
Moffett AI showed off its new AI inference SoC at Hot Chips 2023. We have previously seen Moffett in MLPerf Inference v3.0 and previous generations.
Please excuse typos, this is being written live at the conference.
Moffett Antoum AI Inference Accelerator at Hot Chips 2023
Moffett says that lately, we are seeing many more large language models while the image or computer vision module explosion happened years ago.
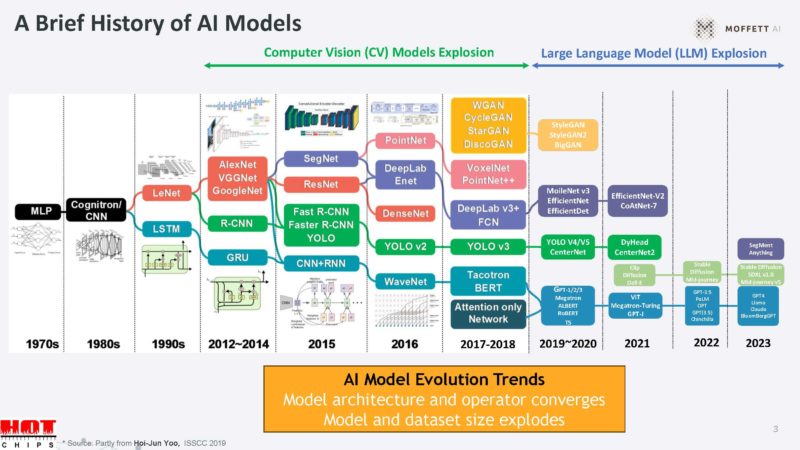
These models have different training data set sizes. Here is an example of the differences. Usually, computer vision models are very small while the input sizes are very large. Language models are very different.
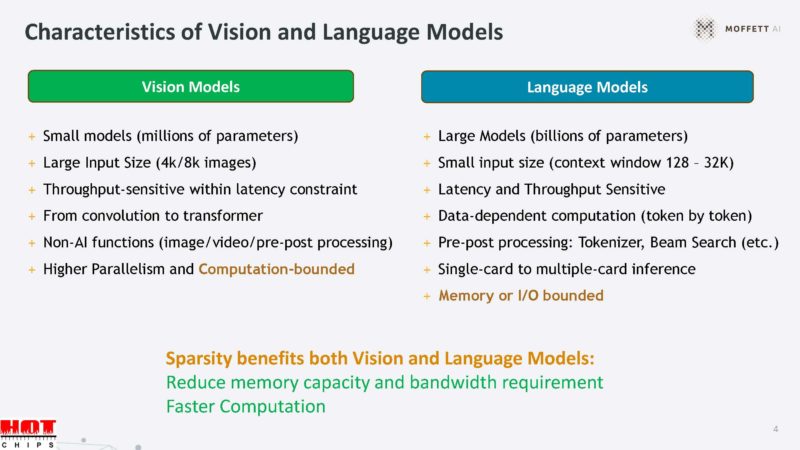
The Moffett Antoum is designed for sparsity in models both vision and language models.
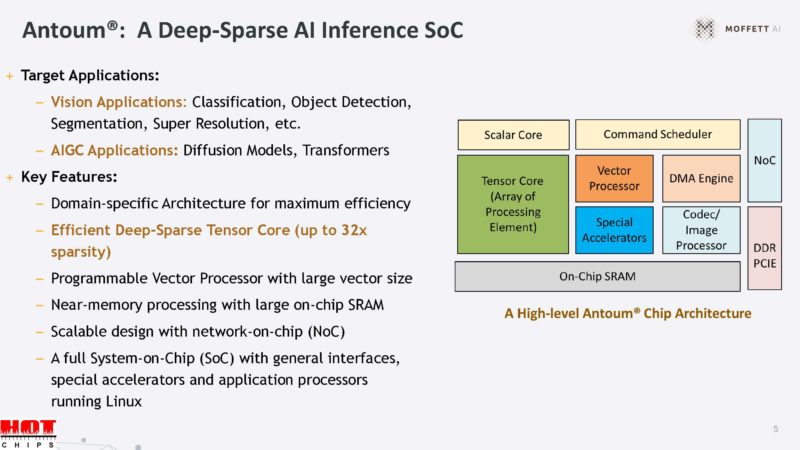
The quad core CPU can run Linux.
