
VMware Project Capitola was a star at VMworld 2021. The deep-dive session on the technology was great, and this is another technology that VMware needs to develop so it is one that we can certainly see getting mainstream support in the coming years. Project Capitola effectively allows automatic memory tiering both within a node, and then looking beyond a single node and into a cluster.
VMware Project Capitola
First off, Capitola is a beach town just to the south of VMware’s headquarters next to Santa Cruz, California. VMware’s other project we are following closely, VMware Project Monterey for DPUs is named after the town on the other side of the Monterey bay from Capitola. In a shameless plug, one of my childhood neighbors now runs a great taqueria near the beach there, Mijo’s Taqueria.

Capitola is a great town, so go check it out if you are around and say hi to Anthony one of my old neighbors.
VMware Project Capitola is addressing a memory hierarchy. Effectively, the closer memory is to a processor, the lower latency and higher bandwidth it is, but it can also cost more. VMware is using $16/GB and that seems very expensive. On the spot market, we have been buying DRAM in the $4-6/ GB range, but perhaps that makes it look less dramatic. Still, the general principle holds.
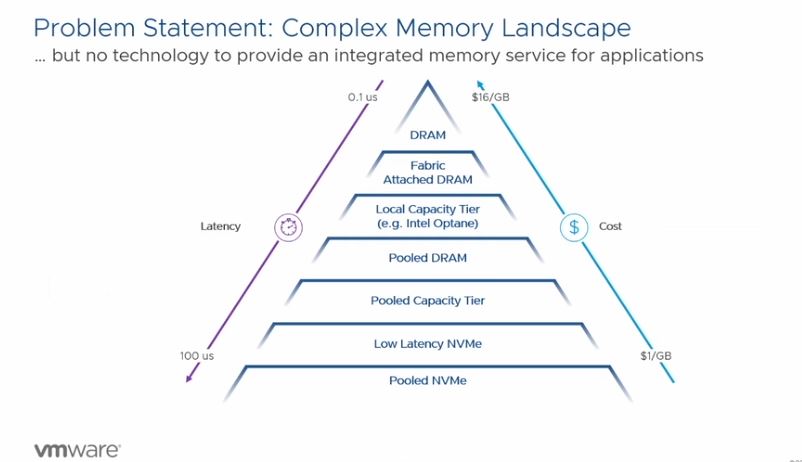
The basic goal of Project Capitola is to allow applications to place data in memory that is either attached directly to a CPU, or memory that resides elsewhere.

