
Today we wanted to discuss cloud native and efficient computing. Many have different names for this, but it is going to be the second most important computing trend in 2024, behind the AI boom. Modern performance cores have gotten so big and fast that there is a new trend in the data center: using smaller and more efficient cores. Over the next few months, we are going to be doing a series on this trend.
As a quick note: We get CPUs from all of the major silicon players. Also, since we have tested these CPUs in Supermicro systems, we are going to say that they are all sponsors of this, but it is our own idea and content.
The Shift Has Started… Even if You Are Missing It
Let us get to the basics. Once AMD re-entered the server market (and desktop) with a competitive performance core in 2017, performance per core and core counts exploded almost as fast as pre-AI boom slideware on the deluge of data. As a result, cores got bigger, cache sizes expanded, and chips got larger. Each generation of chips got faster.

Soon, folks figured out a dirty secret in the server industry: faster per core performance is good if you license software by core, but there are a wide variety of applications that need cores, but not fast ones. Today’s smaller efficient cores tend to be on the order of performance of a mainstream Skylake/ Cascade Lake Xeon from 2017-2021, yet they can be packed more densely into systems.
Consider this illustrative scenario that is far too common in the industry:
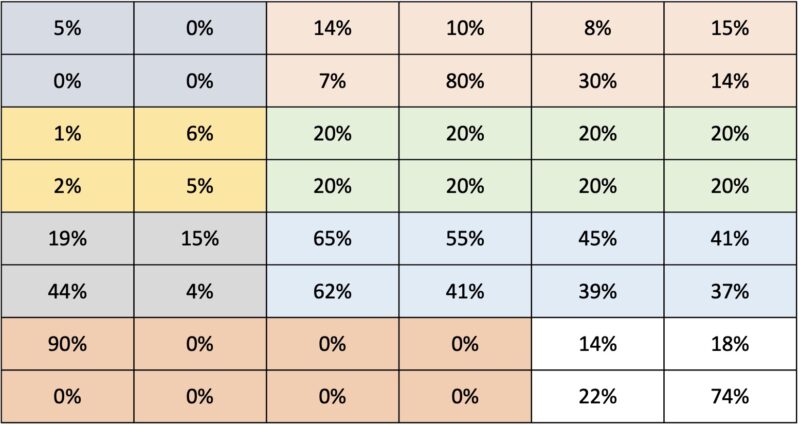
Here, we have several apps built by developers over the years. Each needs its own VM and each VM is generally between 2-8 cores. These are applications that need to be online 24×7 but are not ones that need massive amounts of compute. Good examples are websites that serve a specific line of business function but do not have hundreds of thousands of visitors. Also, these tend to be workloads that are already in cloud instances, VMs, or containers. As the industry has started to move away from hypervisors with per-core licensing or per-socket license constraints, scaling up to bigger, faster cores that are going underutilized makes little sense.
As a result, the industry realized it needed lower cost to produce chips that are chasing density instead of per-core performance. An awesome way to think about this is to think about trying to fit the maximum number of instances for those small line-of-business applications developed over the years that are sitting in 2-8 core VMs into as few servers as possible. There are other applications like this as well that are commonly shown such as nginx web servers, redis servers, and so forth. Another great example is that some online game instances require one core per user in the data center, even if that core is relatively meager. Sometimes just having more cores is, well, “more cores = more better.”
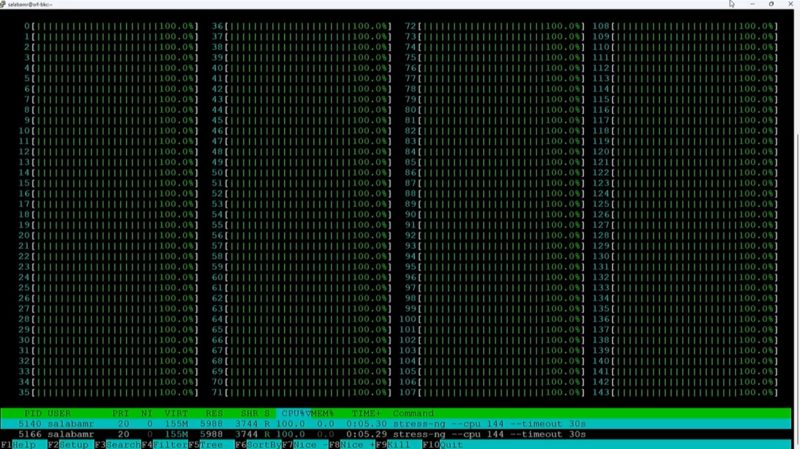
Once the constraints of legacy hypervisor per core/ per socket licensing are removed, then the question becomes how to fit as many cores on a package, and then how dense those packages can be deployed in a rack. One other trend we are seeing is not just more cores, but also lower clock speed cores. CPUs that have a maximum frequency in the 2-3GHz range today tend to be considerably more power efficient than those with frequencies of P-core only servers in the 4GHz+ range and desktop CPUs now pushing well over 5GHz. This is the voltage frequency curve at work. If your goal is to have more cores, but do not need maximum per-core performance, then lowering the performance per core by 25% but decreasing the power by 40% or more, means that all of those applications are being serviced with less power.