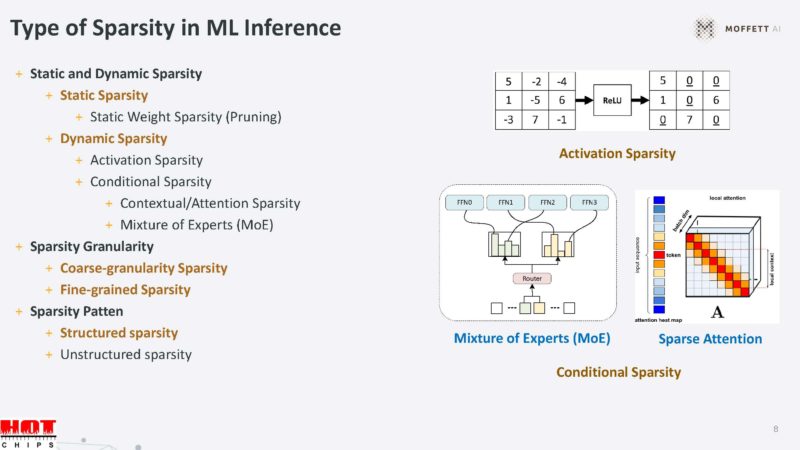
Sparsity exists in tensor algebra because zeros occur naturally in the operation.
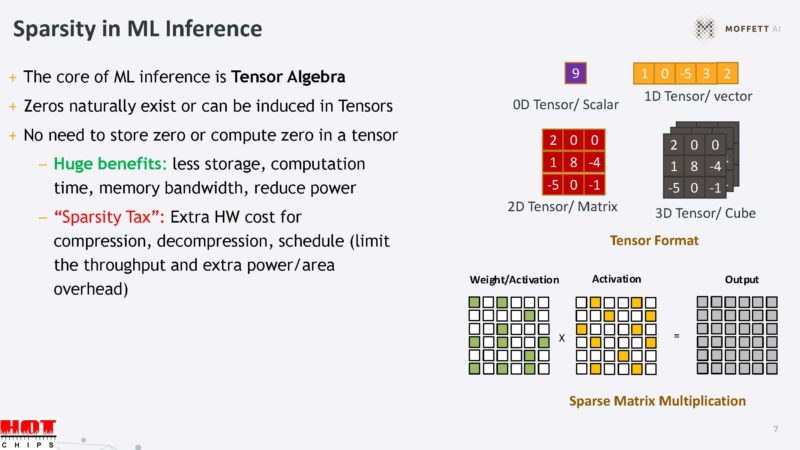
Sparsity can happen in weight sparsity that is well-known. There are also opportunities to exploit sparsity in the input data, conditional sparsity, and more.
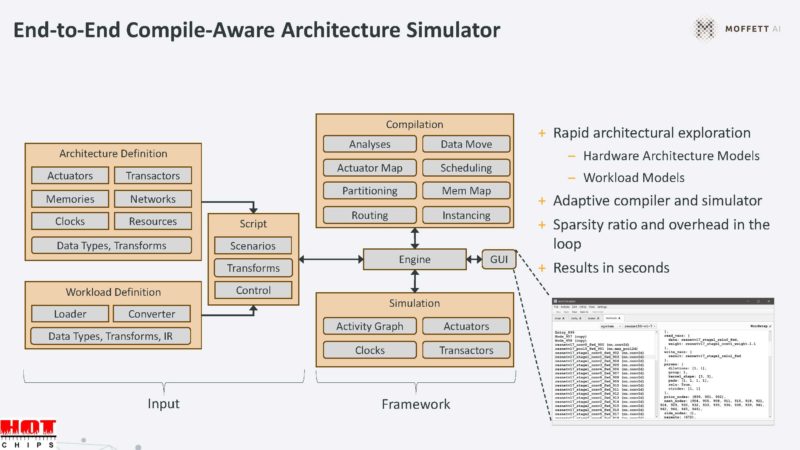
Moffett is using a compile aware simulator to see how to map models and sparsity to its accelerators.
