
One of the biggest topics coming to the server industry in 2022 will be Compute Express Link or CXL. We started covering CXL when it was first announced in 2019. The project went from an Intel effort to a broad industry consortium and is simply where the industry will head as we enter the 2022 PCIe Gen5 era. Still, there are many who do not necessarily understand CXL, so we are going to try explaining CXL using an easy visual example: limes.
A Video Version
Since we are going to be talking about CXL for years to come, we have a video version of this piece that you can find here.
As always, we suggest opening this in a YouTube tab/ window for a better viewing experience.
The Quick: What is CXL? Answer
Compute Express Link is a cache-coherent link meant to help systems, especially those with accelerators, operate more efficiently. CXL sits atop the PCIe Gen5 link infrastructure. There can be PCIe Gen5 devices, but many PCIe Gen5 (or PCIe 5.0) devices will also support the ability to run lanes in either PCIe or CXL modes. In some ways, this is analogous to how AMD EPYC CPUs can run their I/O lanes as either PCIe or as Infinity Fabric. Instead of being a vendor-specific implementation, this is going to be a broad industry standard. The key advantage of CXL is it allows load/ stores to happen to memory that is directly attached to different endpoints which is what we are going to get into next.

We are going to focus a lot on memory here. Memory is a key driver for this as hyper-scalers realized that almost every device these days has onboard memory, and memory both is a large cost driver and also is often stranded by being under-utilized by the device it is attached to. At a higher level, CXL is a tool for systems to efficiently share and utilize memory across a number of devices. We are discussing these in the context of servers today, but there is no reason it cannot be applied beyond servers.
Why is CXL not used in the PCIe Gen3/ Gen4 era?
There are a few reasons that we are waiting until PCIe 5.0 for CXL. The first is simply timing. CXL was going from introduction to adoption in 2019 which means late 2021 and early 2022 are really the first generations of chips that we expect to see support in. These things take time.
A key enabler though is the rapid adoption of PCIe Gen5. It took the industry around seven years to transition from PCIe Gen3 to Gen4. The PCIe Gen5 transition is occurring about 3 years after Gen4. This massive increase in speed effectively doubles the bandwidth of PCIe Gen4 with Gen5. Since CXL sits atop PCIe Gen5 we generally see a controller with a 32GT/s x16 link but CXL can also support bifurcation to x8 and x4. There are modes to go into x2 and x1 links in what is called “Degraded” mode. It is important to remember that a PCIe Gen5 x4 link has enough bandwidth to handle a 100GbE link so that starting level represents a large amount of bandwidth that was akin to a PCIe Gen3 x16 link that Intel still used as a top-end connectivity option in Q1 2021.

The additional bandwidth means that PCIe will have enough bandwidth to handle a new class of use cases, specifically for those involving remote memory load/stores that previous generations were not fast enough to handle.
For those wondering why did this not happen sooner, there are three main reasons. First, we needed the speed of PCIe Gen5. Second, we needed CXL to be created. Third, it then takes time for industry adoption to occur. Now that we have all three, CXL is the future.
Compute Express Link Protocol Trifecta
CXL uses three main protocols:
- CXL.io is the protocol used for initialization, link-up, device discovery and enumeration, and register access. It provides a non-coherent load/store interface for I/O devices and is similar to PCIe Gen5. It also is mandatory that CXL devices support CXL.io.
- CXL.cache is the protocol that defines interactions between a Host (usually a CPU) and Device (such as a CXL memory module or accelerator. This allows attached CXL Devices to cache Host memory with low latency. Think of this as a GPU directly caching data stored in the CPU’s memory.
- CXL.memory / CXL.mem is the protocol that provides a Host processor (usually a CPU) with direct access to Device-attached memory using load/ store commands. Think of this as the CPU using a dedicated storage-class memory Device or using the memory found on a GPU/ accelerator Device.