Less power is important for a number of reasons. Today, the biggest reason is the AI infrastructure build-out. If you, for example, saw our 49ers Levi’s Stadium tour video, that is a perfect example of a data center that is not going to expand in footprint and can only expand cooling so much. It also is a prime example of a location that needs AI servers for sports analytics.
That type of constraint where the same traditional work needs to get done, in a data center footprint that is not changing, while adding more high-power AI servers is a key reason cloud-native compute is moving beyond the cloud. Transitioning applications running on 2017-2021 era Xeon servers to modern cloud-native cores with approximately the same performance per core can mean 4-5x the density per system at ~2x the power consumption. As companies release new generations of CPUs, the density figures are increasing at a steep rate.
We showed this at play with the same era of servers and modern P-core servers in our 5th Gen Intel Xeon Processors Emerald Rapids review.
We also covered the consolidation just between P-core generations in the accompanying video. We are going to have an article with the current AMD EPYC “Bergamo” parts very soon in a similar vein.
If you are not familiar with the current players in the cloud-native CPU market, that you can buy for your data centers/ colocation, here is a quick run-down.
AMD EPYC “Bergamo” and Siena
The AMD EPYC “Bergamo” was AMD’s first foray into cloud-native compute. Onboard, it has up to 128 cores/ 256 threads and is the densest publicly available x86 server CPU currently available.

AMD removed L3 cache from its P-core design, lowered the maximum all core frequencies to decrease the overall power, and did extra work to decrease the core size. The result is the same Zen 4 core IP, with less L3 cache and less die area. Less die area means more can be packaged together onto a CPU.

Some stop with Bergamo, but AMD has another Zen 4c chip in the market. The AMD EPYC 8004 series, codenamed “Siena” also uses Zen 4c but with half the memory channels, less PCIe Gen5 I/O and single-socket only operation.

Some organizations that are upgrading from popular dual 16 core Xeon servers can move to single socket 64-core Siena platforms and stay within a similar power budget per U while doubling the core count per U using 1U servers.

AMD markets Siena as the edge/ embedded part, but we need to recognize this is in the vein of current gen cloud native processors.
Ampere Altra Max / AmpereOne
Arm has been making a huge splash into the space. The only Arm server CPU vendor out there for those buying their own servers, is Ampere led by many of the former Intel Xeon team.

Ampere has two main chips, the Ampere Altra (up to 80 cores) and Altra Max (up to 128 cores.) These use the same socket and so most servers can support either. The Max just came out later to support up to 128 cores.

Here, the focus on cloud-native compute is even more pronounced. Instead of having beefy floating point compute capabilities, Ampere is using Arm Neoverse N1 cores that focus on low power integer performance. It turns out, a huge number of workloads like serving web pages are mostly integer performance driven. While these may not be the cores if you wanted to build a Linpack Top500 supercomputer, they are great for web servers. Since the cloud-native compute idea was to build cores and servers that can run workloads with little to no compromise, but at lower power, that is what Arm and Ampere built.

Next up will be the AmpereOne. This is already shipping, but we have yet to get one in the lab.

AmpereOne uses a custom designed core for up to 192 cores per socket.
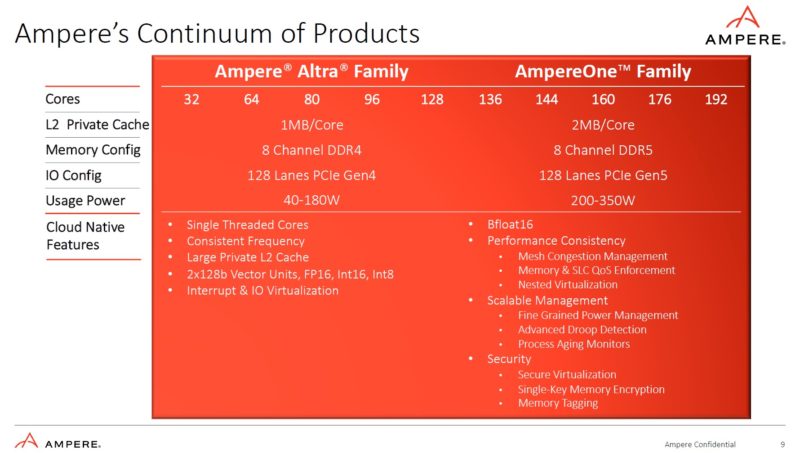
Assuming you could buy a server with AmpereOne, you would get more core density than an AMD EPYC “Bergamo” server (192 vs 128 cores) but you would get fewer threads (192 vs 256 threads.) If you had 1 vCPU VMs, AmpereOne would be denser. If you had 2 vCPU VMs, Bergamo would be denser. SMT has been a challenge in the cloud due to some of the security surfaces it exposes.
Intel Sierra Forest Preview
Next in the market will be the Intel Sierra Forest. Intel’s new cloud-native processor will offer up to 144/ 288 cores. Perhaps most importantly, it is aiming for a low power per core metric while also maintaining x86 compatibility.

