
Qualcomm is still pushing into the data center, even after the Centriq 2400 ended up getting mothballed. Specifically, the new effort is taking some of the IP Qualcomm has built for the mobile market, and is applying that to higher-power data center inference cards. At Hot Chips 33, we get a glimpse into what Qualcomm is doing. As with other pieces, these are being done live, so please excuse typos.
Qualcomm Cloud AI 100 AI Inference Card at Hot Chips 33
The Qualcomm Cloud AI 100 is designed for inference, not for training. Something that will jump out at our readers is that there are two form factors for the Cloud AI 100. As we move into 2022, we are going to see some ecosystems still focus on things like M.2 cards while many will move to EDSFF as we covered in our E1 and E3 EDSFF to Take Over from M.2 and 2.5in.

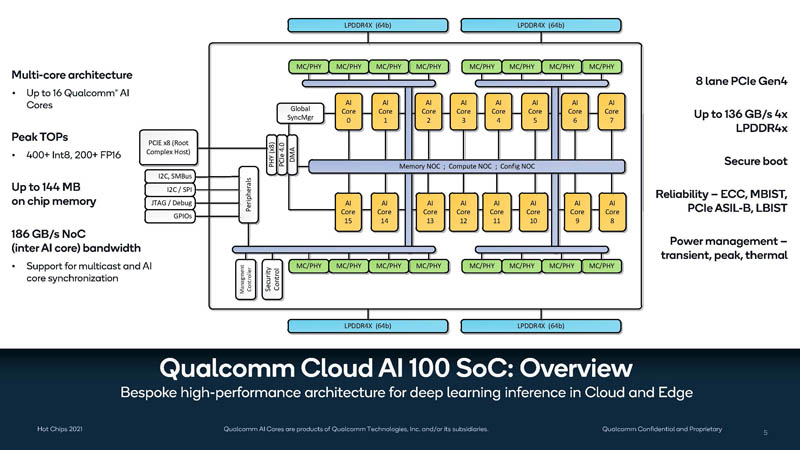
Here is the SoC overview. We can see a total of 16 Qualcomm AI cores with a NOC interconnect and 4x LPDDR4X landings. Another interesting feature is that this is a PCIe Gen4 x8 card.
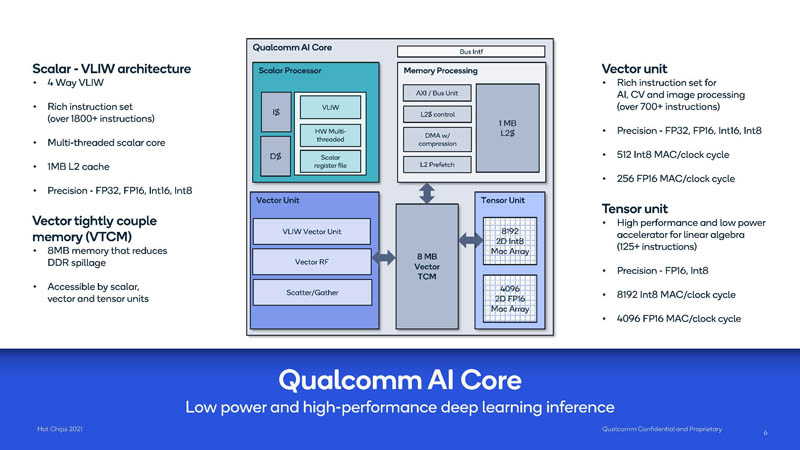
The AI core is a scalar 4-way VLIW architecture that includes vector/ tensor units and lower precision to enable high-performance inference.
Qualcomm has a number of power points it can run the chips at. The importance of this is that Qualcomm wants to make this a cloud and edge accelerator. Using 7nm and lowering clocks/ voltages mean that Qualcomm can get higher performance per watt as the power goes down.

