
A few weeks ago, we had a piece looking at the impact of acceleration on performance. The goal of that piece was really to show our readers that acceleration is important, and it is going to become a bigger part of the computing landscape in the future. Since then, AWS announced its new Graviton3 processor with more acceleration. Those instances are still not GA, but some feedback we received was to do a bit of a deep dive into acceleration on today’s processors. There are many people still with “acceleration hesitancy” that are not using existing hardware accelerators in CPUs. While many take off for the holiday season, some use free time for learning and fun projects, and this may be one of them.
This is also important from a broader perspective. Utilizing accelerators means one can do more work with existing resources. That means lower costs and fewer servers being required to run in a data center somewhere. Using acceleration will be a trend akin to upcycling in the recycling world. As folks can probably tell, at STH we are stepping up our campaign against acceleration hesitancy with these pieces.
Here is the video version of this piece if you prefer to just listen along. As always we advise opening this in its own tab or app for the best viewing experience:
Just to be perfectly clear, this is using AWS EC2 m6i.4xlarge instances, but the same will apply to bare metal servers. As with the last piece, I wanted to thank Intel specifically for this. They are paying for the instances and providing support for making sure things are set up properly. As a result, we are going to say this is sponsored. At the same time, like everything on STH, we are running the testing and writing/ publishing without Intel’s supervision because everything on STH is editorially independent. We just want to note that this is a collaboration because realistically, it would be bad to get an incorrect result here and share it broadly.
What I also wanted to do was link to a few of the guides I found while setting this up. Instead of going into tutorials on each one, my thought was to link the resources. Again, Intel is not paying for these links, I just did not want to re-write existing documentation since that seems superfluous. My thought is that the big impact is that our readers can see this, and get inspired to use whatever they have (cloud or bare metal) over the holidays to get ahead for 2022.
WordPress MariaDB Using HTTPS Acceleration