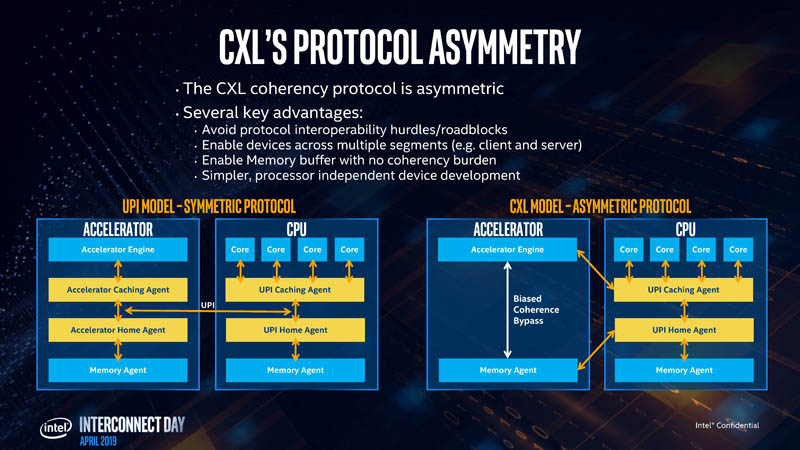
CXL.io is mandatory to get an endpoint on CXL, but from there we can have CXL.io and any of the three combinations of CXL.cache and/or CXL.mem. The CXL folks use Type 1 (CXL.io + CXL.cache), Type 2 (all three), and Type 3 (CXL.io + CXL.mem) as examples.
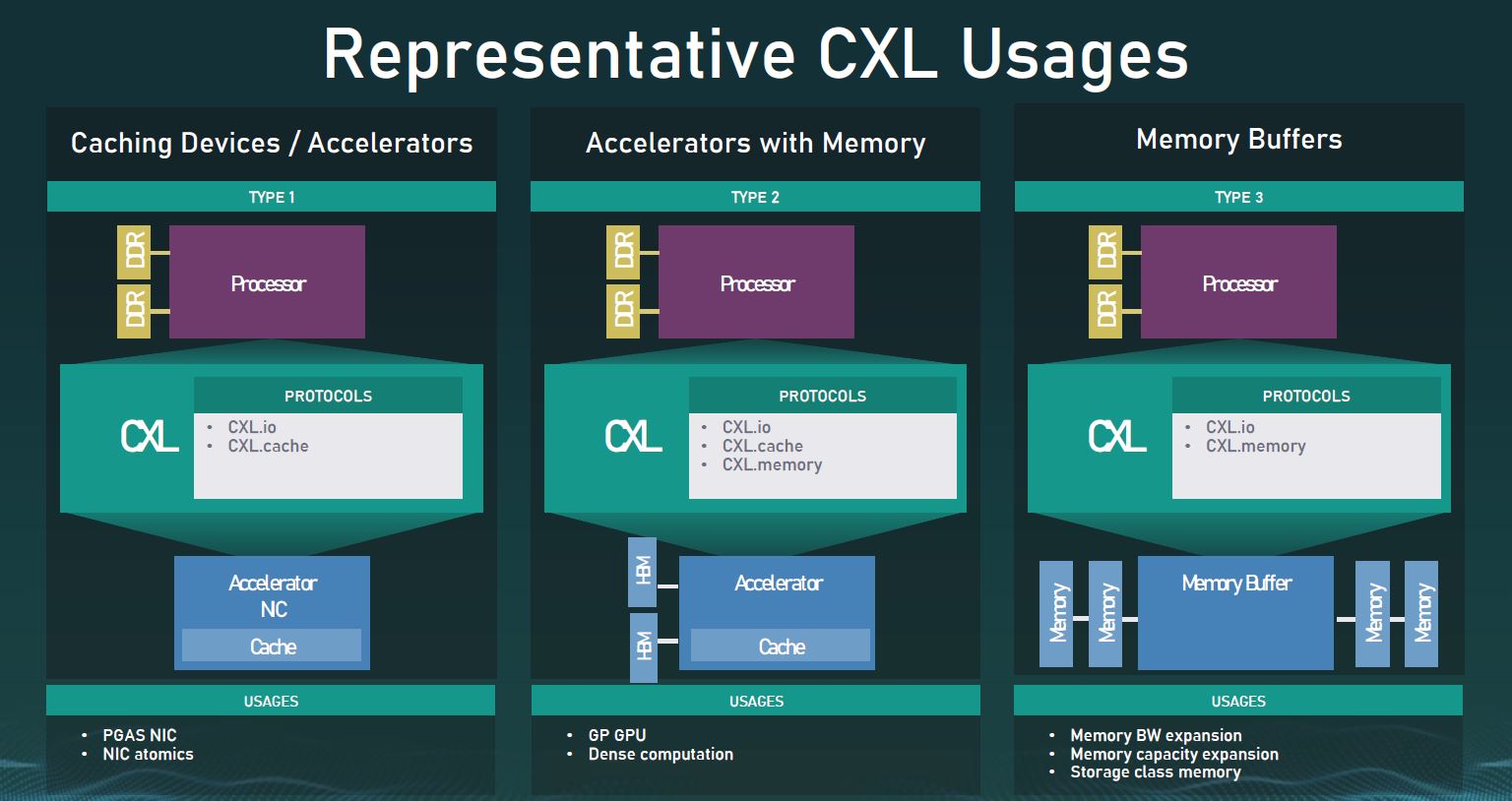
Type 1 one can think of as an accelerator like a NIC that accesses the host CPU’s memory directly. Type 2 is a case where we have an accelerator, like a GPU with memory, and the GPU can access host memory while the host CPU can access GPU memory. Type 3 one can think of as a memory module where its primary purpose is to expose the CXL memory device’s media to the host CPU.
CXL 1.1 v. 2.0
Most of the early 2022 devices we will see will utilize CXL 1.1. These are still primarily host CPU managed topologies where CXL is used within a system. CXL 2.0 is where we get really interesting use cases. With CXL 2.0 we get CXL switching. CXL switching and pooling allows multiple hosts and multiple devices to be connected to a switch and then devices can be assigned as either complete or as a logical device to different hosts. CXL 2.0 is where we will start to see the game-changing deployment scenarios.
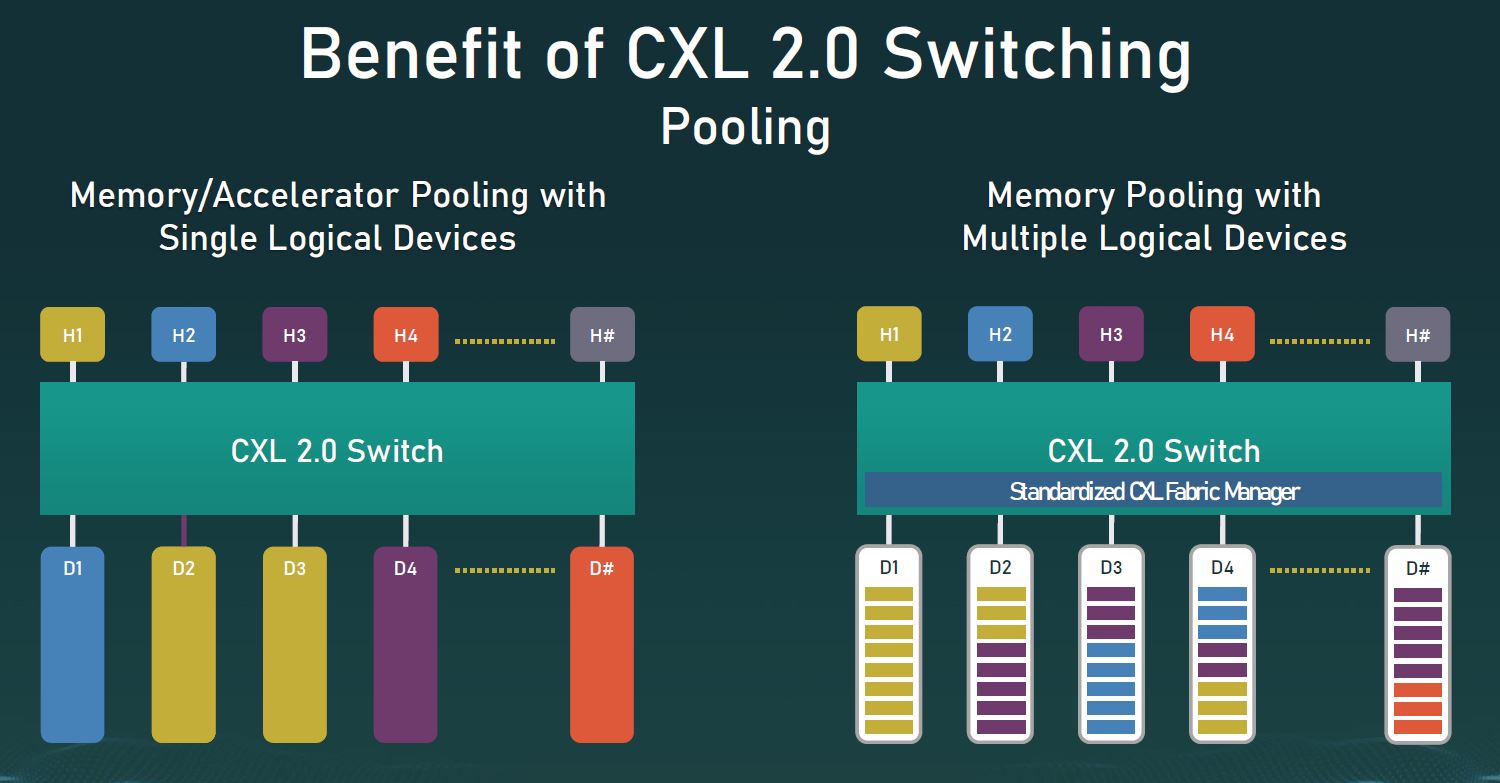
