
AMD has a new processor series, the AMD Ryzen AI 300 series. Along with a new naming convention, the new line utilizes a new Zen 5 CPU core architecture, RDNA 3.5 GPU IP, and XDNA 2 NPU blocks to make something notably better in this generation. We got a preview last week in Los Angeles (note that AMD flew us there). Let us get into the new chip.
AMD Ryzen AI 300 Series Launched
We are now in the AI PC era, so TOPS have become a defining metric. AMD has been releasing APUs with increasing AI capabilities faster than Twinkies come off an assembly line. We now have the second iteration, just in 2024. The current AMD Ryzen AI 300 series gets new branding and a big upgrade in overall capabilities.
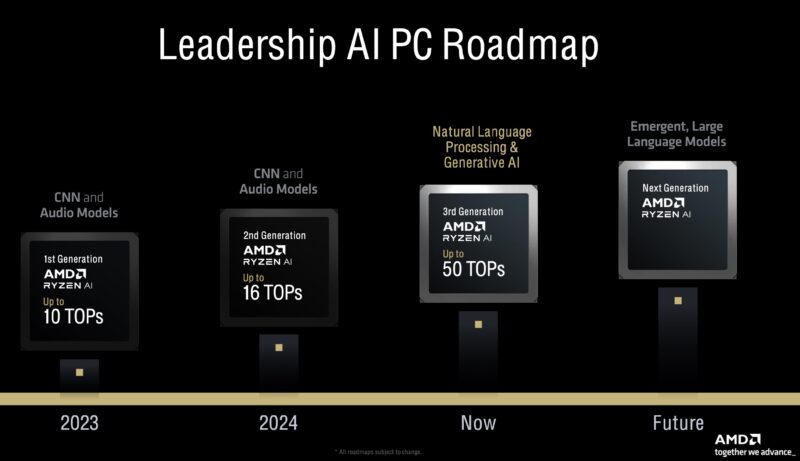
Of course, AI is a big feature, so whether it is AI on the GPU, CPU, or the dedicated NPU, AMD is working on it.

On all of those fronts, “Strix Point” makes advancements. We get the RDNA 3.5 GPU with up to 16 compute units, which will be the Radeon 890M version. The next-gen CPU is not called out here, but you will notice that we now get up to 12 cores and 24 threads. We also get the XDNA 2 NPU at 50 TOPs.
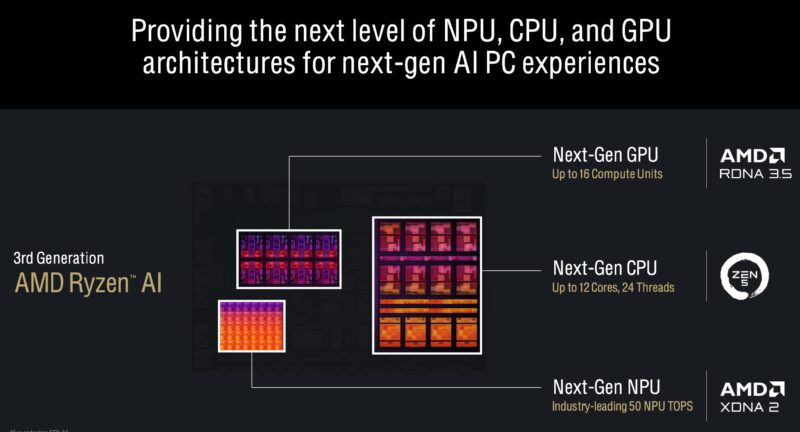
The core situation is going to raise a few eyebrows. Instead of having 12 Zen 5 cores, you will notice a block of eight and a block of four. There are eight Zen 5c cores and four Zen 5 cores. Each has its own L3 cache which means the Zen 5 cores do not get the same low latency access to the Zen 5c caches as they do their own. To put it in the opposite terms, that means the eight Zen 5c cores get 8MB of L3 cache, but they will have a latency penalty to get to the for Zen 5 cores and their 16MB of L3 cache. AMD told us that is something that they can look at for future designs.