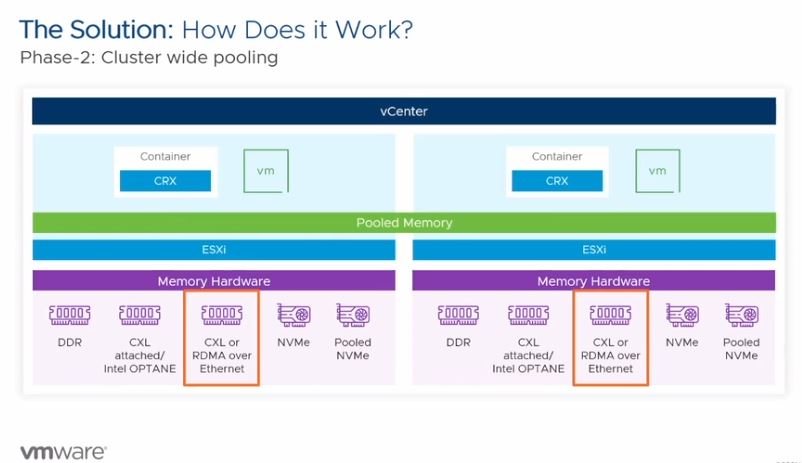
This has two major benefits. First, by using DRAM in pooled configurations at a cluster level, one can decrease the amount of local DRAM and increase utilization across a cluster. Just like virtualization helps drive higher CPU utilization, Project Capitola is driving higher DRAM utilization. The second benefit is that setting up automatic tiering and handling the resultant latency also enables using lower-cost media. Pooled DRAM is still bound by DRAM cost, but switching DRAM to NAND is a dramatic cost per GB savings.
Project Capitola’s goal is to make it seamless for VMware’s customers to opt into this lower-cost mode of operation and then manage where pages are placed for them, whether that is in main memory, NVMe, cluster memory, or elsewhere. Effectively, it needs to turn this into an “easy-mode” for doing something that is complex. The complexity involves monitoring and determining when data is hot and therefore needs to run on main memory or when it is colder and can run on a lower cost tier.
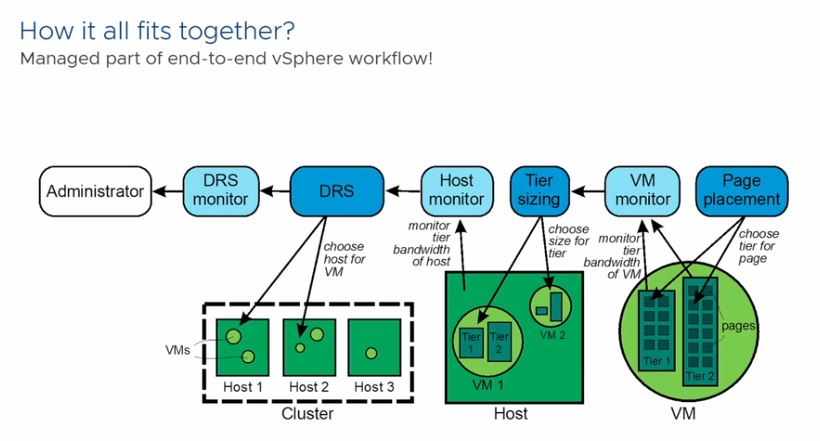
Clustered memory or NVMe-based solutions can be challenging for another reason. One has to monitor what happens to different components. For example, what happens if a network issue prevents RDMA access to clustered memory? What happens if a NVMe or CXL device is removed or fails in an array? These are the higher-level bits that VMware is in a unique position to solve for its customers.
Of course, this does come at a performance impact. VMware is using PMem here, and there is certainly a hit as pages move to non-DRAM solutions. Still, the argument is that at some point hitting acceptable performance at a lower cost is better. This is the Netflix streaming versus physical disk phenomenon being translated to DRAM.
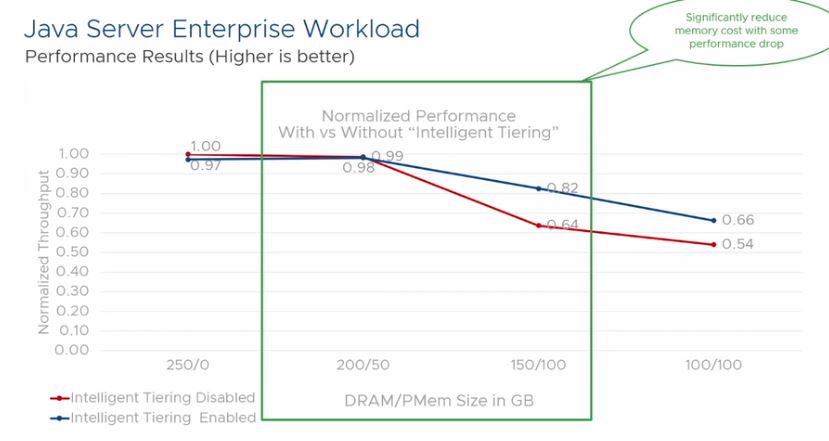
As one may imagine, there are cases where one would not want to enable tiering due to the potential performance impact, but there are also many applications where this is more than acceptable.
Final Words
For those wondering about the taco reference earlier in this piece, VMware is explicitly calling out CXL attached memory here. In our Compute Express Link or CXL What it is and Examples video, we used tacos.
Project Capitola using CXL memory. STH has a taco-based CXL primer and a friend in Capitola that runs a taqueria. If you do not believe in coincidences, then this is a good indication that this will be a big deal.
So let us be clear, this is not a new area. Large hyper-scalers were releasing papers about tiering memory pages years ago. For example, when we were at the Intel storage and memory event in Seoul South Korea covering topics like the Intel Optane DC Persistent Memory Module roadmap disclosure in 2019 those hyper-scaler papers were being discussed as a reason that pages could be moved from DRAM to Optane with minimal loss. If you want to learn more about Optane, you can check out our piece Glorious Complexity of Intel Optane DIMMs and Micron Exiting 3D XPoint and its video here:
Still, the open-source community that has commoditized virtualization needs to respond with mainline tools to VMware Project Capitola. This is an opportunity that is harder to manage By the same token, VMware needs to bring this capability to its customers as it is something that has been in production for years at some large organizations. At some point, we will see more public cloud offerings discuss a similar capability and VMware will need to respond. It is great to see VMware is already working on this. Project Capitola is undoubtedly an extremely exciting capability coming to the VMware ecosystem.



{kind=link}
Unless it’s somehow exposed to the operating system of virtual machines this sounds like something that can make debugging application performance issues extremely difficult once platform magically decides to move your memory somewhere else or you hit a range of virtual RAM that is mapped somewhere far away.
It’s really great to see that Vmware tries to align itself with the future CXL revolution.
I don’t know if they can make PMEM more viable for the mass market though.
As it is now Optane PMEM memory access is simply slow, and it kinda don’t address the problem we have with Intel.
We need more cores per CPU and we need these cores more performant, because right now Ice Lake with Barlow Pass will simply crumble with unacceptable performance under max load.
I’ve just read this https://lenovopress.com/lp1528.pdf and it’s hard for me to see it right now as a viable combination. OTOH considering Intel SPR is around the corner and the DDR5 prices will be much higher, we might see this Project as a great option to offload the nonprod workload from our precious DDR5 sticks.