Since the last piece, some folks asked for a bit more on a deep dive focusing on just the Ice Lake Xeon acceleration. That is a very valid point and one that we wanted to go into. Again, this is based on oss-performance and is using WordPress, NGINX with php-fpm, and MariaDB as the database. Cypher wise we are using TLS_AES_256_GCM_SHA384 and this is being done on Ubuntu 20.04.3 LTS. The point of this one was not to test the maximum crypto acceleration but instead is to show a fairly common setup where a portion of the workload is accelerated.
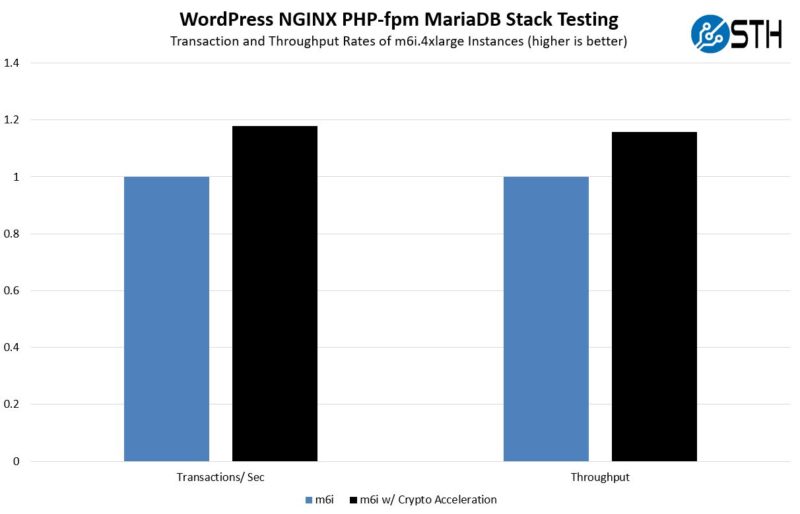
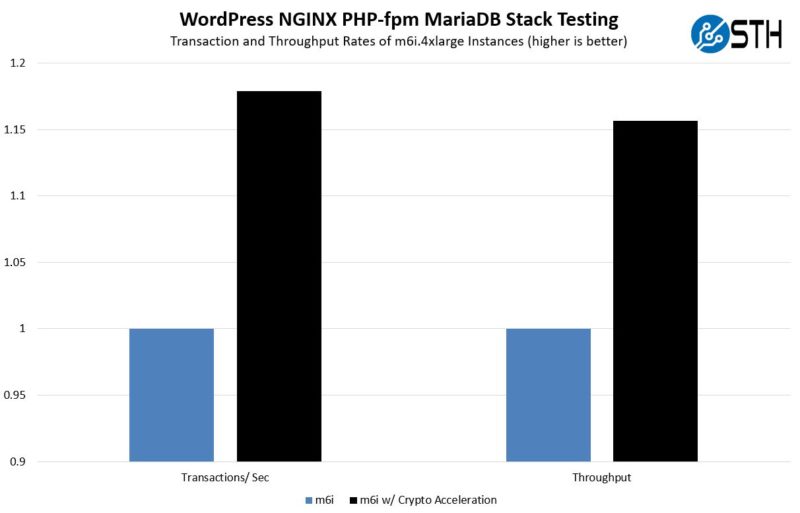
As we can see, the transactions per second and throughput were up by 15-18% overall. On one hand, this is not a 4x speedup like if we tested crypto-acceleration alone, but on the other hand it is enough that you effectively get an extra m6i.4xlarge instance’s performance for every six instances that are using acceleration versus not using acceleration. Here is a zoomed-in view with a non-zero Y-axis so you can see the detail a bit better:
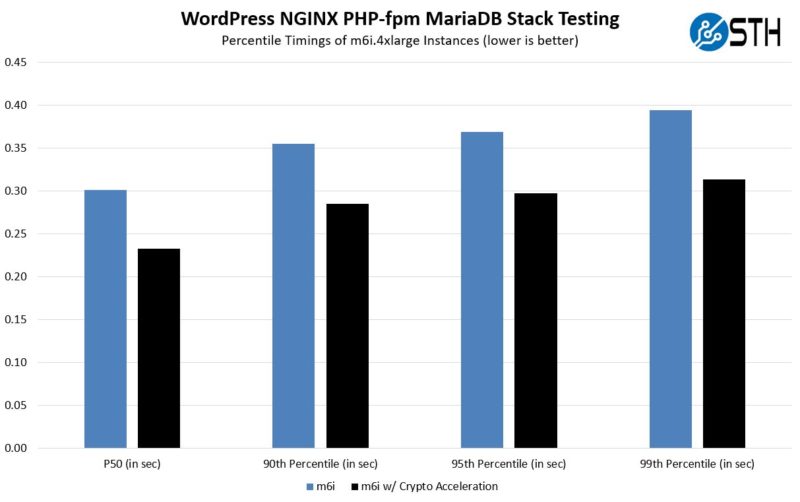
Perhaps the biggest one here is the latency. The transactions per second and throughput numbers were good, but when we actually look at the accelerated version, we see a fairly massive drop in latency across the spectrum. Many will care as much, if not more, about latency versus throughput so this is important. We had a few users ask if there was a big latency hit to use the accelerators instead of the general-purpose compute path. This is a good example of where that is not the case (we will look at latency in the TensorFlow example as well.)
In terms of difficulty, to implement over a holiday break, this one is certainly doable. If you want to check out the guide to getting nginx and HTTPS acceleration, here is a whitepaper on that part. That actually goes into more detail than what we are doing here since it goes into network interrupt connectivity, but it has 3-4 pages of instructions on how to start using acceleration. Intel also has similar guides if you have QAT cards or other accelerators.
Again, the benefits here are very large so we expect to see more CPUs offer offloads for accelerating HTTPS in 2022, this is just something we could show today.
TensorFlow Using AI Kit for Analytics
The background for this one is that we often look at AI acceleration as a maximum performance per instance or per part number. As we are seeing AI become part of more applications, what we are also seeing is that AI inference is now a part of many workloads. While many may automatically see AI and think GPU, the other side of this is that it can be cheaper and faster to do small amounts of inference in applications on the CPU. That means lower-cost CPU instances can be used and alternatively one may not need to traverse the network to a GPU instance for inference. Here, we want to look at latency for infrequent requests.
