
Perhaps one of the technologies we are most excited about is the Ethernet SSD. Toshiba (now Kioxia) and Marvell have been showing concept devices for years. Now, the Kioxia Ethernet SSD is becoming a reality and is sampling to certain customers and partners. That may not be the general availability announcement we are eagerly awaiting, but it is very exciting as a next step. Kioxia has seen enough interest in the product to continue development toward commercialization.
Kioxia Ethernet SSD Background
The concept is relatively simple and is something that we are seeing multiple companies attack from different angles. In the industry, there is a growing question with technologies such as NVMeoF becoming both viable and popular, of whether flash storage needs to be directly attached to x86 nodes. Some SmartNICs have the capability to run NVMeoF stacks on the NIC since it is relatively lightweight, and can use PCIe Peer-to-Peer transfers to directly access storage in the same system. We see devices such as the Mellanox Bluefield-2 line, Fungible F1 DPU, and Pensando Distributed Services Architecture SmartNIC feature ways to directly get multiple SSDs connected to an Arm/MIPS based device and then exposed to the network directly, even without an x86 host.

Kioxia and Marvell have been working on a different strategy. Instead of going through an intermediary processor, the host interface on each drive can be Ethernet instead of PCIe. Indeed, PCIe Gen3 x4 is about equivalent in bandwidth to a 25GbE lane so the ratios make sense. The key to making this work is Marvell’s 88SN2400 controller. Marvell’s controller allows SSDs to be placed on the network directly as NVMeoF targets.
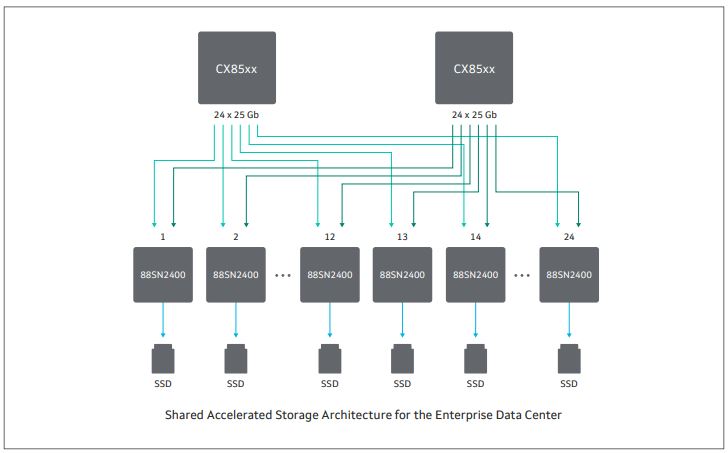
As you can see, each SSD gets two paths to two different switches allowing high-availability connectivity to each device, similar to what we would get in a traditional SAS storage array. Marvell (and Kioxia) have shown off the solution with Marvell network switches to handle the links. One can see the eight QSFP28 connectors on the rear of the chassis shown below. This allows full bandwidth outside of the chassis.

In 2018, this product concept was a SSD with an external board attached to the standard SSD’s 2.5″ connector. By FMS 2019, the controller was integrated directly into the SSD itself. Here we can see the Kioxia Ethernet SSD (formerly Toshiba) with an integrated controlled and output directly to pluggable cages.

Either built into a high-availability chassis or with a more direct to network design, each SSD can be added as a network endpoint and provide NVMeoF targets.

The fact that this solution is moving to customer/ partner sampling is a good sign.
Highlights From the Press Release
Here are some of the Ethernet bunch of flash (EBOF) and Kioxia Ethernet SSD highlights from the press release:
EBOF System Highlights:
- Simpler EBOF design with KIOXIA Ethernet SSD connecting directly to the embedded Ethernet switch inside EBOF
- Available EBOF 2U systems can connect up to 24 KIOXIA Ethernet SSDs with up to total 600 gigabits per second (Gbps) storage throughput
- Each system supports 2.4 terabits per second (Tb/s) of connectivity throughput which can be split between network connectivity and daisy-chaining additional EBOFs
- High performance: 670K IOPS per drive, over 16M IOPS per 24 bay EBOF (@4KB random read)
- Runs Marvell EBOF SDK, leveraging the SONiC network operating system and enabling advanced discovery and management functions
KIOXIA’s new drives incorporate the Marvell® NVMe-oF™ Ethernet SSD converter controllers into its enterprise NVMeTM SSDs, bypassing the requirement for an external Ethernet to NVMe bridge adapter.
KIOXIA Ethernet SSD Features:
- Support for single or dual 25Gb Ethernet and RoCEv2 RDMA connection
- NVMe-oF 1.1 and NVMe 1.4 compliance
- 2.5-inch1 15-millimeter (mm) Z-height form factor
- Capacities supported: 1920/3840/7680 GB
- Two-die failure recovery and other reliability features
- Support for Redfish® and NVMe-MI™ storage management specifications
- Support for IPv4 and IPv6 architecture
(Source: Kioxia)
Final Words
If we go beyond today’s announcement and look to the future, this is very powerful. Instead of a NVMe SSD going through an x86 server’s PCIe lanes, and potentially PCIe switches, to the network, or a SAS SSD traversing SAS switches to an x86 server’s PCIe lanes to the network, the NVMe SSD itself can have an IPv6 address. Multiple services can use RoCEv2 to get high-speed access over the network using standard Ethernet gear. This greatly simplifies design since there are fewer hops and different interfaces being traversed in an Ethernet SSD solution.
In an NVMeoF solution like this, one part is the hardware, but the other is the software enablement. Kioxia has been working on its Kumoscale NVMeoF software solution to address that side of the equation.
We still have not been able to get one of these SSDs, or even the Marvell PCIe to 25GbE adapter, but we are holding out hope that we can show this off one day.