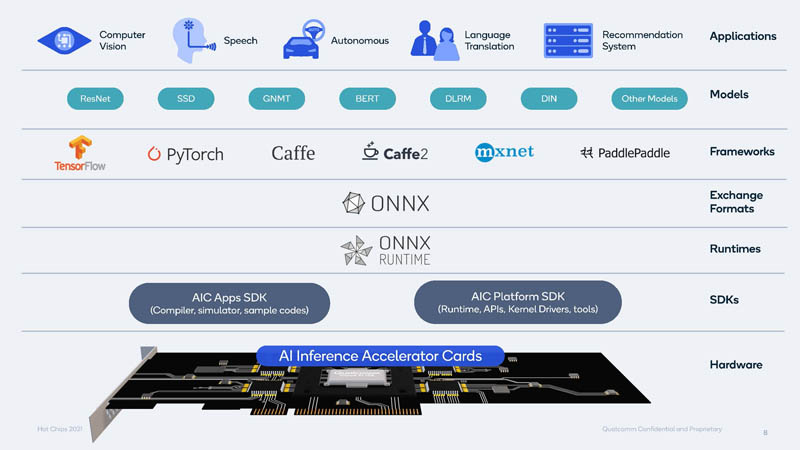
Qualcomm has SDKs supporting major frameworks. Our sense is that NVIDIA may have more folks working on their software side than Qualcomm so there is probably a sizable gap here.
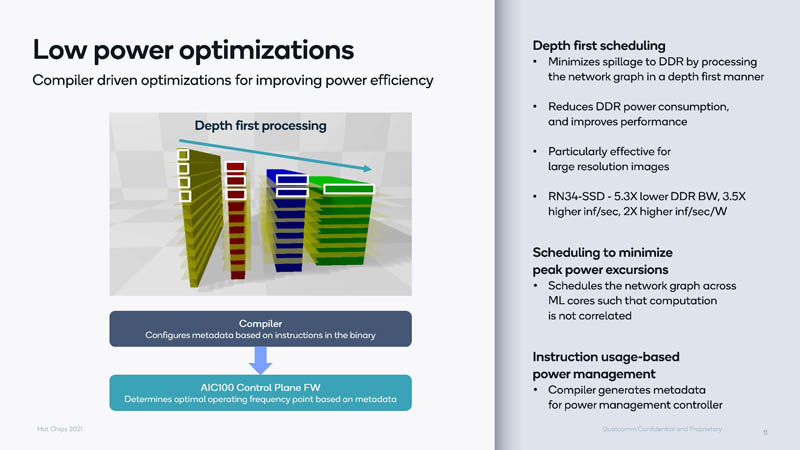
Part of the solution is a parallelizing compiler. The compiler helps inferencing compute go across the various AI cores.