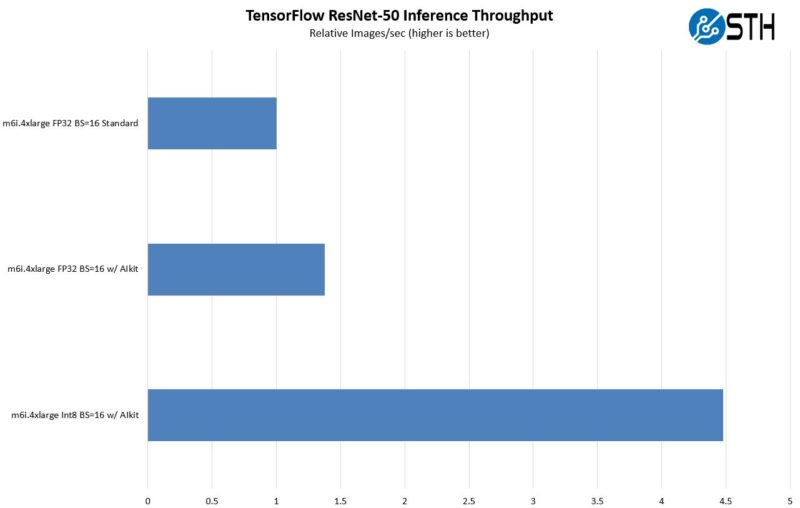
First, we are looking at FP32 inference using a batch size of 16. This is more akin to what we see normally shown in benchmarks. Here, we get a good speedup by using AI kit and getting access to the acceleration. The big one though is swapping to INT8 as the data type. INT8 is a much less computationally expensive data type and therefore we can see some fairly massive gains. This is one where it is going to be used more in the future just because folks have found that it offers a small accuracy penalty yet significantly better performance. Again, this is a 2022 trend we will see in more CPUs.
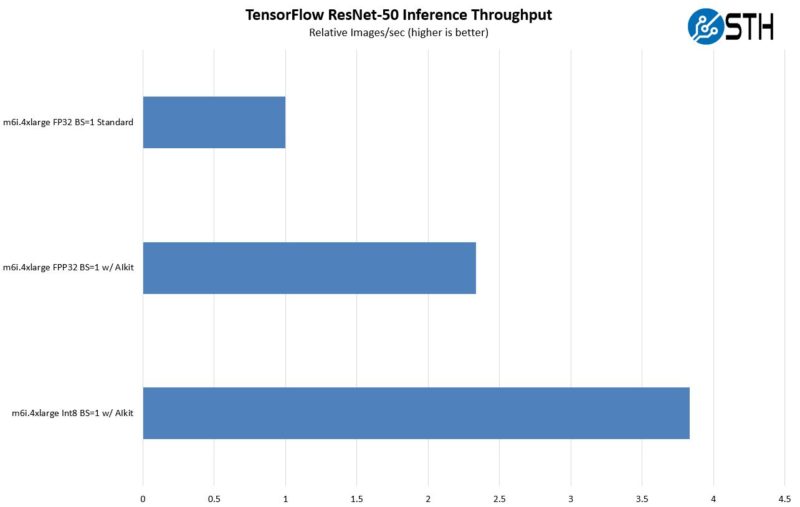
Looking at the batch size = 1 numbers, one can see the impact when an application needs to call inferencing and get an immediate result. Larger batch sizes are for maximum throughput while BS=1 is more of a latency test. Here we see a fairly big benefit from moving to the accelerators, and another benefit from moving to INT8. That impact is actually a bit less than we saw on the larger batch size, but still very pronounced.
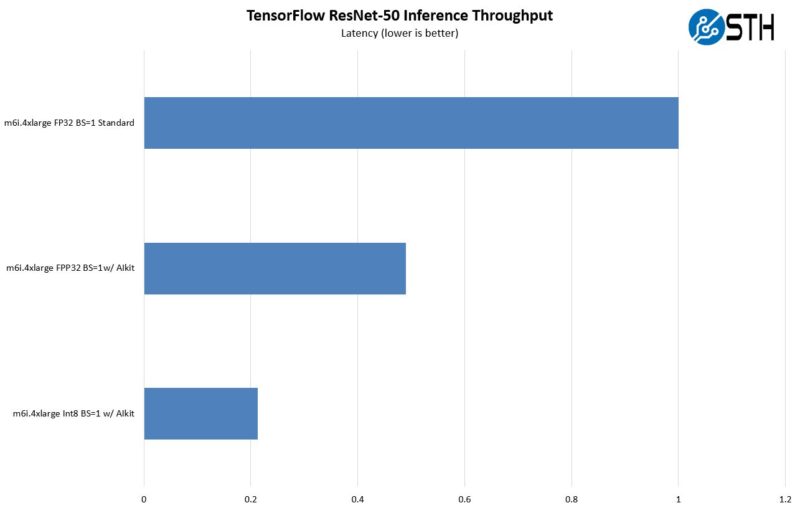
The big one though is in terms of latency. Here, is the eye-popping chart. The inference latency is much lower with the AI Kit acceleration path and again with INT8. As one can see, with INT8 and BS=1 we get around 80% lower latency than we had with FP32 and without using the acceleration. That is a big delta.