Beyond CXL 2.0 switching and pooling, we get additional security layers to the protocol.

While CXL 1.0/ 1.1 will be big to start the initiative, CXL 2.0 is where we start to see truly game-changing functionality shifts. This is primarily because we get to start changing how server architectures and deployments happen. CXL 1.1 is necessary, and there are use cases especially with accelerators and GPUs. CXL 2.0 though is where hopefully we have enough software maturity that server designs change forever.
Next, we are going to discuss some examples and use our tacos and limes to help those who have difficulty visualizing on slides some common types of CXL usage.



{kind=link}
Business expensing tacos is the best.
Also, I’ll be curious what adoption of CXL looks like at the SMB level. Where as virtualization was a pretty easy sell, I’m not sure the consolidation/ flexibility will make sense without a fork-lift upgrade to an environment. I suppose it also depends on what hypervisor support looks like, too.
How do you see the adoption of CXL being shaped by latency concerns?
I can definitely see a lot of scenarios where having a nice standardized interface for assorted peripherals to either borrow main memory so they don’t have to ship with enough onboard for their worst-case scenarios; as well as the cases where being able to scavenge unused RAM from peripherals that have it, or other systems, when it would otherwise be idle is certainly useful (I assume that CXL also makes doing very large unified memory space clusters a relatively standardized configuration rather than something one of the small number of specialty supercomputer shops with custom fabrics can hook you up with); but I’m also thinking of all the situations where RAM gets placed on peripherals because the alternative is much worse performance(eg. GPUs currently have various ad-hoc arrangements for stealing main memory; but the ones that are actually any good have GDDR or HBM really close to the GPU on a very fast bus because that turns out to be a fairly major bottleneck otherwise; Intel’s attempts to tack a serial bus onto DIMMs to make trace routing less of a nightmare foundered on cost, power consumption; and latency issues; first-gen Epyc got a slightly frosty reception because of its NUMA peculiarities; the slightly crazy Cerebras guys found that putting multiple gigs of RAM on-die to be a good use of space; and back in common-and-affordable land Package-on-Package with RAM stacked on CPU seems to be very popular).
