
MLPerf Inference is perhaps the more exciting of the MLPerf benchmarks. While training sometimes has a large cluster from Google or Microsoft, the inference side lends itself better to the proliferation of AI hardware that fits in unique power budgets or that is optimized for specific models. With the new v4.0 suite, MLPerf added a Stable Diffusion image generation and a Llama 2 70B (checkpoint licensed by Meta for benchmarking) test. Still, it is primarily a NVIDIA affair.
NVIDIA MLPerf Inference v4.0 is Out
MLPerf Inference v4.0 now uses larger models.

The Llama 2 70B and the Stable Diffusion XL models are the big new workloads added to the suite. Both are highly relevant today.
MLPerf has options for both server throughput and latencies. Generally, in the “server” set we see the Hopper and Ada Lovelace NVIDIA data center parts. In the edge, we get some of the Ada Lovelace generation. More importantly, we also get all of the companies doing tests on Raspberry Pi’s, NVIDIA Jetson, CPUs, and more.

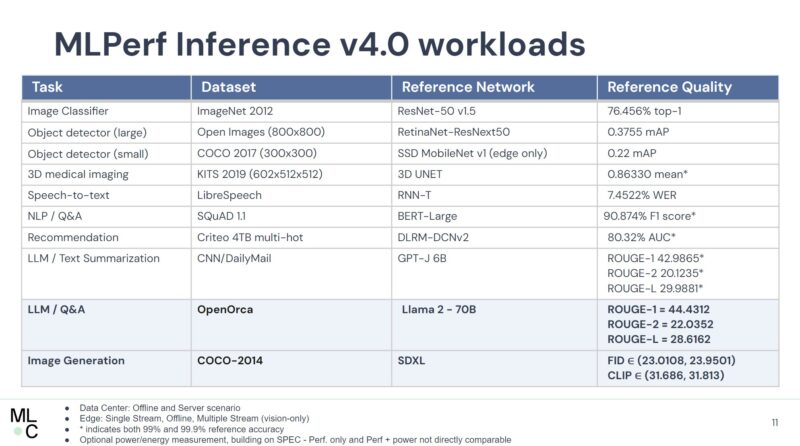
Intel put its Gaudi 2 parts into this iteration. Google had a single TPU v5e result. In the MLPerf results, NVIDIA was much faster on a per-accelerator basis but was potentially better on a performance-per-dollar basis. Based on this, a NVIDIA H100 seems to be in the 2.75-2.8x the cost of the Gaudi 2. Intel has already discussed Gaudi 3 so we expect that to make its way into future versions.
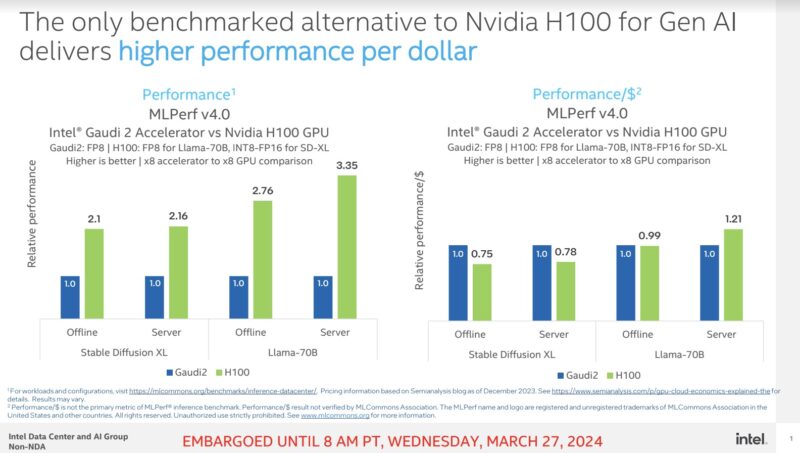
Intel also submitted its CPUs. While dedicated accelerators are faster, the CPU AI performance will become a vital baseline metric as we advance, as this is the “free” AI performance in servers that helps determine if a dedicated AI accelerator will be deployed.
Qualcomm Cloud AI cards showed up again. MLPerf seems to be Qualcomm’s primary marketing tool. It has a new deal with Cerebras and its WSE-3 AI Chip, so Cerebras can do the training, and Qualcomm can provide inferencing hardware. OEMs have told us they are interested in Qualcomm to get leverage over NVIDIA. Realistically, what has happened, however, is that for many customers, it is hard to get off the NVIDIA bandwagon. Better said, OEMs do not have much leverage over NVIDIA, even if they offer Qualcomm Cloud AI parts. Instead, customers looking to deploy servers for inference over a 3-5-year horizon usually use NVIDIA because it is the safe choice.

Qualcomm would be better off using the Cerebras model of not submitting to MLPerf for marketing. Currently, it is trying to use logic against what has effectively become NVIDIA’s benchmark project. Customers focus on the emotional side of knowing NVIDIA will be all things AI. That asymmetric marketing approach rarely works. Let us make it easier. STH is the largest server, storage, and networking review site around, and our YouTube channel is fairly big, with 500K YouTube subs. We have been reviewing multi-GPU AI servers since ~2017 or so. We have never had a server vendor tell us there is such demand for Qualcomm parts that they need reviews of the solution. That is shocking and telling at the same time.
On the edge side, the NVIDIA Jetson Orin 64GB made quite a few appearances. We just did a NVIDIA Jetson Orin Developer Kits the Arm Future Video. In anticipation of this.
This was also the first time we saw a Grace Hopper result in MLPerf Inference. NVIDIA just released Blackwell and made it clear that the highest-end AI training and inference servers will be Arm + Blackwell in 2025 (Cerebras aside.)
Final Words
We know that the AMD MI300X is a multi-billion dollar product line this year. We know that Cerebras has a $1B+ revenue training solution. We do not know the exact size of the Intel Gaudi market, but we know they were supply-constrained in 2023 and have a new Gaudi 3 part for 2024. The MI300X, Gaudi 3, and Cerebras were no-shows on the latest MLPerf results in the server market.
While we did get a single Google TPU v5e result and a handful of Qualcomm results, this is still a NVIDIA-dominated benchmark. NVIDIA dominates the AI conversation, so perhaps that makes sense. For most vendors, it seems the strategy of just staying away from MLPerf benchmarking has not inhibited success since it is so heavily NVIDIA.



{kind=link}
“NVIDIA MLPerf Inference v4.0 is Out”
Pretty BS-y title. There are dozens of companies that form the consortium. The fact that one company dominates isn’t Nvidia’s problem, it’s everyone else’s.