Since Intel has a number of AI accelerator technologies including CPUs, FPGAs, dedicated ASICs, and soon GPUs, the company is using its oneAPI software ecosystem to make things easier. If you want to get started on this, here is the best reference we could find. In theory, the vision Intel has for oneAPI is that it will be one interface to access acceleration no matter the piece of silicon. This is more of a read, but it is specific for Tensorflow and Ice Lake Xeons.
NAMD and Hyper-Threading Using AVX-512
Finally, we wanted to discuss NAMD and using AVX512 and Hyper-Threading. For this, instead of going extremely unoptimized, the base case is going to be with AVX2. NAMD is typically used in the high-performance computing space and those folks are very good at taking advantage of optimizations. The first case we are going to use is the ApoA1 lipid, protein, and water benchmark.
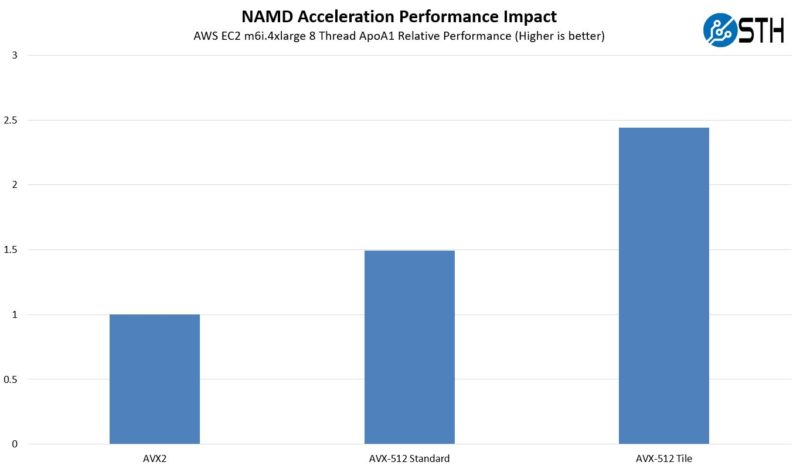
Here we can see that using AVX-512 we got around a 50% speedup. Then using a tile algorithm (more similar to what is used on GPUs) with AVX-512 we get almost a 2.5x speedup. This is using 8-threads of the 16 available in the AWS m6i.4xlarge instance. This is the impact with all sixteen threads:
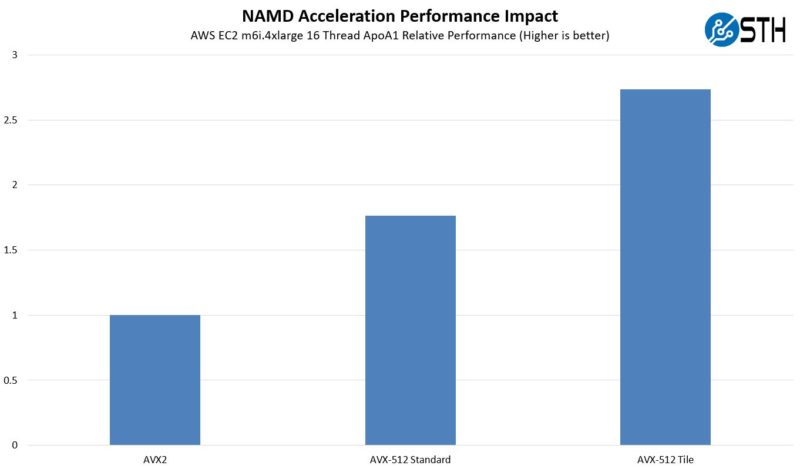
Of course, with these HPC workloads, usually hyper-threading is often not used in order to increase performance. Hyper-Threading does well on other workloads, especially in the enterprise/ cloud side, but on the HPC side, often we see HT not being used. Here is the relative performance of what we saw using the 16 thread AVX2 result as our base of 1:
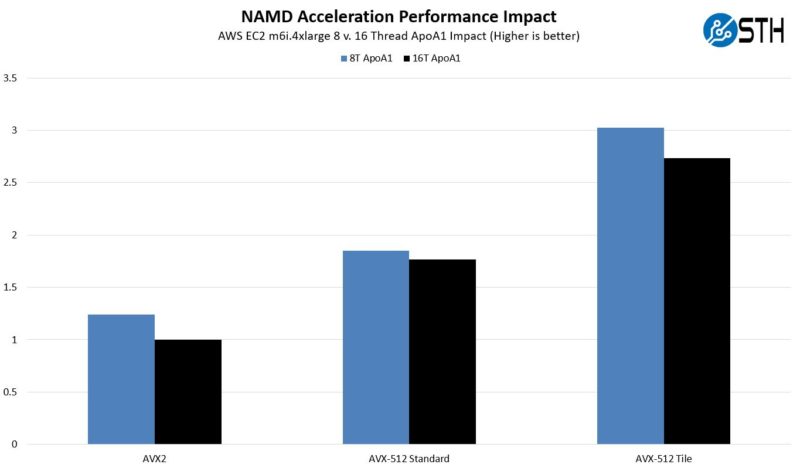
Interestingly, the non-tile AVX-512 case was fairly close in performance, but both the AVX2 and tile cases were further apart when we ran 16 threads versus 8 threads.