This is the SoC architecture. Since it is using sparsity, it can have slower external interfaces like PCIe Gen3.
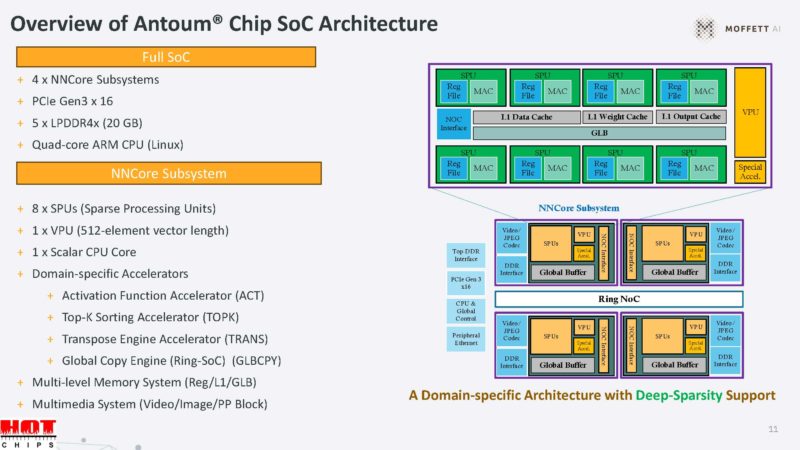
Going into some of these blocks will be the next.
Within the NNCore subsystem, of which there are four on the chip, there is a SPU. SPU stands for sparse processing unit.
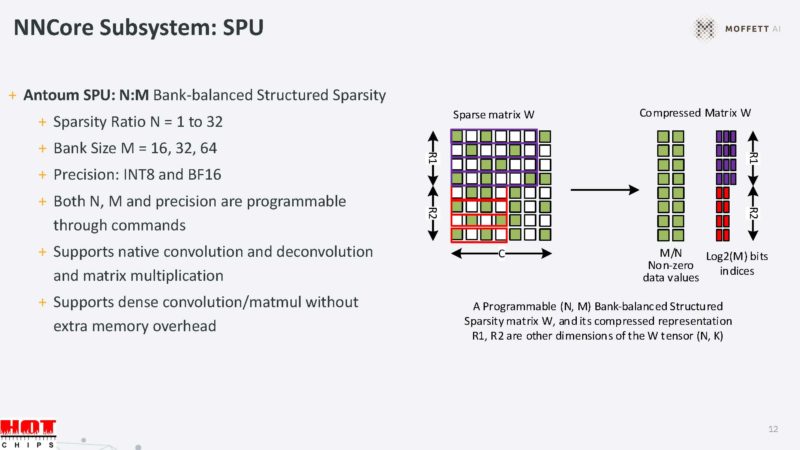
Here is the SPU clusters datapath. This one is a fairly complex and dense slide that I am not going to have time to transcribe.