To understand why this is important, recall the difference between EPYC 7002 and EPYC 7003 processors, where one of the big differences is when the entire CCD could access all of the CCD’s cache instead of having to hop through the I/O die. AMD says that this helps because they can tune the Zen 5 cores for all-out performance and then clock the Zen 5c cores lower for higher throughput. AMD also would argue this is better than having two different core architectures with ISA differences.
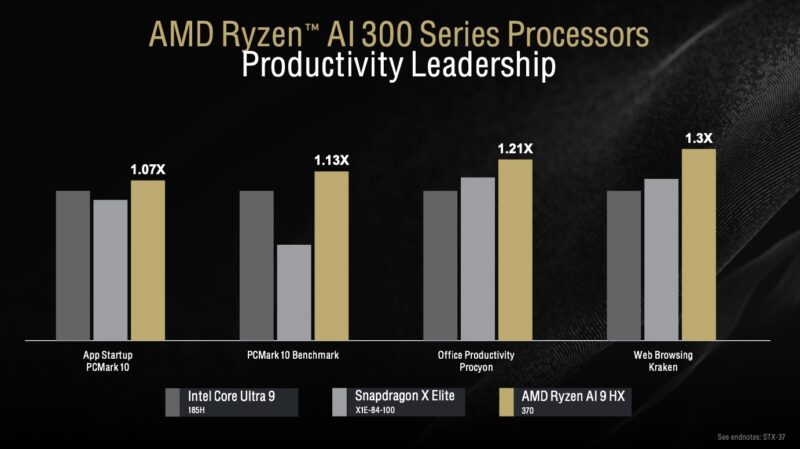
Now that Qualcomm has entered, AMD has added them to its comparison list. Intel is still the 1.0 baseline for its productivity benchmarks.
On the content creation, AMD’s big Zen cores tend to do very well so we see outsized gains here. Interestingly enough, AMD seems to be saying content creation is better on the Snapdragon X than on Intel CPUs. Of course, AMD is using the available Intel CPUs, not the upcoming Lunar Lake series.
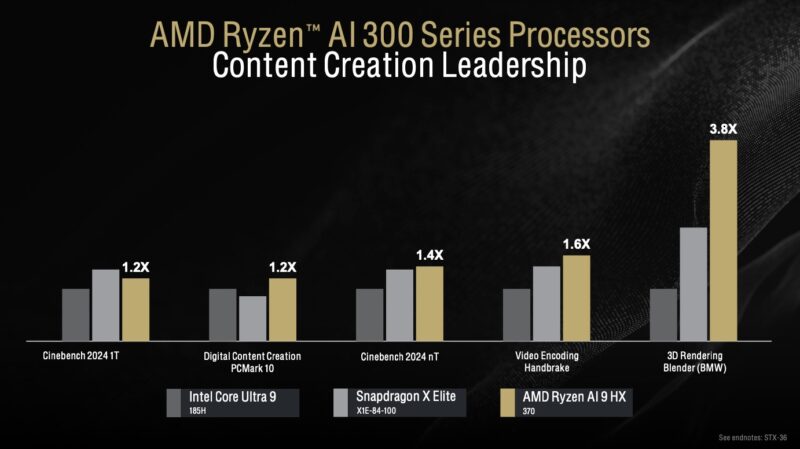
AMD had a demo using Blackmagic Design’s DaVinci software. STH’s YouTube is still an Adobe Premiere Pro shop, but DaVinci has a lot of great features, and it is one of the three big solutions that you will see broad swaths of the industry use (Apple Final Cut Pro X is the other.) Blackmagic Design DaVinci usually runs best on Apple Silicon, but it is much less expensive to get a good editing notebook or workstation based on AMD, especially with Apple’s memory and NAND pricing.