We are not going to get into that too much, but the approach is heavily focused on lowering the power used by the accelerator to focus on performance per watt.
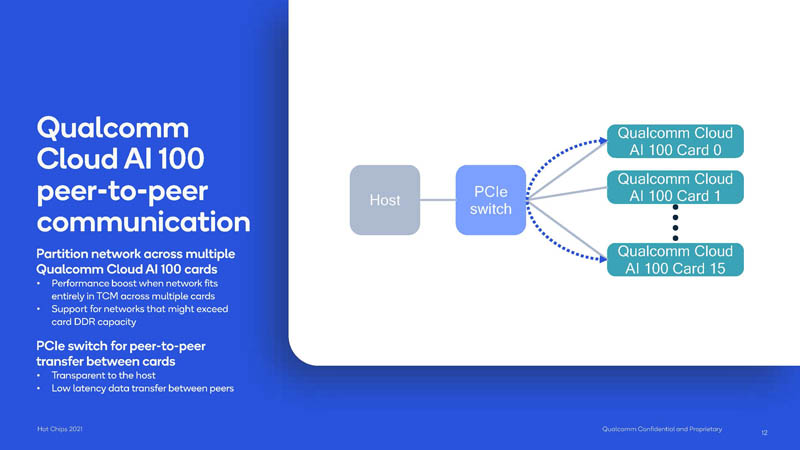
The Cloud AI 100 has a peer-to-peer communication capability. According to the talk, slide, and diagram, it seems to be enabled over a PCIe switch, similar to what we saw older NVIDIA GPUs focus on. That leads to our Single Root v Dual Root for Deep Learning GPU to GPU Systems years ago. Now, NVIDIA shops will focus on NVLink topologies. NVLink, however, is not really relevant in the inference space. There, PCIe is more prevalent.
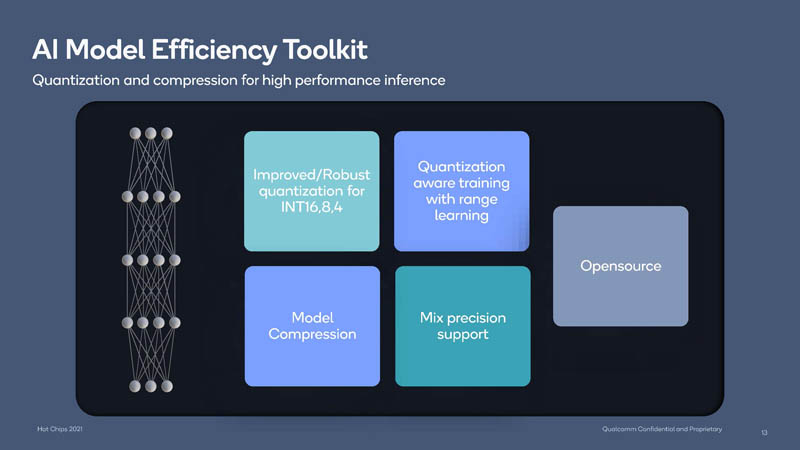
AIMET is designed to increase efficiency for the inferencing process and Qualcomm says it is open source.
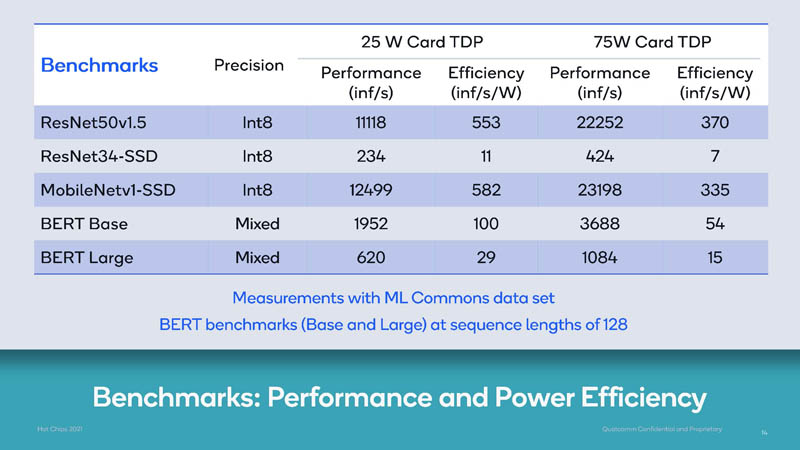
Here is the first benchmark slide Qualcomm showed using both 75W (data center/ server) and 25W (edge) card TDPs.
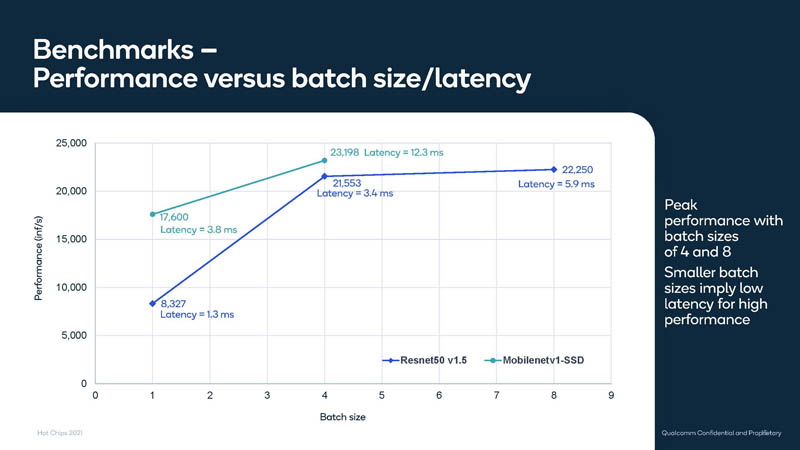
Here is a look at batch size versus latency. Increasing batch size often leads to increased latency. Inference is often very latency-sensitive.
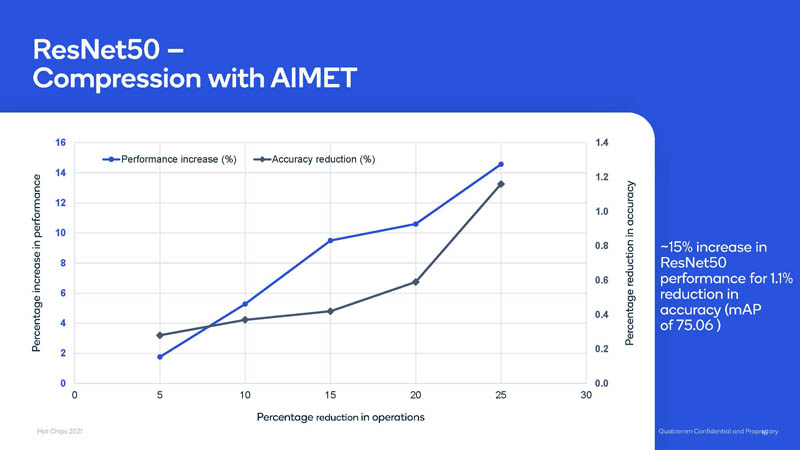
Here is a look at the AIMET optimization using compression and ResNet-50 where Qualcomm gets 15% better performance at a 1.1% loss in accuracy.
Although Qualcomm calls this the Cloud AI 100 a “Cloud” accelerator, it is also designed for the edge. Here it is paired with a Snapdragon 865 for an edge deployment in one photo. There is also a photo of a Gigabyte server we have not reviewed, the G292-Z43. This appears to be a dual AMD EPYC server with four side pods. Each side pod has four PCIe x8 slots instead of two dual width x16 slots that we normally see this style of server deployed with. That gives sixteen accelerator cards in total.

It is good to see more on the progress of this chip.
Final Words
Qualcomm is a big company, but it does not necessarily have as dominant a position in the data center market as it does in the mobile market. This is an example of a company trying to leverage the low-power AI acceleration that it developed and move it up-market to lower quantity/ higher value segments. It will be interesting to hear how this is adopted.



{kind=link}