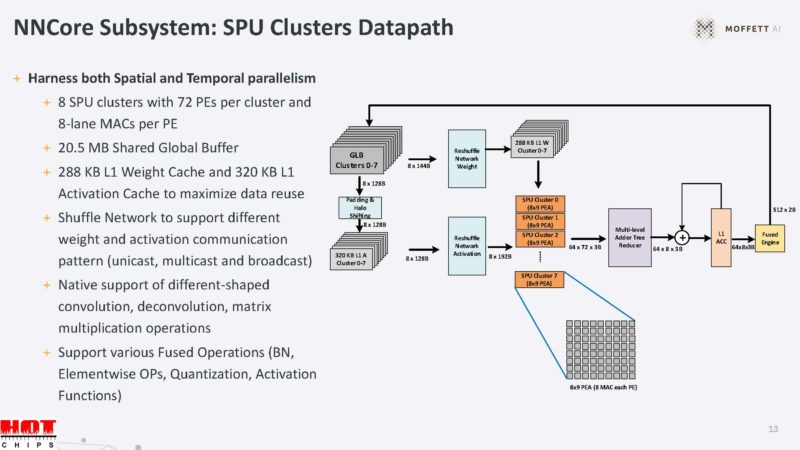
The NNCore also has a custom Vector Processing Unit or VPU to do vector processing and can handle INT8 and FP16 data types.
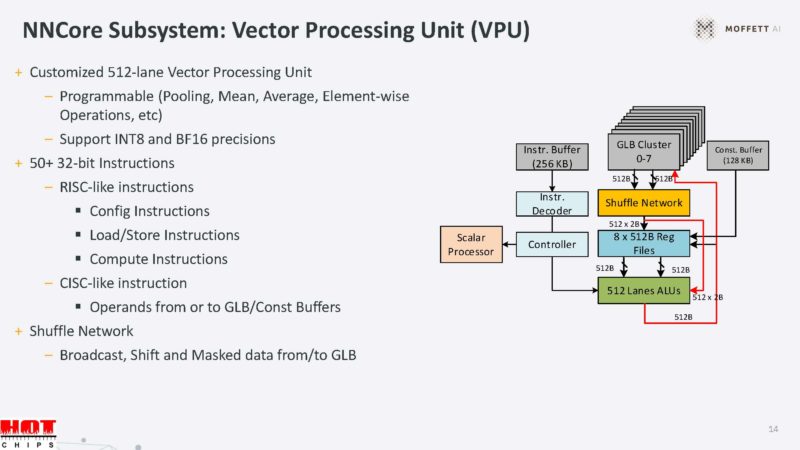
There are also domain-specific accelerators.
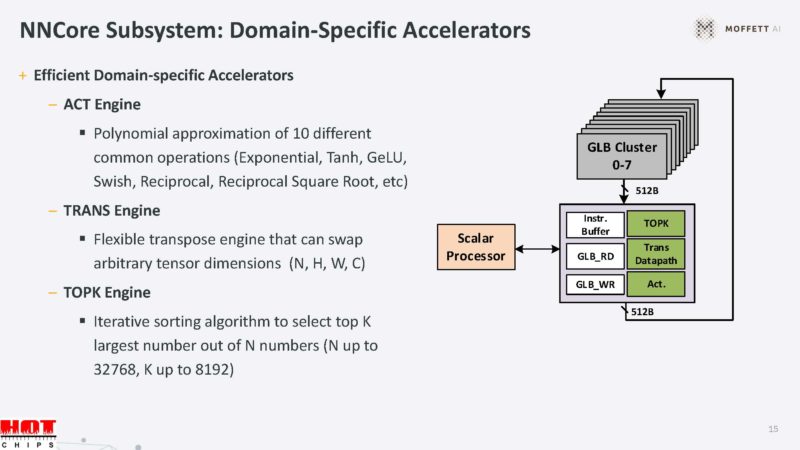
There is a core-to-core interconnect to move data around and do things like share caches.