AMD has the new AMD Radeon 890M and 880M graphics based on RDNA 3.5 in addition to the new Zen 5 CPU, so we get better gaming performance.
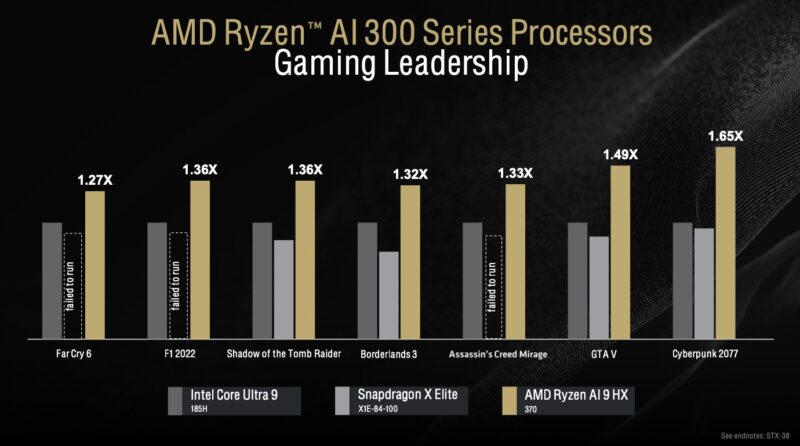
A quick note: this chart hurts Snapdragon X Elite. One can claim similar performance or better battery life, but at the end of the day, applications not running on an architecture are going to be the biggest differentiator. Having had several Apple M1 machines, the compatibility transition has been swift, but it was terrible to see a $3500+ notebook not able to run some applications when they were launched, even with Rosetta.
Of course, the big focus is on AI. AMD says it has a long way to go between today’s processor and what pervasive AI will need.

One question I had was that if AMD believed that AI was going to be the #1 driver of PC sales, why not use more of the die area for XDNA 2 instead of Zen 5c? The answer seems to be that we are in the early days of the AI PC market.
Final Words
The 3rd Gen AMD Ryzen AI 300 “Strix Point” will undoubtedly see a more expansive roll-out than just the AMD Ryzen 9 AI HX 370 (12 core/ Radeon 890M) and Ryzen 9 AI 365 (10 core/ Radeon 880M.) At the same time, it really highlights where these are going. On the desktop Ryzen 9000 side, it is all about CPU performance. On the mobile side, we have CPU cores, but then a lot of die area is dedicated to GPU and NPU accelerators.

It feels strange, but in this generation, I am more excited to use the Ryzen AI 300 series than the Ryzen 9000 series based on the demos I have seen. Perhaps this will change as we get them into the lab and are able to share our results with the STH community.



{kind=link}
Hopefully virtualization OK across the different cores/cache? The previous-generation mini PCs (with homogenous architecture) were fantastic for homelabs!
Fun fact: it’s TOPS (Tera Operations Per Second), not TOPs. Yes, AMD screwed up their slides.
“One question I had was that if AMD believed that AI was going to be the #1 driver of PC sales, why not use more of the die area for XDNA 2 instead of Zen 5c?”
I’d be curious whether they actually do, particularly at laptop scales. Throwing just enough NPU at the problem to tick Microsoft’s “Copilot Plus” box, along with being able to claim a slight edge over Qualcomm and Intel in the area; then dedicating the rest to CPU and GPU sounds a lot like someone who doesn’t think that they can just ignore the whole thing and let it blow over(nor does calling it the “AI 300”); but not like someone who thinks that there’s necessarily something desperately interesting at 80 or 100 TOPS.
Seems plausible enough, really. if you care about doing big things locally a laptop is going to be a comparatively tough sell vs. something that can throw and entire laptop TDP at a single PCIe card; and unless the entire PC market rushes to throw out existing hardware at a striking rate there’s going to be at least several years of incentive to make things work without a dedicated NPU; and probably at least one or two more where MS’ baseline for local NPU tricks will be constrained by the fact that they sold the Qualcomm systems as adequate; so anything that chokes and dies at 40 will be a niche sell.
I’d rather have more P-Cores than that AI stuff, I don’t really see any use for it. I don’t really see any use for it, and most AI stuff is run in “the cloud” anyways so they can siphon the data. This just seems like an attempt to jump on a hype train together with Microsoft to sell Windows 11 which is also chock-full of spyware and juice the stock price in the process. Pass.
This seems rather interesting, as it is finally a jump from the curent 8 core / 12 CU design, and while I don’t care much about the AI accelerators, this jump could make a switch worthwhile.
@Y0s Unlinke Intel’s P and E cores, Zen 5C core are essentially regular Zen 5 cores. The main difference is optimization for lower clock speeds, i.e. enabling the use of denser transistor libraries for cheaper manufacturing. That’s why they get the same IPC out of the “different” cores and don’t run into software issues as Intel does.