Intel is taking its efficient “E-core” line and bringing it to the Xeon market. We have seen massive gains in E-core performance in both embedded as well as lower-power lines like the Alder Lake-N where we saw greater than 2x generational performance per chip. Now, Intel is splitting its line into P-cores for compute intensive workloads and E-cores for high-density scale-out compute.
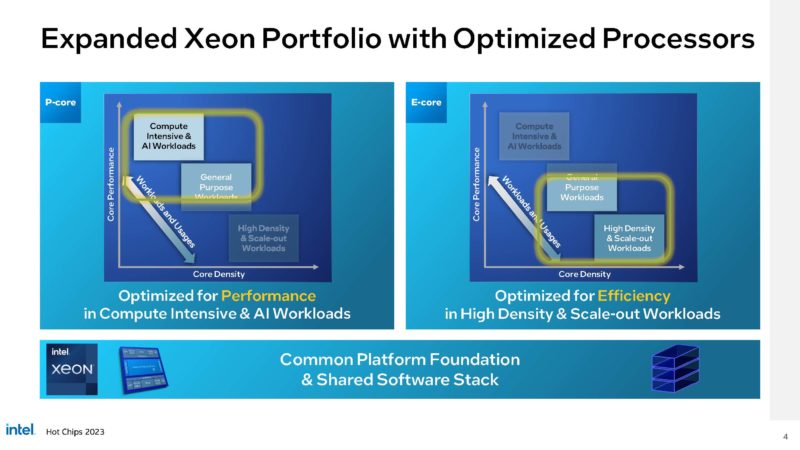
Intel will offer Granite Rapids as an update to the current 5th Gen Xeon “Emerald Rapids” for all P-core designs later in 2024. Sierra Forest will be the first generation all E-core design and is planned for the first half of 2024. Intel already has announced the next generation Clearwater Forest will continue the all E-core line. As a full disclosure, this is a launch I have been excited about for years.
NVIDIA Grace is Onto Something
We are going to quickly mention the NVIDIA Grace Superchip here. With up to 144 cores across two dies packaged along with LPDDR memory.

While at 500W and using Arm Neoverse V2 performance cores, one would not think of this as a “cloud native” processor, it does have something really different. The Grace Superchip has onboard memory packaged alongside its Arm CPUs. As a result, that 500W is actually for CPU and memory. There are applications that are primarily memory bandwidth bound, not necessarily core count bound. For those applications, something like a Grace Superchip can actually end up being a lower-power solution than some of the other cloud-native offerings. These are also not the easiest to get, and are priced at a significant premium. One could easily argue these are not cloud-native, but if our definition is doing the same work in a smaller more efficient footprint, then the Grace Superchip might actually fall into that category for a subset of workloads.
Final Words
If you were excited for our 2nd to 5th Gen Intel Xeon server consolidation piece, get ready. To say that the piece we did in late 2023 was just the beginning would be an understatement.

While many are focused on AI build-outs, projects to shrink portions of existing compute footprints by 75% or more are certainly possible, making more space, power, and cooling available for new AI servers. Also, just from a carbon footprint perspective, using newer and significantly more power-efficient architectures to do baseline application hosting makes a lot of sense.
The big question in the industry right now on CPU compute is whether cloud native energy-efficient computing is going to be 25% of the server CPU market in 3-5 years, or if it is going to be 75%. My sense is that it likely could be 75%, or perhaps should be 75%, but organizations are slow to move. So at STH, we are going to be doing a series to help overcome that organizational inertia and get compute on the right-sized platforms.



{kind=link}
Since these efficiency cores are as fast as older performance cores, a cloud provider can rent them out for the same or less than their current x86 offerings. Conversely, it will be difficult to charge more for performance cores unless they suddenly become very good at the matrix maths used to train and realise neural networks.
The AMD Opteron 6000 series was really the first to explore this concept, of less powerful cores at high core density. It was ahead of its time in that regard.