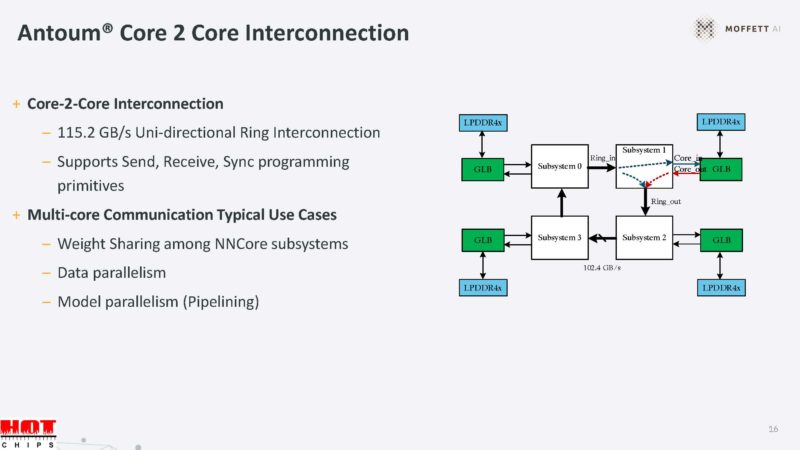
The hybrid sparsity helps accelerate sparse LLM’s.
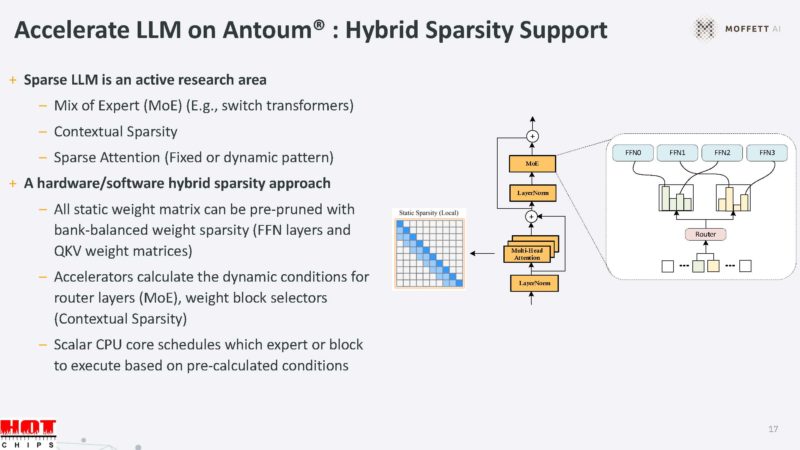
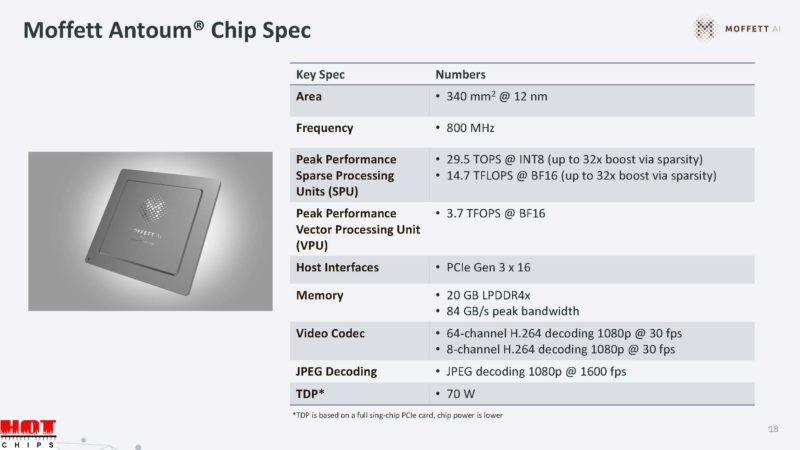
Here are the key specs, including a 70W TDP and 800MHz frequency.
