
Rockport Networks today launched its switchless fabric for HPC and AI clusters. That is right, one does not need big or even smaller switches in order to build a cluster using Rockport’s solution. This is certainly something different in a market where the high-performance Infiniband and Ethernet networking is a very large investment. What is more, Rockport is using something that is not too dissimilar from what STH is deploying in the big fiber project.
Rockport Networks Switchless HPC and AI Cluster Fabric Launched
Rockport’s basic premise is that having large centralized cluster switches becomes expensive and also can have congestion. These can be either large backplane switches, a leaf-spine topology, or something similar.
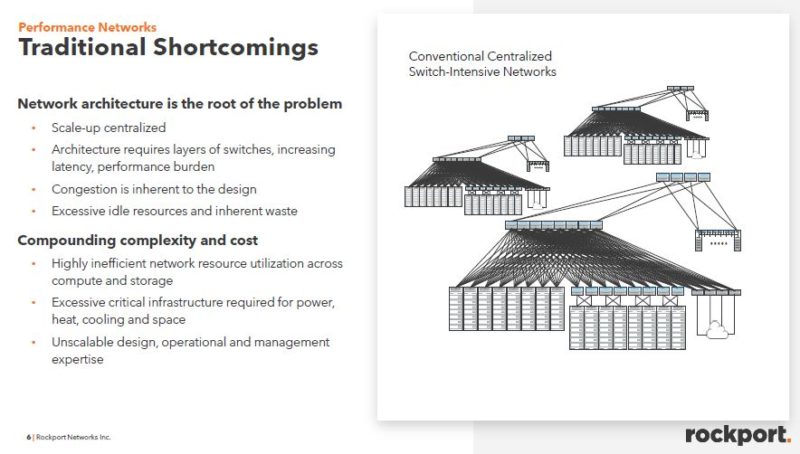
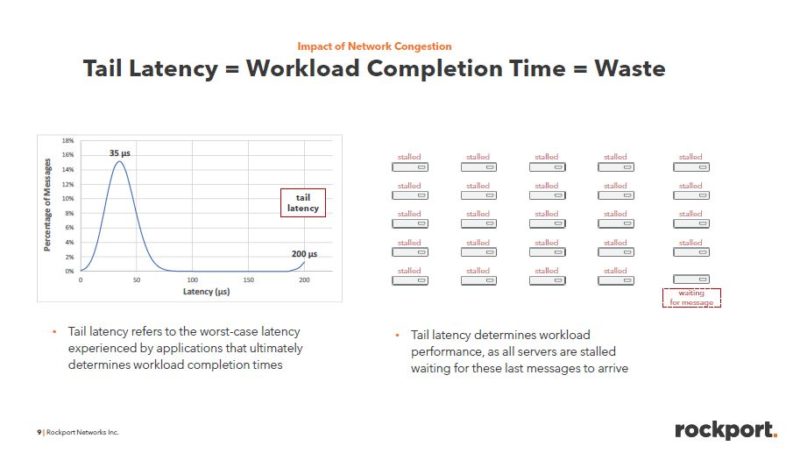
Rockport’s main goal at this point seems to be mitigating congestion that leads to tail latencies. In HPC and AI systems, when a node is waiting for data, it can sit idle. Lowering these tail latencies means that a system in the cluster is not waiting for data and can therefore continue to compute. As a result, lowering tail latencies directly impacts cluster performance even if it is different nodes experiencing high tail latencies.
To do this, Rockport is getting rid of the switch. There are three main components. First, there is an adapter. Second, there is the SHFL (pronounced like “shuffle”) and then the software behind everything to make it work.

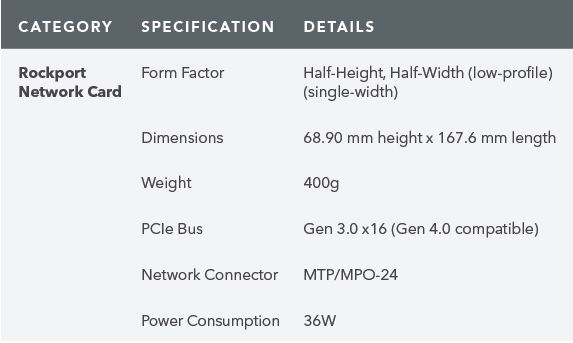
This is the Rockport Networks NC1225. This card has a more traditional vendor IC for the main host network interface at 100Gbps. It then has a FPGA and optical drivers all in a low-profile adapter.