{kind=link}
Maybe mention what NVMeoF actually is and why we’d want it?
NVMeoF == NVMe over Fabric
Allows for NVMe storage to be treated as a pool of storage to be used by multiple hosts. So, instead of having NVMe SSDs in each host system (and purchase systems/chassis to support same) you can now have high speed storage as a network resource.
This is all part of the disaggregation of large systems, into building blocks.
IBM’s recent Power10 announcement refers to another path to disaggregation; “RAM over fabric” where RAM intensive chassis can be connected to multiple hosts.
Man, those Aztecs sure do understand flash. They’re way ahead of the Koreans and Japanese!
I’ve always loved this idea…it’s like Ceph? So many questions from a systems/software standpoint.
Object storage? Or iscsi? Obviously you don’t want SMB or NFS because that implies some processing on the drives…though I suppose you could, there’s a bit of an IoT like security concern on that type of thing.
Over fabric implies Broadcast/Multicast…but ipv6 could route, and then security concerns come into play. If it’s object storage and we don’t have security domains, then the network shouldn’t route.
Infiniband with the lower latency might be preferred, but that’s now an Nvidia concern too.
PoE switching for a cleaner datacenter install?
We gotta be thinking that Nvidia will have GPU’s on fabric soon…that’s the Mellanox tie-in….and then will we care about how many PCIE lanes exist on a server? Enough to get the bandwidth you need out of the CPU’s…and you won’t care so much about arch then either. Switching power then becomes what everyone cares about, and the switches become the security gatekeepers.
MDF
Object storage or SQL – iSCSI is a network protocol – it’s like SCSI over Fabric. Object Storage and SQL are ways to store and access data on a database.
For all intents and function this is like a 1 bay NAS – instead of connecting to USB or eSATA it connects to Ethernet – it’s not complicated. This will be a datacenter tech and I would be surprised to ever see this as a consumer tech. Most likely you will see this in EMC and other SAN products.
Whether Mellanox IB is Nvidia or not in irrelevant – Infiniband is losing market share badly to Ethernet – IB is lower latency, but the overall network is Ethernet. I just spent almost $30K to convert the 8x40Gb/s Infiniband on my SGI TP16000 Array to 8x40Gb/s Ethernet – and then to the wider 100/400Gb/s backbone.
PoE switching? Do you know what any of these terms mean?
Nvidia already has GPU on fabrics – the fabric is NVLink/NVSwitch and has been deployed in the DGX series – it is what separates the DGX from a server with 8 PCIe GPUs.
Why the animosity?
I know what iSCSI is, I’m trying to understand what this Kioxa product would become. A NAS is capable of doing iSCSI and SMB but not object storage (in most cases). I want to know what these are intending to do. iSCSI is just fine, they’re saying this could be ipv6… so not far fetched to consider an iSCSI on this.
100-400gb IB does exist but ethernet is the larger market. IPoIB is not fun to configure. So I get it, that’s the market. IB is now wierd cuz Nvidia.
If this product is NVMe over ethernet, why wouldn’t I power it over that? I DO know what it means, do you not imagine the possiblities? I’d like to see a setup: 2x poe switches into a bunch of these SSD’s …and object orient storage means application will need to be written for the redundancy of the storage unless it’s something like ceph and that’s the questions I have about something like this. You could have a pair of 48x 25gb poe, powering these ssds, and 4x 100gb uplinks. EMC would put this together as some expensive package that will look like some crusty old server design even if it’s ethernet. I’m more interested in the non-EMC solutions around this, where we address our storage over the network without a “server”.
Don’t you think that NVLink is going to get out of the server and onto infiniband (or ethernet) direct? That’s what I’m getting at. NVLink itself is a switched network, yes, but it’s always in a server, even if the data is transmitted not over PCIE but NVLINK. I’ve never seen NVlink across racks, or across datacenters, have you? I expect that Nvidia will do this over infiniband without a CPU in the middle. DGX is 16 gpu’s woohoo… I’m thinking of 100 GPU’s without a PCIE bus in sight, switched over distance, not in a chassis. GPU’s with the network on the card, no x86, no arm. What does a datacenter look like when the switching is LAN not PCIE?
This is more like a forum post, sorry folks.
I think this would even make sense for spinning disk. SAS cabling a 100+ disk JBODs are a pain. A couple of 400Gb DACs and you would be done. Also having the benefit of access from whatever server that is connected to the network is a big thing.
Don’t how much extra cost it would be, but 5Gb to the disks would be enougth.
@MDF it is just slabs of blocks like iSCSI. It would show up in the ‘client’ machine as a block device that you could partition and format and then mount. Or if you have s/w that can use raw block devices then you can do that too.
@MDF – to be more clear: it is +/- tunneling NVMe protocol over Ethernet, I assume further it exploits RDMA for performance if it can.
Think of it as canned NVMEoF.