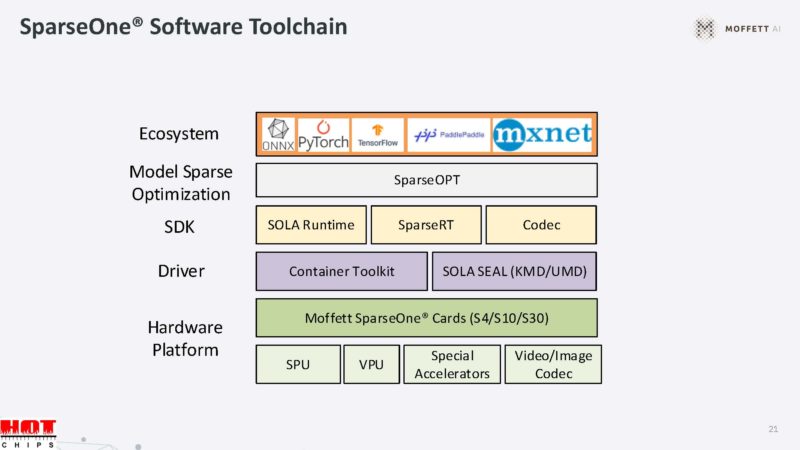
Here are the SparseOne AI inference cards.

Moffett has SparseOne toolchain to run models on its cards.
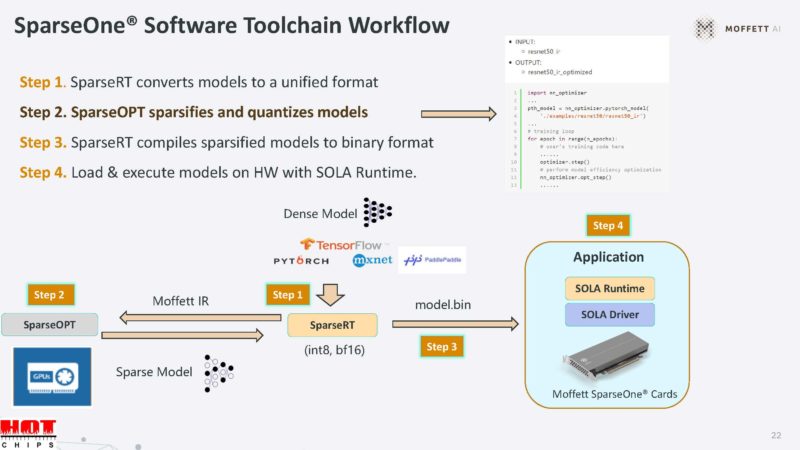
Here is a bit more about the toolchain. It seems like Moffett is using half of its talk or so on software which is usually a good sign.
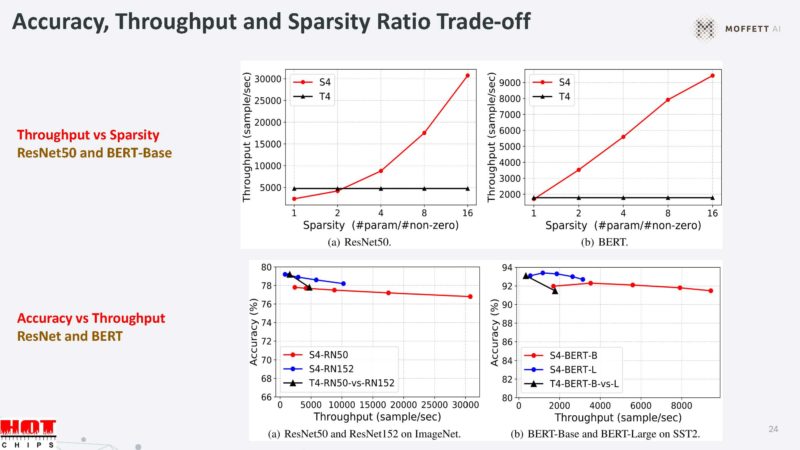
Sparsity can be traded for throughput, and also accuracy for throughput. The benchmarks seem to show that the Moffett S4 is faster than the NVIDIA Tesla T4.