Given that, at contemporary speeds, latency quickly becomes a physics problem rather than just a memory controller deficiency(convenient rule of thumb is that at 1GHz, under ideal speed of light conditions, your signal can only travel 300mm per clock; if your medium is less than ideal, your implementation introduces delays, or your clock speeds are higher you can get substantially less distance per clock than that); it will simply be the case that CXL-accessed RAM has the potential to be anywhere between ‘not much worse than having to access RAM on the other CPU socket’ to ‘massive latency by DRAM standards’.
Is the expectation that, even with a cool relatively agnostic fabric to play with people will keep most of the RAM close to most of the compute; with some “it’s better than leaving it idle…” scavenging of idle RAM from more distant locations; or is there a sufficiently large class of applications where latency is either not a huge deal; or a small enough deal that spending way less on RAM makes it worthwhile to endure performance penalties?
Where is the tequila though?
> “Most of the early 2022 devices we will see will utilize CXL 1.1.”.
I think we can go directly to 2.0:
https://www.synopsys.com/designware-ip/interface-ip/cxl.html https://www.plda.com/products/xpresslink-controller-ip-cxl-2011
Hanging back at 1.0/1.1 is going to defeat early adoption, knowing that 2.0 is ready and PCIe 6.0 is dropping RSN.
Rob but Sapphire and Genoa are 1.1 aren’t they?
What about latency?
@QuinnN77 the best non-rumor information that I could find about Sapphire is that the CPU being tested is an engineering sample, with 4 cores running at 1.3 GHz and supports CXL 1.1. Less rumor is that Sapphire Rapids will support 1.1 in its final form, source: https://en.wikipedia.org/wiki/Sapphire_Rapids (amongst others, not for the weak of heart: https://www.techspot.com/news/89515-violent-delidding-reveals-intel-sapphire-rapids-cpus-could.html).
There’s no non-rumor info about Genoa and its supported CXL level.
CXL 2.0 adds switching capabilities, encryption, and support for persistent memory; so there’s a reason for both AMD and Intel to prefer it over CXL 1.1.
—
@Ekke, as for latency it’s above 100 ns with persistent memory, otherwise around 10 ms (plus). There are CXL 2.0 chipsets available for sampling to motherboard manufacturers, so it’s not as though everything isn’t ready and available.
Sources:
https://www.nextplatform.com/2021/02/03/pci-express-5-0-the-unintended-but-formidable-datacenter-interconnect/
https://www.anandtech.com/show/16227/compute-express-link-cxl-2-0-switching-pmem-security
https://www.microchip.com/pressreleasepage/microchip-leadership-data-center-connectivity-lowest-latency-pcie-5.0-cxl-2.0-retimers
I still think Optane/3DXP/QuantX has multiple uses and don’t want to see it die or become proprietary tech.
I can envisage Optane being used in a OMI like Serialized (Main Memory + Optane) DIMM on one PCB with DMA allowed between Optane + Main Memory, imagine how much faster and lower latency data transfer could be between the OS and RAM is the OS existed on Optane along with all the basic applications needed and transferred directly to the local RAM modules on the same DIMM.
The distance that needs to be traveled after getting the “Go Signal” from the CPU is much shorter than a M.2 drive located on the MoBo to RAM.
That could help improve performance signifcantly.
Same with RAID Controllers / HBA adapters.
Instead of using traditional low end ram, Optane can literally replace the DRAM cache or coexist with a small amount of DRAM cache on the controller cards and allow ALOT more Low Latency cache to whatever HDD or SSD is attached to the end of the controller.
Optane could also exist as a form of Low Latency “Game Drive” where the installation of the Game can be on a M.2 drive attached to the GPU directly and you BiFuricate the GPU to be 12x/4x with the GPU getting 12x while the Storage gets 4x.
Then you can have ultra low latency for DMA directly from the “Game Drive” to VRAM.
Good sharing..! if you are looking for gaming accessories then you should contact Flyingshiba online platform. Find everything about gaming accessories like cronusmax, cronuszen, strike pack Xbox and ps4 and much more here