A few quick points here. First, this is a PCIe Gen3 x16 adapter so it cannot handle a 200Gbps full-duplex link to the host. In an era where we are over two years into the PCIe Gen4 cycle and PCIe Gen5 is so close to being in systems, this seems like a bit of a letdown. This would have been an opportunity for a multi-host adapter so that it can interface with two CPUs in a dual-socket server at PCIe Gen4 x8 or something like that.
The other big, and perhaps more important, feature is that the card has a MTP/MPO-24 connector. If you saw our Guide to Indoor Fiber Optic Cable Color Coding or What is Plenum Fiber Optic Cable and What is OFNP pieces, you will have noticed we have a lot of MTP-12 cable that we are deploying now. MTP/MPO-24 is a 24 fiber per cable solution. For 300Gbps, one gets 24 fibers each running in one direction, or 12 bi-directional pairs. Each of these pairs is running at 25Gbps per direction giving us 300Gbps.
Those MTP/MPO-24 connectors split out into an optical box that re-configures the cables. We can see 24x green MTP/MPO connectors in the SHFL. One plugs 24x 24 fibers into this box and the fibers are “shuffled” so that there is a 25gbps pair between each system and another twelve machines. On the left we have 24x MTP-24 inputs for a total of 576 fibers from cards. On the right, we have nine black MTP connectors. Rockport takes half the fibers (576/2 = 288) and uses them for expansion ports. The right side uses black MTP-32 connectors as 288/9 = 32 and this fits neatly in a standard MTP-32 connector.

Instead of using switches, these optical boxes create connections between nodes. Each node can then be connected to many other systems.
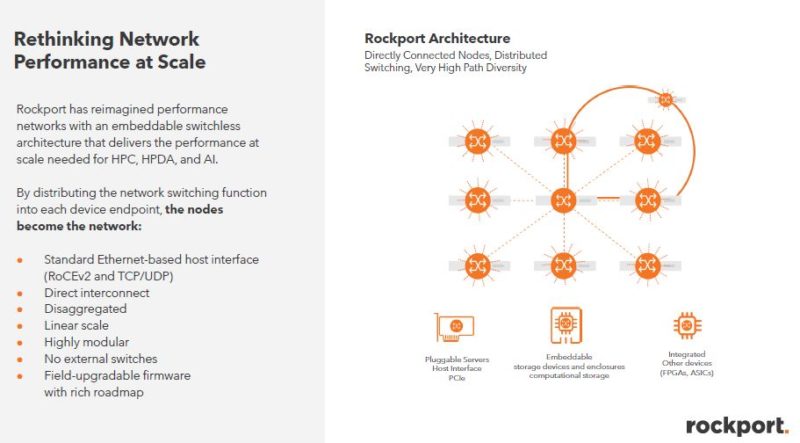
Part of making this work is the rNOS that helps bring up the network quickly. Rockport’s idea is that one can plug-in systems to the optical boxes and be up and running quickly.
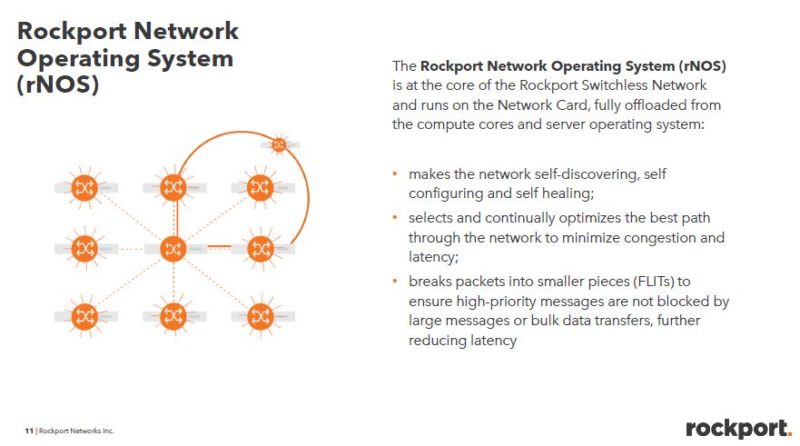
Rockport says that it can pull granular data from each node and ensure that there is monitoring to allow one to see performance bottlenecks.
In terms of performance and customers, the company has a number of workloads that it does not describe more than calling them HPC or AI workloads and showing a ~28% performance uplift. We typically do not show charts with that little behind them. The company says that TACC has some Frontera nodes using Rockport for testing.
Final Words
In terms of doing things that are interesting and new, this may be one to keep an eye on. The idea of removing switches from the network infrastructure should make other industries also look on with interest. The big question is, of course, pricing. Still, it is an interesting way to solve east-west traffic in data centers.



{kind=link}
Any drivers available in the Linux kernel?
Nils – they did not say which IC, but they are using a 3rd party Ethernet IC for the host interface so they get support out of box. They even have VMware support because of it.
This is interesting but I’m not sure it will scale, with essentially a mesh topology between 12 nodes what happens when larger cluster sizes are needed?
Probably easy to demo tech, but I don’t think they’ll be very successful with this. There are obvious advantages to switched networks when working at scale.
I’m wondering how much magic is involved in the SHFL, from the picture it looks entirely passive?
Come to think of it if one just splits the 100GBit/s connection into four 25GbE interfaces and puts them all in a bridge one would simply do switching on the hosts instead of a central component (needs spanning tree obviously). Interesting idea nonetheless. I was thinking of doing something like that at home to connect three systems with dual port 25GbE adapters.