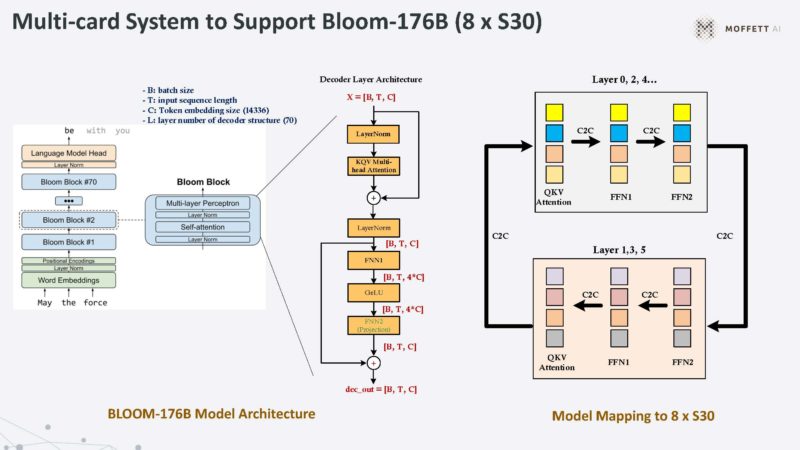
This is Moffett’s multi-card solution.
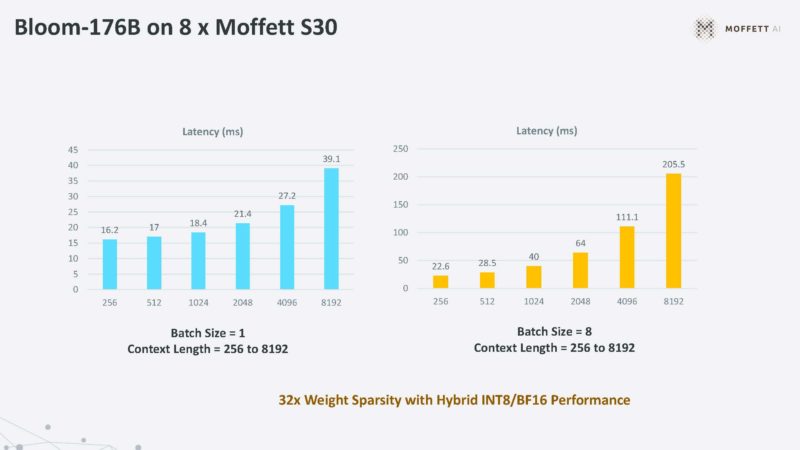
Here is the performance of 8x Moffett S30 cards.
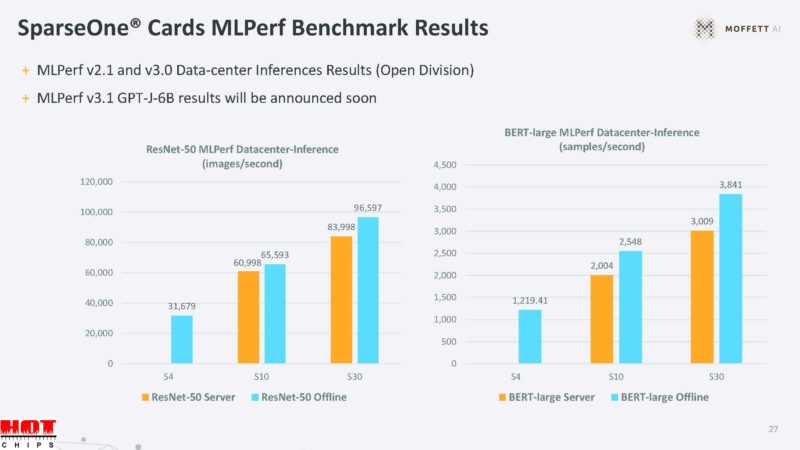
Moffett cannot use sparsity in the MLPerf closed division, so it has to be submitted in the open category.
This was the demo.

Here is the super-resolution increase from 9fps to 59fps in this demo at similar quality.

There is another demo.

And another one.

Here is the summary wall of text.

Final Words
Overall these are cool accelerators. The bigger question is who are the customers for its AI parts today, and who will be the customers in the future. Cerebras, for example, has announced ~$1B in deal value over the next 18 months.
Still, it will be interesting to see how this develops.



{kind=link}