are running a bit late so this is ending quickly.
Final Words
Overall, this is cool stuff. It is cool to see the company’s accelerator. I will update this piece if I get another close-up photo of the chip at a break.



{kind=link}