Just to get a bit of diversity here, we wanted to also take a look at the STMV case, another common benchmark. STMV stands for satellite tobacco mosaic virus. In this case, a satellite is not something in outer space. Instead, it is a virus that increases the symptoms of another virus and uses both the host virus/cell to reproduce. Folks that are better at molecular biology can feel free to expand on that in the comments. Still, here are the results:
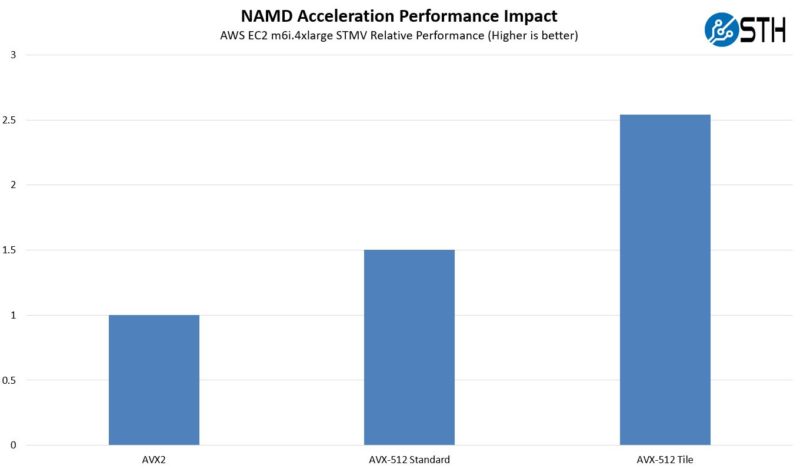
Overall, we see a similar pattern in terms of speed-up. Not every workload is going to be sensitive to Hyper-Threading and AVX-512. Likewise, there are many segments that do not have specialized algorithms and approaches to maximize hardware performance like NAMD. At the same time, this is just an example of a higher-maturity optimization using AVX-512 acceleration that has been out for some time. There is a ton on NAMD optimization out there and one good place to start is the NAMD page at UIUC.
Final Words
The goal of this, before the holidays, is to just give our readers something to think about before we get to 2022. Next year, we are going to see more accelerators built into server and client CPUs. As a result, being acceleration hesitant is going to be a stance that will cost more in the future. On the other hand, it is also an opportunity. Getting into acceleration today means that STH readers can be ahead of the market by a bit and look great at work. 30 minutes of adding NGINX HTTPS acceleration over break can give a “WOW” factor to one’s boss and organization. Since there is a bit of free time ahead, and this is going to be a trend, we wanted to give our readers a heads-up so they can be ahead of the rest of the market on this one.



{kind=link}
“Acceleration hesitancy” ha! Good one.
Looking at the whitepaper I think it’s very problematic that it requires cloning a couple of repositories and building the libraries / software yourself. Why isn’t there an apt repository for this stuff? What happens when there is a security issue in OpenSSL and your software is loading an outdated version from /usr/local?